


Problem A. Long-Term Mail Storage.
The probelm asked to simply simulate the process. One can keep yet unread mails in any data structure (array, deque, set, whatever) and iterate through time. For any moment of time x we first check whether there is a new incoming letter and add it to the structure if that is the case. Now, check if the ``feeling guilty'' condition is satisfied. If so, compute k and remove k oldest letter from the structure. Doing all this in the most straightforward way would result in O(nT) complexity.
Excercise: solve the problem in O(n) time.
Problem B. Lassies Versus Machine.
First of all, note that if Dusya and Lusia split n in x and n - x they would get exactly the same set of banknotes as a change as if they split in x + 5000 and n - x - 5000. That means, we only have to check all possibilities to split from a to min(a + 5000, n - a). For each possibility we compute the change in O(1) time. If some girl wants to pay y the change will be (5000k - y) mod 500, where 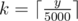 .
.
Excercise: prove that it's enough to check only values from a to min(a + 499, n - a).
Problem C. Effecient Management Returns.
There are many different approaches for this problem and almost all solutions one can imagine will work as the size of the answer will never exceed 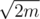 (excersise: prove). This editorial contains only one possible linear time solution.
(excersise: prove). This editorial contains only one possible linear time solution.
Proceed vertices one by one. After we have processed first i - 1 vertices (v1, v2, ..., vi - 1) we would like to keep a way to dirstibute them among ki teams T1, T2, ..., Tki that will satisfy all the requirements. When we add a new node vi we should find any component Tj, such that there is no node 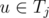 and
and 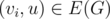 . Assuming
. Assuming 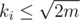 this can be done in
this can be done in 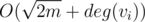 time by simply making an array of boolean marks and traversing the list of all neighbours. If there is no such Tj, we consider ki + 1 = ki + 1, i.e. we create a new set for this vertex. However, we actually do not need this
time by simply making an array of boolean marks and traversing the list of all neighbours. If there is no such Tj, we consider ki + 1 = ki + 1, i.e. we create a new set for this vertex. However, we actually do not need this 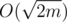 time to set up the boolean array, as we can use only one array and mark it with a number of iteration instead of a simple \emph{true}. Thus, we set marks in O(deg(vi)) time and then simply consider all sets one by one till we find first valid. Obviously, we will skip no more then deg(vi) sets till we find first possible match, thus the running time will be O(deg(vi)) and the total running time is O(n + m).
time to set up the boolean array, as we can use only one array and mark it with a number of iteration instead of a simple \emph{true}. Thus, we set marks in O(deg(vi)) time and then simply consider all sets one by one till we find first valid. Obviously, we will skip no more then deg(vi) sets till we find first possible match, thus the running time will be O(deg(vi)) and the total running time is O(n + m).
Problem D. The Sting.
First of all we would like to slightly change how we treat a bet. Define ci = ai + bi. Now, if we accept the i-th bet we immediately take bi and then pay back ci in case this bet plays. Define as A some subset of bets, 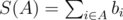 , i.e. the total profit we get from subset A. Define as L(A) the total amount we will have to pay in case the game result will be "team looses", i.e.
, i.e. the total profit we get from subset A. Define as L(A) the total amount we will have to pay in case the game result will be "team looses", i.e.  . Similarly we introduce D(A) and W(A). Now, the profit of Ostap if he accepts subset A is S(A) - max(L(A), D(A), W(A)).
. Similarly we introduce D(A) and W(A). Now, the profit of Ostap if he accepts subset A is S(A) - max(L(A), D(A), W(A)).
In this form it's not clear how to solve the problem as we simultaneously want to maximize S(A) from the one hand, but minimize maximum from the other hand. If we fix the value max(L(A), D(A), W(A)) = k the problem will be, what is the maximum possible sum of bi if we pick some subset of "loose" ("draw", "win") bets with the sum of ci not exceeding k. Such values 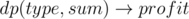 can be computed for each outcome independetly using knapsack dynamic programming. The complexity of such solution is O(nL), where
can be computed for each outcome independetly using knapsack dynamic programming. The complexity of such solution is O(nL), where  .
.
Problem E. Random Value of Mode.
To start with consider O(n2) dynamic programming solution. Let dpleft(i, j) be the optimum expected value if Gleb has visited all shops on segment from i to j inclusive and is now standing near the shop i. In the same way dpright(i, j) as the optimum expected value if segment from i to j was visited and Gleb stands near shop j.
We are not going to consider all the formulas there, but here is how we compute dpleft(i, j), picking the minimum of two possibilities go left or go right:
,
To move forward we should have a guess that if there are no pi = 0 we are going to visit many shops with a really small probability. Indeed, the smallest possible positive probability is one percent, that is 0.01 which is pretty large. The probability to visit k shops with pi > 0 and not find a proper coat is 0.99k, that for k = 5000 is about 1.5·10 - 22. Assuming ti ≤ 1000 and n ≤ 300 000 the time required to visit the whole mall is not greater than 109, thus for k = 5000 it will affect the answer by less than 10 - 12. Actually, assuming we only need relative error k = 3000 will be sufficient.
Now, we find no more than k shops with pi > 0 and i < x and no more than k shops with pi > 0 and i > x. Compress shops with pi = 0 between them and compute quaratic dynamic programming. The overall running time will be O(n + k2).
Problem F. Measure Twice, Divide Once.
We need to assign each vertex a single positive integer xv~--- the number of the process iteration when this vertex will be deleted. For the reason that will be clear soon we will consider xv = 0 to stand for the last iteration, i.e. the greater value of x correspond to the earlier iterations of the process. One can prove that an assignment of positive integers xv is correct if and only if for any two vertices u and v such that xu = xv the maximum value of xw for all w on the path in the tree from u to v is greater than xu. That is necessary and sufficient condition for any two vertices removed during one iteration to be in different components.
Pick any node as a root of the tree. Denote as C(v) the set of direct children of v and as S(v)~--- the subtree of node v. Now, after we set values of x in a subtree v we only care about different values of xu, 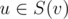 that are not "closed", i.e. there is no value greater between the corresponding node and the root of a subtree (node v). Denote as d(v, mask) boolean value whether it's possible to set values of x in a subtree of node v to have values mask unclosed. Because of centroid decomposition we know there is no need to use values of x greater than
that are not "closed", i.e. there is no value greater between the corresponding node and the root of a subtree (node v). Denote as d(v, mask) boolean value whether it's possible to set values of x in a subtree of node v to have values mask unclosed. Because of centroid decomposition we know there is no need to use values of x greater than  , thus there are no more than
, thus there are no more than 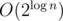 different values of mask, i.e. O(n). d(v, mask) can be recomputed if we know d(u, mask) for all
different values of mask, i.e. O(n). d(v, mask) can be recomputed if we know d(u, mask) for all 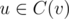 in O(n3) time. Indeed, if one child ui uses mask mi we know:-
in O(n3) time. Indeed, if one child ui uses mask mi we know:-
- We have to set xv greater than any i that occurs in more than one mask.
- We can set xv to any i that doesn't occur in any mi.
- If we set xv = i, all j < i are set to 0 in m.
Now, one can notices that according to the following process if mask m1 is a submask of m2 it is always better lexicographically smaller than mask m2 it always affects the result in a better way. Now, we claim that if for some subtree v we consider the minimum possible m, such that d(v, m) is true, for each m1 > m there exists m2 submask of m1 such that d(v, m2) is true. Indeed, consider the first (highest) bit i where m and m1 differ. Because m1 is greater than m it will have 1 at this position, while m will have 0. If there is no 1 in m anymore it is itself a submask of m1, otherwise, this means xv < i. We can set xv = i and obtain a submask of m1.
The above means we should only care about obtaining a lexicographically smallest mask for each subtree S(v). To do this we use the above rules to merge the results in all . This can be easily done in  or in O(n) if one uses a lot of bitwise operations.
or in O(n) if one uses a lot of bitwise operations.


