


Предлагаю обсуждать здесь задачи прошедшего Гран-При.
Как решать D? Неужели все кодили эти жуткие шизофренические алгоритмы с экспонентой меньше 2k?
Как решать G? Глядя на то, как её сдавали на первом часу, кажется, что мы совсем отупели :(
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | ecnerwala | 3649 |
| 2 | Benq | 3581 |
| 3 | orzdevinwang | 3570 |
| 4 | Geothermal | 3569 |
| 4 | cnnfls_csy | 3569 |
| 6 | tourist | 3565 |
| 7 | maroonrk | 3531 |
| 8 | Radewoosh | 3521 |
| 9 | Um_nik | 3482 |
| 10 | jiangly | 3468 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | maomao90 | 174 |
| 2 | awoo | 164 |
| 3 | adamant | 161 |
| 4 | TheScrasse | 159 |
| 5 | nor | 158 |
| 6 | maroonrk | 156 |
| 7 | -is-this-fft- | 152 |
| 8 | SecondThread | 147 |
| 9 | orz | 146 |
| 10 | pajenegod | 145 |
Предлагаю обсуждать здесь задачи прошедшего Гран-При.
Как решать D? Неужели все кодили эти жуткие шизофренические алгоритмы с экспонентой меньше 2k?
Как решать G? Глядя на то, как её сдавали на первом часу, кажется, что мы совсем отупели :(







G: если ребра a > b нет, то ответ — кратчайший путь в графе, где веса ребер — стоимость перевозки потока. Если есть, то можно перебрать проходящий через него поток, точки, где нити потока расходятся и сходятся.
Хм, что за "точки, где нити потока расходятся и сходятся"? Оно что, всегда имеет вид "путь1, путь2", возможно имеющие общий префикс и суффикс? Если так — то это не интересно... Я-то думал, что тут что-то крутое есть.
Да, вид всегда не более двух путей, легко доказывается перекидыванием потока
как решать I и J?
I — написать persistent дерево интервалов. J — выкинуть все дуги, не лежащие на циклах, + из каждой компоненты сильной связности размера n выкинуть n - 1 дугу. Строго доказывать не умею, проверить сабмитом оказалось проще.
Ну в I нужно очень аккуратно так, чтобы не создавалось ни одной лишней вершины. У нас решение на макстесте съедало 264 mb.
А можно сделать за O(M) памяти и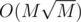 времени:
времени:
Отсортируем все запросы первого типа по значениям. Далее будем идти по ним блоками по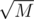 и строить для текущего блока массив частичных сумм, после чего для любого отрезка можно узнать количество чисел, которые были доданы на нем в этом блоке за O(1). Когда для какого-то запроса второго типа видно, что ответ в этом блоке — ищем его отдельно (полным проходом по блоку).
и строить для текущего блока массив частичных сумм, после чего для любого отрезка можно узнать количество чисел, которые были доданы на нем в этом блоке за O(1). Когда для какого-то запроса второго типа видно, что ответ в этом блоке — ищем его отдельно (полным проходом по блоку).
По J: Название четкое "Restoring the tree", а решать можно так: забьем на ориентацию ребер, тогда ответ это ans = m - n + comp, где comp — число компонент связности в этом графе.
А можешь код I показать? У нас был TL, что-то пооптимизили с 2.6 до 2.3 локально, получили ОК.
Решение такое: сжали все координаты. Отсортировали добавления по значениям. Делаем персистентное дерево отрезков, которое хранит количество чисел <= текущего значения в таком-то массиве. Пробежались по добавлениям, теперь можем узнать количество чисел <= данного на любом отрезке массивов за логарифм. На запрос отвечаем при помощи бинпоиска.
Еще был придуман оптимайз с памяти до линии по мотивам одной задачи с Варшавского контеста: выполняем все бинпоиски параллельно. Тогда у нас есть Q запросов, их можно отсортировать и обычным деревом отрезков с двумя указателями выполнить одновременно с добавлениями. Итого
памяти до линии по мотивам одной задачи с Варшавского контеста: выполняем все бинпоиски параллельно. Тогда у нас есть Q запросов, их можно отсортировать и обычным деревом отрезков с двумя указателями выполнить одновременно с добавлениями. Итого  итераций, каждая за
итераций, каждая за  , но линейная память.
, но линейная память.
Код (писал Jacob).
Хорошо вам. У нас на Java зашло (в дорешивании) только после того, как мы переписали на http://petr-mitrichev.blogspot.ru/2013/05/fenwick-tree-range-updates.html . На контесте пихали-пихали, но не упихали.
Впрочем, pashka потом придумал, как делать за O(nlogn). Остаётся надеяться, что это и было авторским решением, а С++-шники случайно просочились :)
Такой Фенвик должен быть в каждом CHelper-e.
Используя его или дерево отрезков с таким же трюком, можно поддерживать такие же операции на многомерном массиве.
А еще можно реализовать это же, избавившись от операции вычитания, и тогда можно поддерживать и запросы, где вместо + и +=, например, min и <?=
А как это обобщается на <?= ?
Ни фига себе. Вот это по-настоящему круто!!!
Если я правильно понял, то подобная модификация дерева Фенвика три месяца назад была на Хабре: http://habrahabr.ru/post/170933/
Да, но ты не Петя :(...
J: Есть M неизвестных — величины потока, протекающего по каждому ребру. Для каждой вершины составляем уравнение того, что величина потока, входящего в эту вершину, равна величине потока, исходящего из этой вершины. Получаем матрицу N*M, находим ее ранг r, ответ ans = (M — (N — r)).
Неужели это заходит? Гаусс на матрице 3000x500, мало того что не ТЛится, так ещё и с точностью всё хорошо?
0) Матрица скорее 500*3000 1) Изначально в матрице 6000 ненулевых ячеек 2) Изначально в матрице в ячейке либо 0, либо +1/-1 (входящее/исходящее ребро) 3) Все делалось в целых числах.
Хмм, так это всё ведь только изначально. "Всё делалось в целых числах" — это ещё удивительнее; как же оно смогло не переполниться?
Видимо, Гаусс на такой специфичной матрице делает что-то разумное, вроде dfs'а; однако априори — совсем непонятно, с чего ему работать.
Там интересная штука выполняется, что в любой момент времени в любой колонке либо все 0, либо один раз +1, либо встречается +1 и -1 по одному разу. Поэтому на деле на каждой итерации Гаусса выполнится только одно вычитание строчки:)
J: докажем, что ответ на задачу m — n + количество компонент сильной связности, иначе говоря в каждой компоненте сильной связности можно оставить какое-нибудь остовное дерево и для него мы можем не знать велечины потока, по этим ребрам протекающие, а величину потока по всем остальным ребрам мы знать обязаны.
Необходимость(то что более чем n-1 оставлять мы не имеем право): Пусть в какой-либо КСС мы оставили n и более ребер — тогда образуется либо цикл, либо для какой-либо пары v1, v2 два пути из v1 в v2. По циклу мы можем пустить произвольный поток(и мы этот поток не вычислим), и по двум путям аналогично. Необходимость доказана.
Достаточность(то что оставить остовное дерево можно): докажем по индукции. Раз у наc дерево -> есть лист -> одно ребро, а так же известна величина потока в эту вершину, следовательно можно узнать поток по ребру. Удалим эту вершину и это ребро(мы определили поток по ним) и сведем эту задачу к меньшей.
Итого весь алгоритм решения: считаем количество КСС и выводим ответ на задачу:)
Мы в D сдали за φk. Пишется очень быстро мы на обсуждение и писание потратили минут 15. Вообще эта задача уже раза 3 была. Сначала на РОИ, потом вроде на SNWS этой зимой, недавно была на СРМе и по-моему еще где-то.
А можешь код показать?
Вот ссыль. Правда там есть отсек по времени)) Чтобы решение стало полностью правильным и честным надо каждый раз пересчитывать степень вершины согласно тому какие ее соседи уже взяты в ответ и среди таких выбирать вершину с наибольшей степенью.
Upd: код совсем ужасен потому, что мы начали ее писать за 18 минут до конца.
А этот код не работает, например, на цепочке из 65 вершин :(
Ну я же написал как его сделать правильным. Я знаю что код неправильный. Там баг в Ифе который сравнивает количество соседних. Надо честное количество считать.
А можно подробнее про φk? Ссылку на статью, или, если это сугубо олимпиадное знание, хотя бы доказательство?
РОИ 2010, задача 2
Общая идея такая. Будем брать вершину большой степени. Мы должны взять или ее или всех ее соседей. Если вершина степени один, то один из вариантов не нужен Итого получаем рекуретность Fn = Fn - 1 + Fn - 2. Которая решается угадай как.
Если действовать чуть аккуратнее, то можно отдельно разобрать случай, когда остались только циклы. Тогда будет Fn = Fn - 1 + Fn - 3, которая решается как примерно 1.46n.
Мне Burunduk1 как-то рассказывал про то, как похожими идеями можно искать максимальную клику за 1.21n или что-то подобное. Кажется там надо разбирать отдельно степени до 6.
Вот отличный пример подобной деятельности.
как можно поучаствовать в контесте ? есть ли там дорешивание что бы потренероваться ?
В чем подвох в А? Упорно получаю WA 19.
Вот тест:
Ответ должен быть Yes?
Нет:)
Да, точно, спасибо!
Вот мое решение: http://ideone.com/4wMFYP
Кстати, все в F писали FFT? У кого сколько реализация работает? (у меня была 2048*2048 за 750мс локально)
Расскажешь решение?
Эм. Перемножить ффт таблицу с перевернутой? (ну, выписать таблицу в ряд, между рядами вставить по n нулей). Потом просто для каждого вектора мы знаем, сколько таких векторов с концами в точках есть
У кого-нибудь был WA 14 в B? Проверил на куче своих тестов, даже побрутил на малом инпуте — не нашел у себя баги :(
Попробуй тесты, на которых C=0.
Да у меня для С=0 даже отдельные функции написаны :( Ладно, побрутим еще, спасибо