В задаче требовалось выяснить, может ли кассир выдать сдачу всем посетителям кинотеатра, если билет стоит 25 рублей, у посетителей купюры номиналом 25, 50 и 100 и в кассе изначально нет денег.
Рассмотрим 3 различных случая.
- Если у посетителя 25 рублей, то сдачу ему давать не нужно.
- Если у посетителя 50 рублей, то мы должны дать ему 25 рублей сдачи.
- Если у посетителя 100 рублей, то мы должны дать ему 75 рублей сдачи. Это можно сделать двумя способами. 75=25+50 и 75=25+25+25. Заметим, что всегда выгодно попробовать сначала первый способ, а потом второй. Это верно потому, что купюры номиналом 25 рублей могут быть использован как для выдачи сдачи на 50 рублей, так и на 100 рублей, а сами купюры номиналом 50 рублей могут использоваться только для выдачи сдачи на 100 рублей.
Таким образом решение – поддерживать количество купюр номиналом 25 и 50 рублей и при выдаче сдачи на 100 рублей действовать жадно – сначала пробовать выдать 25+50 рублей, а иначе 25+25+25 рублей.
В задаче требовалось выяснить наибольшее число, которое можно написать, используя заданное количество краски, если на каждую цифру тратится также известное количество краски.
Поскольку чем длиннее число, тем оно больше, нам выгодно написать число наибольшей длины. Для этого выберем цифру, на которую нужно меньше всего краски. Пусть количество краски для написания этой цифры d равно x, а всего у нас есть v литров краски. Тогда мы можем написать число длины 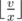 .
.
Таким образом мы выяснили длину числа, пусть она равна len. Запишем промежуточный результат – строку длины len, состоящую из цифр d. У нас в запасе еще осталось v–len·x краски. Чтобы улучшить ответ, будем идти от начала числа и пробовать заменить каждую цифру на максимально возможную. Это верно потому, что числа одинаковой длины сравниваются сначала по старшим разрядам. Среди цифр больше текущей выбираем максимальную среди тех, на которую хватает краски, и обновляем текущее количество краски и ответ.
Если ответ длины 0, то нужно вывести -1.
В задаче требовалось определить, сколько игр нужно сыграть, чтобы все игроки остались довольны и сыграли как минимум столько игр, сколько они хотят.
Пусть ответ – это x игр. Заметим, что max(a1, a2, …, an) ≤ x. Тогда i-ый игрок может в x–ai играх быть ведущим. Если просуммировать по всем игрокам, то получим 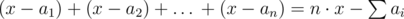 — это количество игр, в которых игроки согласны быть ведущими. Это число должно быть не меньше x — нашего ответа.
— это количество игр, в которых игроки согласны быть ведущими. Это число должно быть не меньше x — нашего ответа.
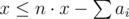
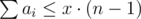
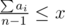
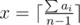
Также следует не забыть требование, что max(a1, a2, …, an) ≤ x.
В задаче требовалось выяснить, какое минимальное количество яблок нужно удалить, чтобы сделать дерево сбалансированным.
Заметим, что если мы знаем значение в корне, то знаем значения во всех остальных вершинах. Значение в листе равняется значению в корне, поделенному на произведение степеней вершин на пути от корня до листа.
Для каждой вершины посчитаем величину di — какое минимальное число (не ноль) в ней должно быть записано, чтобы дерево по-прежнему могло быть сбалансированным. Для листьев di = 1, для остальных вершин di равен k·lcm(dj1, dj2, ..., djk), где j1, j2, ..., jk — сыновья вершины i. Также посчитаем величину si — сумму в поддереве вершины i. Все это можно сделать за один обход в глубину из корня дерева.
Вторым обходом в глубину мы можем посчитать для каждой вершины максимальное число, которое мы в нее можем записать, так чтобы удовлетворить ограничениям. А именно, пусть дана вершина i и k ее сыновей j1, j2, ..., jk. Тогда если m = min(sj1, sj2, ..., sjk), а 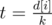 — минимальное число, которое мы можем записать в сыновей вершины i, нам выгодно записать в сыновей вершины i числа
— минимальное число, которое мы можем записать в сыновей вершины i, нам выгодно записать в сыновей вершины i числа 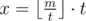 . Остатки, а именно
. Остатки, а именно  , добавим к ответу.
, добавим к ответу.
В этой задаче на структуры данных требовалось использовать корневую эвристику или, по-другому, sqrt-декомпозицию.
Первый шаг решения состоял в том, чтобы разделить множества на легкие и тяжелые. Легкими назовем множества, которые содержат меньше  элементов, а тяжелыми все остальные.
элементов, а тяжелыми все остальные.
Ключевое наблюдение. В любом легком множестве меньше элементов, а количество тяжелых множеств также не превосходит , так как есть ограничение на сумму размеров множеств.
Чтобы эффективно отвечать на запросы, для каждого множества (как легкого, так и тяжелого) посчитаем размеры его пересечения со всеми тяжелыми множествами. Это можно сделать за время и память 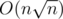 . Для каждого тяжелого множества создадим булевский массив размера O(n), в i-ой ячейке которого будем хранить, сколько элементов i в этом множестве. Затем для каждого элемента и каждого тяжелого множества будем за O(1) проверять, содержится ли элемент в тяжелом множестве.
. Для каждого тяжелого множества создадим булевский массив размера O(n), в i-ой ячейке которого будем хранить, сколько элементов i в этом множестве. Затем для каждого элемента и каждого тяжелого множества будем за O(1) проверять, содержится ли элемент в тяжелом множестве.
Теперь рассмотрим 4 возможных запроса:
Добавление к легкому множеству. Пройдем по всем числам множества и к каждому добавим нужное значение. Дальше пройдем по всем тяжелым множествам и к каждому добавим (размер пересечения * значение в запросе). Время работы 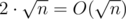 .
.
Добавление к тяжелому множеству. Просто увеличим счетчик для данного тяжелого множества на значение в запросе. Время работы O(1).
Ответ на запрос для легкого множества. Проходим по всем числам, добавляем значения к ответу. Затем проходим по всем тяжелым множествам и добавляем к ответу (добавление для данного тяжелого множества * размер пересечения со множеством в запросе). Время работы .
Ответ на запрос для тяжелого множества. Берем уже посчитанный ответ, затем проходим по тяжелым множествам и добавляем (добавление для данного тяжелого множества * размер пересечения со множеством в запросе). Время работы .
Итого, если у нас O(n) запросов, то суммарное время работы .
В задаче требовалось найти количество пар непересекающихся путей из левого верхнего в правый нижний угол таблицы. Для этого можно воспользоваться следующей леммой. Спасибо rng_58 за ссылку. А именно, если переформулировать применительно к нашему случаю, то лемма утверждает, что если есть множества начальных A = {a1, a2} и конечных B = {b1, b2} точек, то ответ можно посчитать, как следующий определитель:
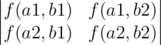
где
f(x, y) — количество путей из точки
x в точку
y. Эту величину уже можно посчитать квадратной динамикой.
Наконец, заметим, что для того, чтобы свести исходную задачу к этой, нам нужно сделать пути, которые не имеют совсем совпадающих точек — в исходной задаче разрешаются пересечения в первой и последней точках пути. Для этого в качестве множеств A и B мы можем взять точки A = {(0, 1), (1, 0)} и B = {(n - 2, m - 1), (n - 1, m - 2)}
Давайте сначала построим простое решение этой задачи, а затем попробуем решить ее эффективно, учитывая данные ограничения.
Для каждой вершины найдем список наиболее удаленных вершин. Найдем вершины на пересечении путей от текущей вершины до каждой вершины из списка, в которых нет монастырей. Если мы удалим любую из этих вершин, то каждая вершина из списка будет недостижима из текущего монастыря. У каждой вершины из этого пересечения увеличим счетчик на единицу. Тогда ответ на задачу – максимум из счетчиков для всех вершин и количество таких максимумов.
Теперь решим задачу более эффективно, но используя ту же идею. Подвесим дерево за корень. Будем для каждой вершины искать список наиболее удаленных вершин только в ее поддереве. При обходе дерева в глубину из каждой вершины возвращаем наибольшую глубину в поддереве и номер вершины, на которой он достигается. Среди всех сыновей вершины выберем максимум из глубин. Если максимум достигается один раз, то вернем из текущей вершины тот же ответ, что был возвращен из сына. Если максимум достигается более одного раза, то вернем из текущей вершины номер текущей вершины. По сути, таким образом мы находим LCA всех наиболее удаленных от текущей вершины вершин. Перед выходом из вершины прибавляем единицу на отрезке от текущей вершины до найденного LCA. Это можно сделать, если хранить эйлеров обход графа и использовать дерево отрезков для прибавления на отрезке.
Наконец, последний этап решения задачи – решить ее для случая, когда наиболее удаленная вершина или их список находятся необязательно в поддереве текущей вершины. Для решения этой подзадачи используем ту же идею, которая используется при нахождении максимального по длине пути в дереве. Для каждой вершины будем хранить 3 максимума – 3 наиболее удаленные вершины в ее поддереве. Когда мы спускаемся в какое-то поддерево, то передаем заодно и 2 оставшихся максимума. Таким образом, находясь в любой вершине, мы можем решить, существует ли путь не в поддереве (то есть уходящий наверх) такой же или большей длины. Если в поддереве и вне его пути одинаковой длины, то это означает, что для пилигрима из текущего монастыря всегда найдется хотя бы один путь, какой бы город не удалили. Если одна из величин больше, то мы выбираем нужный отрезок в эйлеровом обходе дерева и увеличиваем на нем значение на единицу. Случай, когда есть несколько путей (то есть хотя бы 2) вне поддерева одинаковой максимальной длины, обрабатывается аналогично такому же случаю в поддереве.
Поскольку дерево отрезков может отвечать на запрос за O(logN) времени, а задачу LCA можно эффективно решить методом двоичного подъема за то же время, то затраты времени и памяти равны O(NlogN).














