


Вот уже несколько лет в ACM сообществе считается нормальным выставление тайм лимита в 2 от времени работы авторского решения. Это неплохо работает в соревнованиях, проводимых по правилам АСМ (однако по моему мнению, стоит выставлять по среднему геометрическому от авторского и того, что не хотелось бы, чтобы прошло)
Однако мне кажется, что в соревнованиях, где результат итогового тестирования не известен до конца контеста такой вариант неприемлим. Локально на тл особо не потестишь, тестирование на макс тесте в запуске довольно трудоемкая штука, и когда тебе кажется, что попал в авторскую асимптотику ты этого делать скорее всего уже не будешь
Конкретно для Codeforces мне кажется разумным 2 варианта — либо ставится минимум 5х от авторского, либо макс тест добавляется в претесты. Мой коментарий про это в посте 200го раунда заминусовали, мне хотелось бы выслушать аргументы тех, кто не согласен с этой точкой зрения







Не совсем в тему, но заинтересовало, почему именно среднее геометрическое? Лично мне кажется логичнее среднее арифметическое худшего авторского и лучшего неправильного.
Потому что в разах. Тл будет в x раз больше времени работы авторского и в x раз меньше времени работы неправильного. Тогда и похожее на авторское должно пройти, и похожее на неправильное не должно пройти. Если брать среднее арифмитическое, то будет всегда в пределах 2х от неправильного. Оптимизаторы всегда найдутся
от времени работы авторского решенияНужно ещё смотреть на каком языке оно написанно.
Установка таймлимита в 5x от авторского означала бы то, что пройдёт больше решений с неправильной асимптотикой. Следовательно, надо увеличивать размеры тестов, чтобы отделить эти решения, а от этого увеличивается нагрузка на систему и снова поднимается таймлимит. И всё для того, чтобы дать возможность участникам писать асимптотически правильные, но неоптимизированные/медленные решения? Я довольно уверен в том, что большинство правильных решений укладывается в 2x от времени работы авторского решения на Java.
Теперь о макстестах. Макстесты часто бывают разные, и валят они тоже разные решения. Получается, надо добавлять в претесты все? Что тогда останется в тестах? Что будет с нагрузкой на систему во время раунда?
В задачах Div. 2 в претестах всегда есть один макстест. Он по возможности сделан так, чтобы просто проверить асимптотику решения и больше ничего — то есть, просто смотрит, успеет ли программа выполниться или нет, и не проверяет ничего другого. Можно было бы утверждать, что такое нужно и в задачах Div. 1. Однако здесь появляется вопрос: неужели участник Div. 1 недостаточно квалифицирован и пошлёт асимптотически медленное решение? Должна ли система проверять это за него?
Остаётся, пожалуй, случай, когда участник Div. 1 написал асимптотически правильное решение, но не уверен, уложится ли оно в таймлимит (например, в задаче большой размер ввода/вывода). Мне кажется, проблема здесь не в претестах, а в
Вот это можно исправить (разрешить в запуске использовать свой генератор), и проблема тогда исчезла бы.
Написание своего генератора тоже трудоемкая штука, да. Если авторское от неправильного по времени работы различаются менее, чем 15х — ну да, надо добавить макстест в претесты. И да, можно ничего не проверяющий макстест. Это дает не только возможность понять, что асимптотика неправильная, но и то, что константа неправильная при правильной асимптотике
Кстати, по вчерашней задаче — 24-ый тест, на котором завалилось решение, просит вывести все 500000 строк, так что дело может быть в не очень быстром выводе. Этот тест действительно можно было добавить в претесты, а так в претестах был только рандомный макстест (где выводить нужно только для 1/3 запросов).
Да, похоже дело именно в этом. Но требовать вывода нескольких мегабайтов по-моему вообще плохо. Может, стоит в таких случаях просить вывести какой-нибудь хеш?
Это, конечно, вариант, но часто может пойти в ущерб к оформлению задачи. А в данном случае, если нужно было бы вывести одну строку из 0 и 1, оно бы работало значительно быстрее? Кстати, если интересно, то вот авторское решение на Java http://ideone.com/5aNM4u.
Вроде бы это нормальное решение, без всяких оптимизаций. Мне кажется, что 4 секунды было нормальным ограничением здесь.
MAXN, конечно, как заметили ниже, губит стиль, но ведь в скорости работы программы абсолютно ничего не изменилось бы, если бы массивы создавались нужного размераn.Хотя вот я его отправил только что — оно за 2340 мс отработало. Надо было 5 секунд поставить.
Но еще надо отметить, что для вывода еще и 2 запроса к дереву нужны, так что оно работает еще медленнее
Всецело за, я тоже уже не раз писал о подобном, но тоже не нашел понимания. Имхо, и в ACM-style контестах 2x — это мало, потому что при желании автор может "утоптать" в 2 раза практически любое решение (при наличии неограниченного времени на подготовку задачи), и у участников могут возникнуть реальные проблемы с таймлимитом даже при верной асимптотике (что нередко наблюдается, например, на питерских контестах). Является ли это правильным — большой вопрос.
По поводу среднего геометрического от авторского и того, что не хотелось бы, чтобы прошло — выглядит натянутым. Если решения с "плохой" асимптотикой работают гораздо медленнее авторского — то и при ограничении 5x умрут, а если они укладываются в 5x — то тут уж, извините, нельзя утверждать, что они неэффективны и у них "плохая асимптотика". Кроме того, иногда вообще сложно представить, что могут попробовать сдавать, поэтому здесь вообще непонятно, от чего брать геометрическое.
Другое направление размышлений на эту тему — CF может ввести правила подготовки авторских решений. Например, чтобы оно было написано не на массивах и мега-оптимизировано, а было на векторах/листах, без избыточных оптимизаций.
Среднее геометрическое не отменяет какого-то минимального x, конечно
И да, речь идет о нормально написанном, а не о переоптимизированном авторском решении
Ну это уж слишком. Есть автора, которые привыкли писать быстро работающий код. Им просто удобно так. Это стиль. И заставлять их портить свои решения, что бы потом вместо Гомори-Ху кто-то засылал квадрат не правильно. Всем известно о скорости языков программирования. Почему не возмущаются приверженцы питона? Ни кто не гарантировал существования решения на всех языках программирования. На Киевских отборах вообще речь не идёт о 2x. Там иногда просто добавляется 100 мс к авторскому времени.
Ага, гораздо лучше, чтобы асимптотически верные нормально написанные решения (читай не говнокод на массивах, а нормальный промышленный код, который работает на 30-50% медленнее) получал TLE, так по-вашему?
То, что на киевских сборах ограничения устроены через это самое место — не повод транслировать эту практику на всю планету (кроме того, может речь про олимпиады, на которых можно получить неполный балл за чуть более медленное решение — это еще туда-сюда)
А по поводу стиля: когда придете работать, вам быстро объяснят, что свой стиль надо засунуть себе поглубже под диван, и писать код как хочет контора, а не как хочется вам.
P.S. Да, и если вы не можете придумать тесты, на которых Гомори-Ху работает существенно быстрее решения за квадрат — то не надо давать их на контест (ну, или смириться с тем, что решение за квадрат тоже считается верным).
Так на последнем контесте решение с Гомори-Ху работает максимум 90 мсек, а решения за квадрат поисков потока работают порядка секунды (линк). Так что тут в чистом виде недоработка авторов.
Бред какой. Нужно убегать, если контора хочет, чтобы использовались контейнеры с последовательным доступом, когда нужен произвольный доступ) Даже имея суровый style guide можно сразу писать быстро работающий код (конечно, я не имею ввиду оптимизации branch predictor'а в ущерб читаемости, например).
Последовательный доступ — это вы о чем? О List? В C# (и вроде бы в Java) это аналог вектора. Вам тогда придется всю жизнь бегать, если вы в принципе не хотите не хотите следовать style guide.
Даже имея суровый style guide можно сразу писать быстро работающий код
Это как? Например, у вас в style guide написано: никаких массивов, все только на vector/List, последние по определению работают несколько медленнее. Как вы собираете ускорять?
Да, я о List, потому что я не знал, что это такое в С#, спасибо. А про сразу писать быстро работающий код — я имел ввиду не делать push_back тогда, когда это делать не нужно, а заранее сделать resize или reserve. А еще можно наиболее вероятный переход в if/else писать в первом if.
P.S. Я не говорил про то, что в принципе не хочу следовать style guide.
resize/reserve — это тоже дело привычки (или не-привычки) для тех, кто на практике занимается программированием. Зачастую заранее вам как раз неизвестно количество данных, с которым потом придется работать, так что вы используете push_back, тем более что он не ухудшает асимптотику.
Ну и это все плохие примеры оптимизаций, имхо. Если факт сдачи/несдачи задачи зависит от того, используете вы push_back или нет, или что пишете первым в if-elfse — думаю, лучше, вместо участия в контесте с такими задачами, заняться более приятными вещами.
При чем тут сдача/несдача? Я с вами согласен по поводу того, что это не должно зависеть от перечисленных методов. Я просто не согласен с тем, что обязательно на работе придется засунуть под диван подход написания быстро работающего кода.
Если "подход написания быстро работающего кода" состоит в использовании массивов вместо векторов, resize'ов вместо push_back, и правильной компоновке ветвей if-else, то боюсь, что придется (потому что иногда в style-guide'ах регламентируется даже порядок if-else)
А в данном посте обсуждение идет как раз того, что у людей, пишущих в промышленном стиле на Яве, не очень-то получается писать мега-быстрый код.
Может в вашей конторе и сортировать быстрее, чем за квадрат не надо, так что теперь? Пришли на контест — пишите быстрый код, хотите писать красиво — на свой страх и риск, пожалуйста.
А, ну с логикой "не нравится — идите в ж..у" вы быстро популяризируете спортивное программирование, это да.
Ну а как? Есть три критерия: правильность, время работы и затраченная память, и ваши проблемы как с этим всем справляться. Или вы предлагаете за красоту кода баллы накидывать?
Ну так вы тогда и давайте баллы за эти три критерия (как делают, например, на школьных олимпиадах). А когда у вас оценка только бинарная — надо давать участникам пространство для маневра.
Ваше пространство — это T секунд времени и M мегабайт памяти.
ЗЫ. Я вот недавно школу закончил, достаточно много олимпиад для школьников писал, но ничего такого не встречал.
Ты просто не представляешь, как могут возмущаться приверженцы питона...
To : что нередко наблюдается, например, на питерских контестах Да это нормально, потому что это специфика школы. Цель opencup в том числе показать специфику разных школ. Я же не жалуюсь, что на Уральских контестах очень много геометрии?
А я нигде и не жаловался. Я говорил, что это может не всем нравиться. Я, например, уже несколько лет не пишу питерские контесты, потому что никакого удовольствия для меня в этом нет. А вот уральская геометрия мне очень по вкусу.
Поддерживаю предложение. Ещё стоит добавить, что если асимптотически правильное решение с плохой константой не получается отделить от асимптотически неправильного — то что-то не так с задачей или огранечениями.
Альтернативным решением проблемы было бы обязательное наличие авторского решения на Java (нормально написанного, а не "переведённого" с C++). К сожалению, большинство авторов Java не знает, так что это скорее мечты...
Ну, бывают задачи именно на константу, про это тоже не стоит забывать
Казалось бы, при лучшем знании языка, программы пишутся и работают быстрее. Так что, если человек не знающий джаву сможет написать решение, то человек с опытом сможет написать решение оптимальнее затратив меньше усилий. Что не так в моей логике?
Нет, конечно. При лучшем знании языка код получается более чистый, читаемый и переиспользуемый. Да, человек, знающий джаву, при желании может писать переоптимизированный говнокод, в котором всё сделано на массивах. Но это 1) говнокод, 2) никакого удовольствия от его написания не получаешь. Если же писать всё "правильно", с классами, etc. — то оно разумеется работает медленней решения на массивах.
А в чем отличие нормально написанного решения на Java от переведенного с С++?
Оно чуть удобнее пишется, но чуть медленнее работает?..
У каждого языка своя идеология написания программ. Нормально написанное решение на Java не очень похоже на то же самое решение на C++. Вам ведь не пришло бы в голову переводить программы с C++ на Haskell, например?
А Вы не допускаете, что если решения на С++ без каких-либо оптимизаций работают 1,5с, а "нормально написанные" решения на Java не успевают и за 4с, то это плохой "нормальный стиль" или "плохая Java", а не плохой TL? Никто же не заставлял вас писать именно на Java, да и еще так, чтобы оно не заходило. Стандартные библиотеки Java сильнее, чем у C++, и у этого есть своя цена.
Так о том, вроде бы, и дискуссия, начиная с какой разницы считать стиль и Java'у "плохими"? Автор считает — 5x по сравнению с непереоптимизированным решением на C++. Имхо, выглядит разумным. 1.5 сек. / 4 сек. явно может быть недостаточным.
Ну лично я пишу на джаве не из-за стандартных библиотек (чем они сильнее плюсовых? только BigInteger?). Поверьте, от контеста удовольствия получается гораздо больше, если есть нормальная IDE (и не приходится тратить силы на, грубо говоря, "ввод и форматирование текста").
Проблема в том, что если не заходят нормальные решения на джаве, то не зайдут и решения на C++ с константой, чуть большей авторской в силу случайных причин. Ну например написал человек вместо pair<int, int> свой класс с виртуальными методами — и всё, константа уже в разы больше (если конечно bottleneck был в работе с pair<int, int>). Зачем ставить жёсткие ТЛи в задачах на алгоритм, а не на оптимизацию константы?
Тем более. Ты сам только что подтвердил, что Java — это "не меня так научили, по другому не умею", а осознанный выбор. Основанный на каких-то преимуществах. Тогда почему считается, что авторы должны что-то делать с недостатками, которые к ним прилагаются? Почему "у меня более медленный инструмент, но мне на нем приятнее писать", считается нормальным аргументом, а если я скажу, что "Фу, плохая задача, в ней надо написать алгоритм дейкстры, а не флойда. Он же в три раза короче и удобнее и мне его больше нравится писать", то на меня посмотрят как на сумасшедшего (и правильно сделают!).
Казалось бы, люди ратующие, за "так надо писать в промышленном коде" должны еще лучше понимать, что для каждый задачи у инструмента есть преимущества и недостатки. И выбирать надо исходя из них, а не исходя "мне этот больше нравится".
Да и понятие "больше удовольствия" тоже очень относительное. Я например не получаю удовольствия от писания на языке, в котором 80% кода может написать среда, потому что в нем эти 80% кода не нужны. Мне неприятна идеология джавы в целом. Я же не призываю ее запретить.
Собственно почему "решения на C++ с константой, чуть большей авторской в силу случайных причин" должны проходить? Чем С++ лучше-то? Если считается, что единственный формальный критерий по которому должны отсекаться решения — это асимптотика, то надо присылать не код, а описание решения с доказательством. Почему-то это никому не приходит в голову. И проблема не только в невозможности это проверить за разумное время. А иначе есть вполне формальный критерий — скорость работы. Так тогда какого черта?
В любом случае, заходящие неправильные решения ставят участников в куда более неравное положение. Если не зашло решение, которое написано не оптимально, то в любом случае участник сделал что-то хуже чем мог. Правильно ли за это снимать задачу это отдельный вопрос. Но если заходит неправильное, то участник оказался ниже, потому что правильно оценил, что решение не должно проходить! Это явно куда больший бред. Только почему-то считается что это меньшая проблема, чем не зашло, потому что на Джаве.
И на последок. Мне кажется, что почти все здесь были бы рады, если бы на CF разные вещи появлялись медленнее, зато сервера бы падали в два раза чаще и работало все в два раза быстрее.
Только почему-то считается что это меньшая проблема, чем не зашло, потому что на Джаве
Не люблю участвовать в холиварах (а по глубине дискуссии — это уже он), но попробую объяснить, почему так.
Потому что если у кого-то зашел квадрат вместо логлина — то это косяк, но "позитивный косяк" (участник радуется, остальные не особо огорчаются, если огорчаются вообще). И в любом случае это косяк жюри. А ибо нефиг давать задачи, в которых не можете гарантированно отсекать решения по асимптотике.
Если же у кого-то не зашло асимптотически правильное решение — то это "негативный косяк": участник тратит лишнее время и нервы на оптимизацию (иногда ОЧЕНЬ много лишнего времени и нервов), иногда вообще не сдает. Зачастую в любом случае это подрывает выступление, поскольку потраченное время не позволяет сдать еще одну задачу.
Что хуже — когда пара менее сильных участников окажется в топе, или когда пара сильных участников окажется в ж..е? Мне кажется, с точки зрения озвученной выше теории позитивизма в спортивном программировании — второе.
Ситуация "Не сдал" всегда неприятнее ситуации "Сдал".
Но разве это вина автора задачи, что решение сильного участника не проходит? Участник знает задачу, знает ТЛ, знает ограничение на входные данные, знает специфику и скорость работы языка и его инструментов, и на основе всего этого выбирает алгоритм и инструмент для реализации этого алгоритма. Уж кто, а сильный участник должен уметь делать правильный выбор сразу.
Уж кто, а сильный участник должен уметь делать правильный выбор сразу
Неверное утверждение. Есть куча факторов, которые сложно учесть — размер кэша на сервере, например. Помнится, мы как-то сделали выбор в пользу линейного алгоритма (хэшами) на логлинейным (сортировкой), и улетели на том, что на проверяющем сервере был маленький кэш. Можно не знать в точности, насколько, например, std::pair работает медленнее/быстрее какого-то кастомного класса, который вы собираетесь использовать, и т.д.
P.S. /* END OF HOLYWAR */
Забавно. А мне как раз кажется наоборот: неверные решения не должны проходить ни в коем случае, может быть в пользу большей гробовости задачи. И я гораздо больше ругаюсь, когда в задаче с ограничением в 105 проходит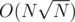 из-за сильных тестов, при том, что авторское имеет ту же асимптотику.
из-за сильных тестов, при том, что авторское имеет ту же асимптотику.
random_shuffleи куб из-за слабых тестов, чем когда я не могу в ней запихать решение заТут вопрос, похожий на "какие тесты делать":
Ну правильно, и делать надо именно тесты первого типа (почему-то именно их делают на финале?), потому что тестировать надо умение решать задачи и придумывать алгоритмы, а не умение быстрого чтения на Java и выдрачивания констант в решении. Хотя, кто что любит, с фанатами задач второго типа сложно спорить.
На последнем финале были тесты второго типа, и это прекрасно. Иначе приходится гадать, что имели в виду авторы и почему 1000 тестов с асимптотикой n*2^n при n=20 влегкую залетают по TL
==========расширитель====================расширитель========== Уже нет. Например, в этом году были чёткие ограничения под мультитесты (на сумму).
С фанатами задач первого типа тоже очень сложно спорить. Да и вообще сложно убедить человека сменить свои убеждения и видение целей спортивного программирования в частности.
Два моих последних аргумента:
Я не говорю, что надо писать в стиле "массивы и указатели" абсолютно всё, каждой задаче — свой инструмент. 99% сервиса может быть написано на Java/C#/Python, но тот самый безумно тормозящий 1% я лучше перепишу на C, даже если потом на изменение структуры таблицы придётся потратить день, а не час. Разумеется, не сразу, а лишь после убеждения, что этот кусок кода не поменяется через три минуты.
==========расширитель====================расширитель========== Тогда мои последние аргументы:
В России очень любят бюрократию и формализм. Даже провели финал — и тут устроили формализм "не более 1000 тестов, не более ... в каждом". Зачем? У baylor'а есть на этот счет политика, которую они часто везде упоминают — "generous time limits" называется, то есть в 10-20 раз больше авторского решения. Если вы в это уложились — молодцы, значит задачу решили. Все равно через пару лет скорость компов возрастет и скорость вашего решения будет как у автора сегодня. И какая нафиг разница, какая у вас асимптотика, если скорость работы решения примерно как у автора? В России же надо везде сделать бюрократию. И что в итоге? В штатах — google, apple и facebook, а у нас — распилково, то есть осколково, то есть сколково.
Если говорить не про программирование для потребителя, а про продукты для внутреннего пользования, то скорость тоже особо никого не парит. Главное — хороший код и — да — асимптотика. То, что это работает в 2-3 раза медленнее, чем могло бы — фиг с ним. В современном мире большая корпорация, если ей надо ускорить код в два раза, купит в 2 раза больше серверов, нежели будет увеличивать скорость в ущерб качеству кода.
Не надо сравнивать желание знать правильные ограничения в задачах и количество бумажной работы в государственных учреждениях. Это разные вещи. Про задачи приведу пример из собственного опыта. Была задача с ограничениями на n где-то 2000-3000 тысячи, но про количество тестов не было ни слова. Чаще всего в таком случае тест в задаче один и содержит порядка 4-10 макс.тестов и кучу маленьких. Мы решили задачу за квадрат и получили TL. Пришлось решать её за линейное время, так как оказалось, что одном файле могло быть до 1000 тестов и все они были достаточно большие.
А вы своему заказчику скажите — купи компьютер побыстрее? Ну ладно, корпоративные заказчики могут себе это позволить. А если это пользовательское приложение, например, компьютерная игра? Вы же тупо потеряете часть аудитории.
Ну все таки честности ради, к задачам последнего финала российские авторы не имеют никакого отношения.
============================================================
P.s. Это уже не говоря о естественных издержках на синхронизацию многопоточных программ, которые существенно растут с ростом числа серверов.
Ога, я смотрю набежала куча прикладников с огромным опытом работы в куче больших организаций, и стали мне рассказывать, как там делают, ага.
Полный бред — это то, что вы написали. Покажите мне хоть один случай, когда команду программистов меняли, потому что у них код не очень быстрый? Просто смешно.
Возьмем какую-нибудь крупную компанию, скажем, google.
У неё есть(я понятия не имею, какие точные цифры), к примеру, 100000 серверов(стоимостью, например, 5000$ каждый), которые занимаются только поиском по своему маленькому кусочку интернета и делают это за какое-то время. Можно предположить, что добавляя ещё столько же серверов, мы можем получить время ответа в два раза лучше, так как можно уменьшить кусочек интернета на каждой машине(это не совсем точная оценка, есть ещё куча затрат, но я думаю, что если говорить не цифры типа в 2 раза больше, а на 1% больше серверов, то зависимость там почти линейная).
Теперь посчитаем, сколько будет стоить программисту ускорить кусок их общего кода на 1% — это 100000 * 5000$ * 0.01 = 5000000$(5 миллионов! долларов).
Неужели не впечатляет? :)
Upd: Если я не ошибаюсь, то это около(а может быть и больше) 20-30 годовых зарплат обычного разработчика в google, так что можно на эти деньги нанять большой отдел программистов на целый год :)
Начнем с того, что $5 млн. для крупной компании — вообще ничто, поэтому цифра не впечатляет.
Зато вы забыли при расчете вашей дельты в 1% учесть, а на сколько больше времени надо затратить программистам, чтобы добиться такого ускорения? Если даже хотя бы на 0.3% (я думаю) больше — вы уже в минусе, потому что железо стоит гораздо дешевле зарплаты дополнительных программистов. В пересчете на время: если вы тратите на оптимизацию кода 1.5 мин. в день (!), и добиваетесь выигрыша только 1% — вы вероятно приносите вашей компании убыток по сравнению со случаем, если бы не тратили этого времени. Это гораздо более интересные цифры, над которыми надо задуматься.
================================================================================= Почти ничего не понял, но зато я ошибся в комменте выше, в интернете пишут, что у гугла миллионы серверов, а не сотни тысяч, так что это ~ 50 миллионов долларов.
Честно говоря, я не призывал писать все на языке ассемблера, просто если все векторы в коде этих серверов поменять(где это не очень сильно ухудшит код) на стат. массивы, то выигрыш, наверное, получается даже не на 1%, а почти десятки. Я не видел код гугла, но думаю, что о производительности этих штук они очень заботятся. Во всяком случае, гарантирую вам, что есть очень хорошие компании, где используется branch-prediction и все такое.
Больше серверов это никогда не лучше, чем меньше серверов, вы когда-нибудь общались с каким-нибудь человеком в компании, который отвечает за работоспособность какой-нибудь системы насчет того, что вы тут кое-что хотите прикрутить и немножко все затормозите и в качестве довода говорили ему, купи ещё серверов для проекта? Для этого нужны админы, которые увеличат сеть, найдут проблемы, что их сетевое оборудование не поддерживает столько машин, поймут, что сеть стала больше тормозить и проблемы начались не только у вашего проекта и это ещё ни слова про деньги на обслуживание новых серверов и их закупку.
А ещё есть компании, которые пишут биржевых роботов и у них в описаниях вакансии сказано, что они оптимизируют время отклика пока только могут это делать и даже пользуются ассемблерными вставками.
Upd: я не считаю, что увеличение производительности на 1% — это всегда работа всей компании, бывает что это работа небольшой группы людей. Мой точка зрения была скорее в том, что 10 человек готовы следить за тем, чтобы в самом узком месте поиска все пользовались массивами вместо векторов и ни у кого ничего не ломалось, и эти 10 человек стоят дешевле, чем 50 млн.$ только на закупке этих серверов.
Кстати, я не в счёт, так как уже три года на джаве пишу. ;D
И до сих пор MAXN? Ай-ай-ай
Ну это решение я действительно транслировал с С++. На Java я пишу на работе и, естественно, всё там очень чисто, названия переменных ясны итд.
На контестах, или в реальной жизни? < sarcasm> Если второе — сочувствую коллегам, которым приходится поддерживать код с MAXN и приколами вроде всей логики дерева отрезков, заinline'енной в код, который использует это дерево отрезков :) < /sarcasm>
Я всегда был за то, чтобы проходили все разумно написанные асимптотически правильные программы, а не за пропихивание грязно оптимизированных решений на C. Но время 5x мне кажется слишком жирным и максималистским. Лимиты нужны разумные, в том смысле, что проходят все нормально написанные правильные решение и заваливаются все безумно оптимизированные неправильные решения. Для многого количества задач (особенно с потоками) найдутся мастеры, которые могут соптимизировать неправильное решение хоть 10-100 раз, и пропихнуть код. Так же, правильное решение можно сделать очень медленным многим количеством способов (классический пример — cin/cout в С++ без отключения синхронизации с stdio). Поэтому 2x от неоптимизированного авторского решения является достаточно хорошим выбором. Нужно также хорошо знать язык, на котором пишется решение. Всегда есть на формальную асимптотику не влияющие структуры, которые очень тормозят программу, и можно заподозрить, что лучше в программе эти вещи не использовать. Всё-таки задача на контестах — не только придумать асимптотически правильное решение, но и достаточно эффективно его реализовать. Временной лимит обычно неофициально гарантирует, что существуют неоптимизированные программы на С, С++ и Java, которые проходят данный лимит.
На прошлом контесте у нас была задача с n, m до 200000, которую идейно можно было решить тупо запустив поток. И хотя мы придумывали всевозможные тесты, готовили анти-Диниц генераторы и валили все потоки (а наши реализации не были слишком оптимизированы, к сожалению), всё равно нашлась пара людей, которым удалось запихать поток. Что бы было, если ограничения были бы в 5 раз слабее? Или же вчера на том же Гомори-Ху авторское решение работало 200 мс, а (даже не очень оптимизированные) медленные решения работали за 1000 мс. По иронии, эти решения именно в 5 раз медленнее авторского.
Добавление макстеста в претесты — стандартная практика. Однако макстест не обязательно должен покрывать самый хитрый случай, а только проверять, корректно ли работает программа с такими большими данными. Более умные тесты должны скрываться за претестами.
Кстати, не очень понятно, почему в индустрии должно считаться хорошим тоном писать программы, которые в 5 раз медленнее, чем могли бы быть. Всё-таки надо стараться писать достаточно быстрый код, и в тоже время поддерживать хорошую читабельность для поддержки.
Доброго времени суток. Я старательно прочитал все мнения в теме, хочется выразить свое на данный счет.
Мне кажется, что в затронутой в теме задаче было принято разумное решение по установлению TL = 4s. Я объясню, почему был именно такой TL. Но прежде хочу отметить, что у нас нет четкого правила, что мы ставим 2x от решения на Java. У нас есть правило, что мы ставим минимум 2x от решения на Java. Конечно, в каждой задаче решение принимается отдельно, какой TL ставить. Иногда этот запас 15x, иногда даже больше. Все завит от того, какие неправильные/правильные решения существуют. Мы всегда стараемся поставить TL как можно более лояльно по отношению к участникам (например, если возможно сделать так, чтобы Python прошел, стараемся так сделать). Конкретно в этой задаче было решение с корневой эвристикой, оно не укладывалось в TL достаточно сильно (в 2x где-то), но мы боялись, что кто-то может что-то неожиданное упихнуть, поэтому TL поджали.
Если говорить в целом, мое мнение сходится с мнением Паши Кунявского. Вы сами делаете осознанный выбор на чем писать (не буду сейчас все аргументы приводить, почитайте Пашины комментарии). Мы же делаем все, чтобы вам было удобно. Где-то получается сделать совсем удобно, где-то не получается. В целом, я считаю, что наша система по установке TL хорошо работает и многих устраивает. Есть единичные случаи, когда случаются казусы. Ну а где их нет? :)
Ну вот не было же 2х от Java — 2340 авторское дало. Но лично мой посыл был не про это, а про то, что надо понимать разницу между АСМ и форматами с дополнительным тестированием по окончанию. Они требуют разных подходов
Согласен. Но тут был почти двукратный запас. На контесте я видел типичные решения на Java, проходящие в меньше чем за 2 секунды.
Да, я понял посыл. Как я уже написал, мы не просто ставим х2 от быстрого авторского. Есть много факторов.
Зачем банить корневую? Она ведь прикольная :)
Возвращаясь из холивара к теме поста:
1)
Не согласен и считаю, что стоит выставлять минимум из C*авторское и какой-то функции от неправильного решения. Второе надо, чтобы не прошло неверное, а первое надо, чтобы коварные участники не придумали случайно какой-нибудь адский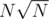 вместо
вместо 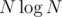 . Довольно сложно придумать все отсечения, которые может придумать участник на контесте и обязательно же какой-нибудь
. Довольно сложно придумать все отсечения, которые может придумать участник на контесте и обязательно же какой-нибудь 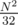 не очень сильно отличается от
не очень сильно отличается от 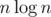 или упиханного квадрата с хитрыми
или упиханного квадрата с хитрыми
breakв самом вложенном месте квадрата не придумается. Я считаю, что TL в max(2s, round(2*авторское)) — это разумно. На простых задачах всё равно, а на сложных делать TL еще в 2.5 раза больше не очень корректно, потому на текущих ограниченияхbreak. Можно, конечно, делать в польском стиле — все ограничения по 2·106, но тогда будет совсем печально с чтением и временем тестирования.2)
Непонятно. Как это "локально на TL" не потестишь? Представим идеальную ситуацию: компьютер и настройки в точности совпадают с такими на сервере. Тогда этот аргумент исчезает, поскольку пока все согласны, что крайние случаи легко можно не включать в претесты (тогда на них ломают), а чем составление большого теста принципиально отличается от составления теста вообще и почему должна быть поблажка?
В неидеальной ситуации всегда можно в случае сомнений, во-первых, представить, что зависимость между скоростями линейна (неплохое приближение, это первое, что мы делаем на пробном туре) и найти худший тест для своего решения, а во-вторых можно запустить на вкладке "запуск" (про неё — в следующем пункте).
3) Полностью поддерживаю добавление генератора на вкладку "запуск". Встраивать генератор в решение можно, но довольно неприятно. На онсайт-соревнованиях обычно компьютеры участников и проверяющие идентичны, поэтому проблем с тестирование вообще почти не бывает.
Если будет, то желательно убрать все эти ненужные проверки на детерминированность — они никому не нужны на вкладке "запуск" и будут только увеличивать отклик.
4) Макстест в претесты — идея хорошая, мне нравится. Он совершенно не обязан быть худшим, простой рандом был бы хорошим вариантом. Правда, тогда могут возникнуть проблемы с задачами, в которых большой случайный тест проверяет почти всё — резко уменьшится количество WA на финальных тестах.
Просто не мог пройти мимо темы с таким названием.
Мне из практических соображений не нравятся утверждения вида "попал в авторскую асимптотику", но в целом с мнением автора я согласен. С другой стороны, мне кажется наиболее неверным в оффлайн-проверках TC/CF подход к TL вообще. Действительно, если баллы даются за тесты, то решение, работающее на худшем тесте 2.1s при TL = 2s, получит очень много. В правилах ACM скорее всего такое решение будет стоить лишних 20+5 штрафных минут. В оффлайн-проверке типа CF/TC получается "пан или пропал" — макс. тест 1.9s все баллы, макс. тест 2.1s ноль баллов. Аналогично, один неучтенный тест — ноль баллов (правда, частично неучтенные тесты в правилах CF компенсируются возможностью взломов).