


Background
The idea of this article originated from a contest (Petrozavodsk Summer-2016. Petr Mitrichev Contest 14), which I believe is attributed to Petr. In this contest, an interesting problem is proposed:
"Cosider this process: pick a random number ni uniformly at random between 10 and 100. Generate ni random points with integer coordinates, picking each coordinate independently and uniformly at random from all integers between 0 and 109, inclusive. Find the convex hull of those points.
Now you are given 10000 polygons generated by this program. For each polygon, you need to guess the value ni that was used for generating it.
Your answer will be accepted if the average (over all 10000 hulls) absolute difference between the natural logarithm of your guess and the natural logarithm of the true ni is below 0.2."
Unfortunately, I didn't really manage to work this one out during our 5-hour training session. After the training is over, however, I have tried to read the solution program written by Petr, which looks like the following:
//...
public class h {
static int[] splitBy = new int[] {/* 1000 seemingly-random elements */};
static double[] splitVal = new double[] {/* another 1000 seemingly-arbitrarily-chosen elements */};
static double[] adjYes = new double[] {/* Another 1000 seemingly-stochastically-generated elements */};
static double[] adjNo = new double[] {/* ANOTHER 1000 seemingly-... elements, I'm really at my wit's end */};
public static void main(String[] args) {
/* Process the convex hull, so that
key.data[0] is the average length of the convex hull to four sides of the square border
(i.e. (0, 0) - (1E9, 1E9));
key.data[1] is the area of the hull;
key.data[2] is the number of points on the hull.
*/
double res = 0;
for (int ti = 0; ti < splitBy.length; ++ti) {
if (key.data[splitBy[ti]] >= splitVal[ti]) {
res += adjYes[ti];
} else {
res += adjNo[ti];
}
}
int guess = (int) Math.round (res);
if (guess < 10) guess = 10;
if (guess > 100) guess = 100;
pw.println (guess);
}
}
While I was struggling to understand where all the "magic numbers" come from, I do realize that the whole program is somewhat akin to a "features to output" black box, which is extensively studied in machine learning. So, I have made my own attempt at building a learner that can solve the above problem.
A lightweight learner
Apparently, most online judge simply do not support scikit-learn or tensorflow, which are common machine learning libraries in Python. (Or an 100MB model file, the imagination of 500 users with an 100MB file each makes my head ache. And yes, there are even multiple submissions.) Therefore, some handcraft code is necessary to implement a learner that is easy to use.
As a university student, I, unfortunately, do not know much about machine learning, especially in regression, where even fewer methods are adaptable. However, I somehow got particularly attracted by the idea of the neural network after some googling, both because its wide application and its simplicity, especially due to the fact that its core code can be written with about 60 lines. I will introduce some of its basic mechanism below.
Understand neural network in one section
A neural network, naturally, is made up of neurons. A neuron in a neural network, by definition, is something that maps an input vector x to an output y. Specifically, a certain neuron consists of a weight vector w with the same length as x, a bias constant b, and some mapping function f, and we compute its output with the following simple formula:
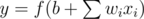
In general, we tend to use the sigmoid function as f for reasons we will see below. Other values are "tweakable" parts of a neuron that will be adjusted according to the data, as is the process of learning.
Turning back to the topic of a neural network, it will contain several layers of neurons, where each layer reads the input from the previous layer (the first layer, of course, from the input) and outputs the result as the inputs of the next layer (or the final answer, if it is the last layer). As such, it will not be very difficult to implement a neuron network if all parameters are given, since copying the formula above will suffice.
However, how do we know what these parameters are, anyway? Well, one common way is called "gradient descent". With this method, you imagine a hyperspace with each parameter of a neuron network as an axis. Then, each point in this hyperspace actually represents a neuron network. If we can give every point (neuron network) an error value that indicates how far it is away from the ideal model, then we can simply pick a random point and begin walking (descending) towards a direction where the error value is decreasing. In the end we will reach a point where the error value is very small, which represents a good neural network that we want. As you can guess, in practice we generate a random data (a random convex hull, regarding the problem above) and dictate the error value to be the square of the difference between the output of the network and the real answer, and walk one "step" towards the smaller error value. If sufficient data is generated, then this "stochastic gradient descent" method should approximately be equal to "gradient descent".
Now I can claim due to the fact that the sigmoid function is differentiable at every point, with some difficult-to-understand maths we can actually figure out the best direction in which the error value decreases the fastest without actually trying to explore around. This extensively studied field is named Backpropagation, and simply copying the result from wikipedia is sufficient for us to build a neural network ourselves.
I will show my code regarding the aforementioned problem below:
#include <bits/stdc++.h>
//ft inputs, n layers, m neurons per layer.
template <int ft = 3, int n = 2, int m = 3, int MAXDATA = 100000>
struct network {
double wp[n][m][ft/* or m, if larger */], bp[n][m], w[m], b, val[n][m], del[n][m], avg[ft + 1], sig[ft + 1];
network () {
std::mt19937_64 mt (time (0));
std::uniform_real_distribution <double> urdn (0, 2 * sqrt (m));
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) for (int k = 0; k < (i ? m : ft); ++k)
wp[i][j][k] = urdn (mt);
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) bp[i][j] = urdn (mt);
for (int i = 0; i < m; ++i) w[i] = urdn (mt); b = urdn (mt);
for (int i = 0; i < ft + 1; ++i) avg[i] = sig[i] = 0;
}
double compute (double *x) {
for (int j = 0; j < m; ++j) {
val[0][j] = bp[0][j]; for (int k = 0; k < ft; ++k) val[0][j] += wp[0][j][k] * x[k];
val[0][j] = 1 / (1 + exp (-val[0][j]));
}
for (int i = 1; i < n; ++i) for (int j = 0; j < m; ++j) {
val[i][j] = bp[i][j]; for (int k = 0; k < m; ++k) val[i][j] += wp[i][j][k] * val[i - 1][k];
val[i][j] = 1 / (1 + exp (-val[i][j]));
}
double res = b; for (int i = 0; i < m; ++i) res += val[n - 1][i] * w[i];
// return 1 / (1 + exp (-res));
return res;
}
void desc (double *x, double t, double eta) {
double o = compute (x), delo = (o - t); // * o * (1 - o)
for (int j = 0; j < m; ++j) del[n - 1][j] = w[j] * delo * val[n - 1][j] * (1 - val[n - 1][j]);
for (int i = n - 2; i >= 0; --i) for (int j = 0; j < m; ++j) {
del[i][j] = 0; for (int k = 0; k < m; ++k)
del[i][j] += wp[i + 1][k][j] * del[i + 1][k] * val[i][j] * (1 - val[i][j]);
}
for (int j = 0; j < m; ++j) bp[0][j] -= eta * del[0][j];
for (int j = 0; j < m; ++j) for (int k = 0; k < ft; ++k) wp[0][j][k] -= eta * del[0][j] * x[k];
for (int i = 1; i < n; ++i) for (int j = 0; j < m; ++j) bp[i][j] -= eta * del[i][j];
for (int i = 1; i < n; ++i) for (int j = 0; j < m; ++j) for (int k = 0; k < m; ++k)
wp[i][j][k] -= eta * del[i][j] * val[i - 1][k];
b -= eta * delo;
// for (int i = 0; i < m; ++i) w[i] -= eta * delo * o * (1 - o) * val[i];
for (int i = 0; i < m; ++i) w[i] -= eta * delo * val[n - 1][i];
}
void train (double data[MAXDATA][ft + 1], int dn, int epoch, double eta) {
for (int i = 0; i < ft + 1; ++i) for (int j = 0; j < dn; ++j) avg[i] += data[j][i];
for (int i = 0; i < ft + 1; ++i) avg[i] /= dn;
for (int i = 0; i < ft + 1; ++i) for (int j = 0; j < dn; ++j)
sig[i] += (data[j][i] - avg[i]) * (data[j][i] - avg[i]);
for (int i = 0; i < ft + 1; ++i) sig[i] = sqrt (sig[i] / dn);
for (int i = 0; i < ft + 1; ++i) for (int j = 0; j < dn; ++j)
data[j][i] = (data[j][i] - avg[i]) / sig[i];
for (int cnt = 0; cnt < epoch; ++cnt) for (int test = 0; test < dn; ++test)
desc (data[test], data[test][ft], eta);
}
double predict (double *x) {
for (int i = 0; i < ft; ++i) x[i] = (x[i] - avg[i]) / sig[i];
return compute (x) * sig[ft] + avg[ft];
}
std::string to_string () {
std::ostringstream os; os << std::fixed << std::setprecision (16);
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) for (int k = 0; k < (i ? m : ft); ++k)
os << wp[i][j][k] << " ";
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) os << bp[i][j] << " ";
for (int i = 0; i < m; ++i) os << w[i] << " "; os << b << " ";
for (int i = 0; i < ft + 1; ++i) os << avg[i] << " ";
for (int i = 0; i < ft + 1; ++i) os << sig[i] << " ";
return os.str ();
}
void read (const std::string &str) {
std::istringstream is (str);
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) for (int k = 0; k < (i ? m : ft); ++k)
is >> wp[i][j][k];
for (int i = 0; i < n; ++i) for (int j = 0; j < m; ++j) is >> bp[i][j];
for (int i = 0; i < m; ++i) is >> w[i]; is >> b;
for (int i = 0; i < ft + 1; ++i) is >> avg[i];
for (int i = 0; i < ft + 1; ++i) is >> sig[i];
}
};
#define cd const double &
const double EPS = 1E-8, PI = acos (-1);
int sgn (cd x) { return x < -EPS ? -1 : x > EPS; }
int cmp (cd x, cd y) { return sgn (x - y); }
double sqr (cd x) { return x * x; }
#define cp const point &
struct point {
double x, y;
explicit point (cd x = 0, cd y = 0) : x (x), y (y) {}
int dim () const { return sgn (y) == 0 ? sgn (x) < 0 : sgn (y) < 0; }
point unit () const { double l = sqrt (x * x + y * y); return point (x / l, y / l); }
//counter-clockwise
point rot90 () const { return point (-y, x); }
//clockwise
point _rot90 () const { return point (y, -x); }
point rot (cd t) const {
double c = cos (t), s = sin (t);
return point (x * c - y * s, x * s + y * c); } };
bool operator == (cp a, cp b) { return cmp (a.x, b.x) == 0 && cmp (a.y, b.y) == 0; }
bool operator != (cp a, cp b) { return cmp (a.x, b.x) != 0 || cmp (a.y, b.y) != 0; }
bool operator < (cp a, cp b) { return (cmp (a.x, b.x) == 0) ? cmp (a.y, b.y) < 0 : cmp (a.x, b.x) < 0; }
point operator - (cp a) { return point (-a.x, -a.y); }
point operator + (cp a, cp b) { return point (a.x + b.x, a.y + b.y); }
point operator - (cp a, cp b) { return point (a.x - b.x, a.y - b.y); }
point operator * (cp a, cd b) { return point (a.x * b, a.y * b); }
point operator / (cp a, cd b) { return point (a.x / b, a.y / b); }
double dot (cp a, cp b) { return a.x * b.x + a.y * b.y; }
double det (cp a, cp b) { return a.x * b.y - a.y * b.x; }
double dis2 (cp a, cp b = point ()) { return sqr (a.x - b.x) + sqr (a.y - b.y); }
double dis (cp a, cp b = point ()) { return sqrt (dis2 (a, b)); }
bool turn_left (cp a, cp b, cp c) { return sgn (det (b - a, c - a)) >= 0; }
std::vector <point> convex_hull (std::vector <point> a) {
int cnt = 0; std::sort (a.begin (), a.end ());
std::vector <point> ret (a.size () << 1, point ());
for (int i = 0; i < (int) a.size (); ++i) {
while (cnt > 1 && turn_left (ret[cnt - 2], a[i], ret[cnt - 1])) --cnt;
ret[cnt++] = a[i]; }
int fixed = cnt;
for (int i = (int) a.size () - 1; i >= 0; --i) {
while (cnt > fixed && turn_left (ret[cnt - 2], a[i], ret[cnt - 1])) --cnt;
ret[cnt++] = a[i]; }
return std::vector <point> (ret.begin (), ret.begin () + cnt - 1); }
const int FT = 10, N = 3, M = 4, DATA = 5000000;
network <FT, N, M, DATA> nt;
void process (double *data, const std::vector <point> &cv) {
data[0] = 0; data[1] = cv.size ();
data[2] = 1E9; data[3] = 1E9;
data[4] = 1E9; data[5] = 1E9;
data[6] = 0; data[7] = 0; data[8] = 0; data[9] = 1E18;
for (int i = 0; i < cv.size (); ++i) {
data[0] += det (cv[i], cv[(i + 1) % cv.size ()]);
data[2] = std::min (data[2], cv[i].x);
data[3] = std::min (data[3], cv[i].y);
data[4] = std::min (data[4], 1E9 - cv[i].x);
data[5] = std::min (data[5], 1E9 - cv[i].y);
data[6] += dis (cv[i], cv[(i + 1) % cv.size ()]);
data[7] += dis2 (cv[i], cv[(i + 1) % cv.size ()]);
data[8] = std::max (data[8], dis (cv[i], cv[(i + 1) % cv.size ()]));
data[9] = std::min (data[9], dis (cv[i], cv[(i + 1) % cv.size ()]));
}
}
#ifdef LOCAL
double data[DATA][FT + 1];
void gen_data () {
std::mt19937_64 mt (time (0));
std::uniform_int_distribution <int> un (10, 100), uid (0, 1000000000);
for (int cnt = 0; cnt < DATA; ++cnt) {
int n = un (mt);
std::vector <point> pp, cv; pp.resize (n);
for (int i = 0; i < n; ++i) pp[i] = point (uid (mt), uid (mt));
cv = convex_hull (pp); process (data[cnt], cv); data[cnt][FT] = log (n);
}
}
void train () {
gen_data ();
std::cout << "Generated." << std::endl;
nt.train (data, DATA, 10, 0.01);
std::cout << "Trained." << std::endl;
double err = 0;
gen_data ();
for (int cnt = 0; cnt < DATA; ++cnt) {
int ans = std::max (std::min ((int) round (exp (nt.predict (data[cnt]))), 100), 10), real = round (exp (data[cnt][FT]));
err += std::abs (log (ans) - data[cnt][FT]);
}
std::cout << "Error: " << std::fixed << std::setprecision (10) << err / DATA << "\n";
std::cout << nt.to_string () << "\n";
}
#endif
//Error: 0.1931354718
const std::string str = "-1.3935330713026979 -1.6855399067812094 0.0080830627163314 -0.0456935204722265 -0.0134075027893312 -0.0225523456635180 -0.0063385628290917 -0.0539803586714664 0.0285615302448615 -0.0494911914462167 4.8156449644606729 1.4141506946578808 0.0609360500524733 -0.0003939198727380 0.0974573799765315 -0.0237353370691478 1.8823428209722266 -0.0253047473923868 -0.4320535560737181 -0.0465107808811315 3.9087941887190509 1.1605608005526673 -0.0055668920418296 0.0435006757439702 0.0168235313881814 0.0201162039464427 0.0005391585736898 -0.0281508733844095 0.0333519586644446 0.0138573643228493 -2.2584700896151499 -1.4482223377667529 -0.0087279280693970 -0.0067154696151271 0.0931324993850075 -0.0246202499367100 0.1202642385880566 0.0742084099697175 -0.0576728791494071 0.0048743269227391 0.7245500807425441 1.1451918581258713 1.5362660419598355 2.2247337510533445 -1.3361750107632056 -0.6202098232180651 2.6126102753644820 -2.6224614441649430 -1.6239623067583704 0.0103356949589122 2.3160496100308006 0.7983423380182993 2.7402717506451184 -0.4696450730651245 -5.9647497198434687 2.5913155713930167 -0.7492492475439734 -2.6902420797953686 -1.8925204583122668 4.1461581213116920 -1.3283582467170971 1.6545505567705860 -1.8337202201037788 5.9739259421367326 -0.0514667439768578 5.4697553418504725 0.4195708475958704 -8.2367354144820037 -2.7322241686093887 1.5109443918819332 3.4841054954004966 0.4931178741138817 -5.7924156962977023 1.3728086432563174 -3.0935727146312852 -2.1233242848314902 2.7215008891274142 -2.1566137088986088 -2.4630818715655334 -1.2871925059203080 -3.6940220894585978 -4.0749736367183296 0.4396854435207839 -0.5672193348210693 -1.8759334759019322 -1.8112273299081239 1.5777769313392334 0.6556212919805925 -0.6391849809511954 1549414420922584064.0000000000000000 10.0076592000000009 24937256.4471242018043995 24942299.7631161995232105 24933933.8955707997083664 24907107.2519301995635033 3354856368.0634231567382812 1588693346300253696.0000000000000000 716306964.7579888105392456 91336248.0137662440538406 3.8563280309383297 243867607280379392.0000000000000000 2.2982303054101396 34087367.3454539999365807 34090994.8023483082652092 34100829.3740548193454742 33993881.5109920650720596 263817168.3726958632469177 361286974354604864.0000000000000000 129441292.3767285346984863 67804188.7760041356086731 0.5986632816451091";
void run () {
nt.read (str);
std::ios::sync_with_stdio (0);
int N; std::cin >> N;
for (int i = 0; i < N; ++i) {
int cnt; std::cin >> cnt;
std::vector <point> cv (cnt, point ());
for (int j = 0; j < cnt; ++j) std::cin >> cv[j].x >> cv[j].y;
static double test[FT]; process (test, cv);
std::cout << std::max (std::min ((int) round (exp (nt.predict (test))), 100), 10) << "\n";
}
}
int main () {
#ifdef LOCAL
train ();
#else
run ();
#endif
}
As we can see, the core code of a neuron network takes only about 60 lines to finish (which I believe is the reason why I can never learn how to code the infamous link-cut tree — the implementation of my brain just got beaten by sheer line numbers), and its output as parameters is significantly less than most models. These are the reasons that I think the neuron network may be one popular ML methods for competitive programming.
Extension to other problems
I believe I have seen a few similar problems before, such as give you 10 numbers generated uniformly from [1, n] and let you guess what value n is. However, as of now I cannot find any more examples. Some help is appreciated if you happen to know some similar problems.
Conclusion
Now that hopefully you have known something about machine learning, do hurry to solve all the problems...Well, at least, before all the "nefarious" problem makers know the tricks and even find better features than you can.
P.S. What approach would you use to solve the "convex hull guessing" problem? Do you know any similar problems? Do let me know with comments, your help is most appreciated!
Update: Since some of you challenged that Petr's solution is specifically made for the judge's test cases, I compiled the code and tested it against my random data. It would appear that his solution achieves ~0.195 error, which is below the threshold and thus satisfies the requirement. For those interested I have pasted the original code at here. Be warned though, it is very long.


