


Two years ago I came up with an idea (Russian only) of making a generic library for creating testcases. Months have passed, thoughts circulated in my mind over and over, and finally I sculpted something in code. Far many things are yet not implemented, but I already frequently use ones which are.
Here it is: https://github.com/ifsmirnov/jngen. You can download the library itself (its single header jngen.h) here.
Jngen works with arrays, graphs and trees. It also can generate some strings and geometry and provides command-line options parser and cool SVG drawer. Here are some working examples.
cout << Array::id(10).shuffled().add1() << endl; // permutation of elements from 1 to 10
cout << Tree::random(100000, 20) << endl; // "long" tree with elongation 20
pair<string, string> test = rnds.antiHash({{mod1, base1}, {mod2, base2}}, "a-z", 10000); // should be self-describing :)
cout << rndg.convexPolygon(1000, 1e9) << endl;
cout << Graph::random(100000, 200000).connected() << endl;
cout << rndm.randomPrime(1e18, 1e18 - 10000000) << endl;
Almost all code is documented, there are some real-world examples.
Getting started is very easy. If you work with testlib.h and use in your generators only registerGen and rnd.next, replace #include "testlib.h" with #include "jngen.h" and you'll see no difference. Compilation will last a bit longer, but there is a workaround which makes it compile even faster than testlib.
I'll be happy if you try it and share your feelings and feedback. Everyone finds his code and interfaces perfect until shows them to the community.
Currently the library has much more "basic" things and primitives than "real content" – I mean there are more bricks than practical testcases. We're working on it: soon several "test suites" will be added, and you'll be able to create reasonable tests for your, say, LCA-like-queries problem, in several lines of code.
I'd like to thank zemen, Endagorion and Errichto for useful discussions and advice, Endagorion, GlebsHP and CherryTree for their libraries from which I could borrow code learn upon and MikeMirzayanov for testlib which was a massive source of inspiration on early stages.






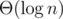 independently of rand() calls.
independently of rand() calls.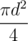 . Then you should compare thisit with
. Then you should compare thisit with 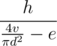 seconds. Otherwise you would never do it.
seconds. Otherwise you would never do it.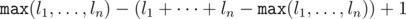 .
.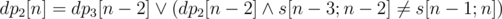 . Similarly,
. Similarly, 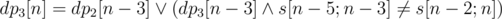 . If any of
. If any of 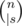 ways to do it. Next, you can use any of
ways to do it. Next, you can use any of 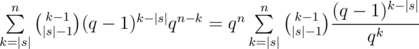 strings containing
strings containing 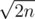 different lengths. Thus simply applying the overmentioned formula we get a
different lengths. Thus simply applying the overmentioned formula we get a 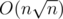 solution, which was the expected one.
solution, which was the expected one.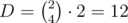 . Now for each
. Now for each 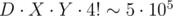 ; however, it is impossible to build a test where all permutations in the second case give a valid position, so you can reduce this number. Actually, the model solution solves 50 testcases in 10ms without any kind of pruning.
; however, it is impossible to build a test where all permutations in the second case give a valid position, so you can reduce this number. Actually, the model solution solves 50 testcases in 10ms without any kind of pruning.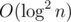 per query time complexity.
per query time complexity.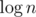 per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in
per query, called fractional cascading. Instead of doing binary search in each node we do it only in the root, and then "push" its result to children in  , others are
, others are 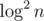 ! Time is averaged over several consecutive runs. Test data is generated randomly with
! Time is averaged over several consecutive runs. Test data is generated randomly with 