


Hi Codeforces!
Programming Club, IIT Indore and Euristica 2018 are proud to present our flagship event, Divide By Zero! The contest will take place on Saturday, 7th April at 9:35PM IST.

Prizes : Codeforces T-shirts for top 15 participants overall and top 15 participants in India.
Thanks to the following people for making the round possible :
apoorv_kulsh, arnabsamanta, AakashHanda, Vicennial, kr_abhinav, 7dan, rohitranjan017 and myself for setting the problems.
usaxena95 and killer_bee for their help with the problems.
vintage_Vlad_Makeev for coordinating throughout the round.
fcspartakm and arsor for translating the problems.
KAN for his invaluable help with the round.
MikeMirzayanov for the amazing Codeforces and Polygon platforms.
There are 8 problems, and 2.5 hours to solve them. The points distribution will be updated later.
Euristica, sponsored by Arcesium is the inaugral Programming festival of IIT Indore. It comprised of 10 events this year, spanning across various domains like Competitive Programming, Application Development, Cyber Security and Machine Learning. For more information, visit www.euristica.in .
Hope you guys enjoy the contest! See you on the leaderboard!
UPD: The scoring distribution is 500-1000-1500-2000-2250-2500-3000-3500.
UPD 2: Do give your feedback here : https://goo.gl/forms/xbsdMxnkA3XsG4092. Would love to hear your feedback, since that would help us get better!
We hope you guys enjoyed the contest and found the problems interesting.
UPD 3: You can find the editorial here.
Here are the list of winners who won Tshirts. We will contact you guys soon. Congrats!
Overall Top 15:
Top 15 in India:






I think it will be funny, thank you.
First palindrome lucky round of 2018! Sounds good
All Divide By Zero rounds:
--------------------------------------
2013
2014
2015
2016
2017
2018
All number is not able to divide by zero except these number 2013,2014,2015,2016,2017 and 2018.
So the divisors of zero are increasing year by year. :D :D :D
I hope one day i will get a T-shirt from Codeforces, I think it will be the best gift ever
suppose the best gift ever will be the invitation from a good company)))
Yeah , it's also a good gift
Hope all the problem statements will be short and Contest will be enjoyable. :) :)
We have solved A & C & D of last Div.2 Round[#473] in videos
A : https://youtu.be/CClZZPYJmaI
C : https://youtu.be/bvDYHy9ESnY
D : https://youtu.be/d3iyS6rnuEM
Wait us for more videos after contest
https://www.youtube.com/channel/UCmWvb73kIq_oRThWd05Mtfg
You better create a blog post to invite to your channel instead of irrelevant comment here.
It's okay , it's very good idea
I just visited your channel. You should have mentioned that your videos are in Arabic language.
Okay, you are right.
Rated?
It always is, unless stated otherwise.
See you in the leadboard ! So let's paying for a miracle
I must choose "Divide by Zero or Manchester's derby!".
Should I watch IPL or participate in the contest? Help me!
If you will get any help. Please share with me!
Participating in a programming contest is better than watching a 'fixed match'. I think.
The problems distribution?
What's wrong about the problem statement?
Hack page is not loading for me
Reloading the page is helpful
And me.
I have just installed a plug-in that has to be an alternative of adobe flash player, but no response.
Why it's not as the Educational rounds? I'm talking about the way of displaying the source code for hacking.
Please MikeMirzayanov, do something for this.
In the usual codeforces round, you cannot copy others' codes to try. It is so easy and less unseccessful hacking attempt. However, in the edu round, there is no award if you have a successful hacking attempt, therefore, you can copy it and try
OK, not bad. But isn't there another way to display the source code with that property and without depending on adobe flash player?
Anyway, Thank you for the explanation.
I used to face this problem on Google Chrome. Now I use Firefox for hacking, works all the time!
why is it so difficult to check the problem statement for the first task? can I get my hacked attempt points back?
Will the round be rated?
In my opinion, E and F are too standart, maybe they would be better for educational rounds.
Thank you for the round with hacks. It was very interesting!
In problem C, I realized c[0] = c[1] is possible after locked..
How to solve D?
I stored an array of shifts for each level. When type 1 query comes, increase the shift for that level by K. When type 2 query comes, increase the shift for that level by K, and also the shift for the level after by 2k, and after that 4k... to the end of the array (which will be size 63 or something to get max number of elements). When type 3 query comes, find where that node is and go up by dividing by 2. Then you just need to subtract the shifts on each level as you go up. Sample: http://codeforces.com/contest/960/submission/37077181
Okay. Thanks
how to solve B?
If instead of keeping ai and bi, we keep ci= | ai — bi|, then our task is to use k1+k2 operations to reduce the cost. So you'll go through the array, find the maximum and decrease the value by 1. If all the elements are 0 it means that you are in an optimal point and the way to go from here is to add 1 and then decrease 1 to the same position up until you don't have any operations left.
isn't that tle.... finding max value for n and for(k1+k2) operations
O(1000*1000) certainly isn't TLE
thanks man.. i thought i had to be more analytical... i thought about calculating summation(difference) — (k1+k2).....and get a mean from it...then distribute the difference somehow equal to the mean while maintaining k1+k2 operation... it was a bad idea
Correct thinking for a long contest, but for contests that last so short, write anything that works(even though it's not optimal). Cheers
Make a priority queue of the biggest differences between a and b. You can use the greedy approach then : just reduce 1 from the biggest difference that exist (i.e. remove biggest element from pq, reduce it by 1, and add the reduced number to the priority queue)
If the priority queue becomes empty while you still have attempts, the minimum result will just be number of remaining attempts modulo 2.
Why are we always reducing 1 from the biggest difference ? Why can't we reduce 1 from smaller difference ?
since what counts is the square from the difference, it's always the biggest one that will give the biggest reduction : the reduction of a difference d gives a reduction in total points of :
d²-(d-1)²=2d-1
which is an increasing function in d (except for d=0 which is a special case), so it's always better to reduct the biggest difference first.
C?
If you keep a sequence that is all 1's (ie 1 1 1 1 .. 1) the cost is 2^(no of 1's)-1. So you're going to find the largest k so that x>= 2^k -1 and then decrease x by 2^k -1 and add k equal values to your solution. You just have to be careful because the last k values should be larger than the others by at least D.
What is the hack for C?
1000000000 1 is possible
Is there any test that it is impossible to create a desired array so the result is "-1"?
I saw that there isn't any "-1" in this problem!
268435356 1
1000000000 1
Is there an easier solution for E other than 3 dp's?
Centroid Decomposition
You call Centroid Decomp easier than DP? o.O
Yep. Just one improvised DFS will do the trick, and I would have done it, if not for the electricity going off...
Care to expand please?
pls , explain, I am intrigue.
how to solve C ?
the sequence of length n contains 2^n-1 sequences. Hence, the number X can be decomposed into powers of two minus 1. The degrees of the twos in this decomposition are the lengths of the sequences to be used. The degrees of the twos in this decomposition are the lengths of the sequences to be used. Collect on parts. The final sequence will look like:
1,1,1,....,1+(d+1),1+(d+1),....,1+(2*d+1),1+(2*d+1),...where the number of identical terms is equal to the powers of the twos to which we decomposed X.
If the number X cannot be completely decomposed into (2^i-1), then at the end of the answer it is necessary to add Another f distinct numbers, each of which will increase from the previous one by d+1.
Do not forget to take into account that the length of the answer should not exceed 10000
Answer length never excceeds ~465 by this way. I guess we can forget about the last condition.
Why is this simple dfs going TLE?
Source
Consider case
2 100000
1 2 1
2 1 2
1 2 3
and so on. The simple dfs checks 50000 edges 50000 times, making it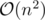 .
.
Putting only case where sum of Vi is 0 in E's pretests...
Anyway, how to solve G? And is there any technique to deal with counting permutation?
Surely it is better to put hard cases in the pretests than real tests... would you rather fail and not be able to fix it??
Holy shit, I added 2 * sum of the values to the answer. RIP good place
I found some pattern. Which included Pascal triangle and Stirling number of the first kind. I generated the required Stirling number with FFT but got WA :/ I think I should have used NTT or maybe there's a lot simpler solution or something.
I am very thankful that this did not change my rank! :P
Anyone knows Pretest 4 of question D
I think it is large numbers or something, I got a run time error that I fixed by increasing the size of my array :P
3 3 1000000000000000000 1 12345 13 3 1000000000000000000
it really feels good to see my mistake in c after 1 min from the end of the contest
Initially the text in the problem did not appear properly, but surprisingly few were able to solve before it appeared properly.
Is NTT a must in problem G or it can be done with FFT? Or does it have some simpler solution?
There is a work around to do FFT under large Modulo. But in this problem it might be risky, as it is time consuming. The idea is -
Lets take C = 30000. Now partition each number A(x) as Ca1i + a2i, and B(x) as Cb1i + b2i. Then convolute P = a1 × b1, Q = a1 × b2, R = a2 × b1, S = a2 × b2.
You can get the final result as (A × B)i ≡ C2pi + C(qi + ri) + si (mod M). It works because no number while doing fft corsses NC2 and fits into precision. But you can't do fft directly into the main polynomial, then a number can be atmost NM2, and that will overflow.
How to solve F?
If you make a new graph so that the edges are the nodes and the nodes are the edges, you'll have exactly the same problem but you'll have to find the longest path of increasing nodes. This is done by going through the nodes in the order of their values and updating a dp[node]=longest increasing sequence ending in node.
ok, but how to "make" the new graph in time?
You don't really have to make it, you can just imagine it(so that the solution is easier). So for the solution you make dp[node]=the longest sequence of increasing edges so that the last edge goes into node. You then take the edges, sort them by their cost, and then if you have edge (u,v), if dp[u]<dp[v] dp[u]=dp[v]+1 else dp[v]=dp[u]+1
The edges are directed and it seems your solution assumes the edges are undirected.
Also, how do you make sure the edges are in the same order as the input?
I don't think there is a way to make it without TL. The edge of a graph having every other vertex connected to vertex 1 has N*N edges in it.
can't there be (10^10)/4 edges in the new graph?
You don't really have to make it, you can just imagine it(so that the solution is easier). So for the solution you make dp[node]=the longest sequence of increasing edges so that the last edge goes into node. You then take the edges, sort them by their cost, and then if you have edge (u,v), if dp[u]<dp[v] dp[u]=dp[v]+1 else dp[v]=dp[u]+1
It seems like dp and maintaining array of sets(couldn't implement it in time though).
Let's loop over the edges in reversed order and assume that the current edge will be the beginning of the path. This way we kinda eliminate the condition about indices being increasing and only have to worry about weights.
Define f(node)(w) as the maximum length of a path if we start at node with an edge of weight w. Let's say the current edge goes from A to B and has weight C. Now we have to update the value of f(A)(B) with the maximum value of f(B)(i) + 1 for i > C. Obviously keeping f(node) in the form of a segment tree, in which the indices are the weights of outgoing edges from node, does the job.
I did all of this but stopped at the f(node) part because the segment tree of each node can be as large as 100000 (number of weights), is it something like dynamic segment tree or a segment tree with coordinate compression?
Thing is, you have to keep f(node)(w) only if there is an outgoing edge from node with weight w, that means O(M) cells in total. So for each node we can simply sort those weights of outgoing edges and then binary search over them to find the proper indices for querying. https://pastebin.com/ZDqFAcNi
Thank you
The point distribution is really unfair. I mean 2500 for F and 3000 for G, when there is a huge difference in difficulty :/
Is it rated?
What is the problem with this code?:(37063101
That's not how you read the arrays :P
Why am I still alive?:((
ans should be long long imo
define int num
How Tricky!!
I don't understand that. "At least one 'a' and one 'b' exist" mean that there must at least one 'A' or one 'B' in the string. Then why not handling the case when there's no 'a' or 'b' will fail?
most people read it fast, so they didn't care.
I mean, the statement should be "At least one 'a' or one 'b' exist", right?
Yes, it must be. see the difference!! https://www.englishforums.com/English/LeastLeast/qrvll/post.htm
Who translated this problem??? This is a huge error in the statement!
And how could one detect this out?
I think there is another Opinion in the same link. see, "At least one "A and B" would mean one or more "A and B" as he writes. But at least one OF A and B means A alone, or B alone, or both."
Sorry, but in the previous reply,"A and B" would mean one or more ("A and B") mean that must be one of A and B in the string. I am very confusionّ! many people have many opinions! But Finally, it should be in the statement in a clear way.
It was me who made a huge error. The "At least one 'a' and one 'b' exist" thing is for the string A and B made, not the string in the input.
G : https://www.youtube.com/watch?v=E-i5nrl4SaI + https://www.quora.com/How-can-I-calculate-the-Stirling-numbers-of-the-first-kind. First was one of our icpc practice (and actually a famous DP practice problem, for a lower constraint), and second was pure googling.
To be honest, I still don't know what's the "First kind of Stirling number". It's always so fun to get a rating that I don't deserve!
Did you use FFT or NTT? If FFT, then how did you handle the mod?
I used NTT.
For handling mods in FFT, look here : http://codeforces.com/blog/entry/48465
I got WA because I couldn't handle mod in FFT :(
Can you explaine please, what is the complexity of your F and how it fit in time?
37057703
Because, I can see you use Divide&Concuer, but at each step use have sort()
And you should have: T(n) = 2*T(n/2) + O(nlogn)
Yeah T(n) = nlg^2n, why not
Haha, I worked out the formula with one (1) Stirling number using the generating function of Stirling numbers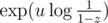 (u generates A or B, z generates N).
(u generates A or B, z generates N).
We want to compute the convolution of sequences \sum_n \left[n, K\right] / n!
Unable to parse markup [type=CF_TEX]
and K = B - 1 with sum of n equal to N - 1, then multiply it by (N - 1)!; in other words, we want the N - 1-th coefficient of fA - 1(x)fB - 1(x), whereSince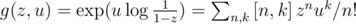 , fK is the K-th coefficient of the Taylor series of g with respect to u. We can get it as
, fK is the K-th coefficient of the Taylor series of g with respect to u. We can get it as
Hey, the product $f_{A-1}(x) f_{B-1}(x)$ is proportional to fA + B - 2(x)... and we can extract the N - 1-th coefficient by differentiating again:
Alternatively, we can use the definition of fA + B - 2 to write it as
Can someone point out what's wrong with my code for B? I still can't figure what did I do wrong.
There is nothing wrong with the code. The idea is just wrong. The right solution is to minimize the max difference, but you just use all your moves to completely remove a difference or two.
Instead, find the max difference, remove or add 1 to it, repeat... Sometimes you'll need to add because you must use all the moves.
Oh. I guess I never saw it like that. I thought removing maxDiff square would have more impact than minimizing it each time. Thanks for your input.
Array of diffs [1,1] has error = 1^2 + 1^2 = 2. While [0,2] has error = 0^2 + 2^2 = 4
37063254 Can anybody tell me what is wrong with this one?:)
since x is int, x*x can overflow. It should 1ll*x*x.
what's the test 18 for E?
Maybe when sum of all vi's is not zero. So that you will have to consider zero length paths.. not sure though
they intentionally put the sum of vi = 0 in the first 17 cases so that if you are counting A(u,u) 2 times your code passes pretests but fails system testing...
Laughed over people who get WA because of long long in B and made myself the same mistake in C. Stupid karma.
You really did intentionally generated pretests in E having zero sum over all vertices to break solution that don't consider zero-length pathes.
Welcome to the faggots club :\
Nice I had written ans=0 and then added numbers in vertexes earlier in the code, very good descent CF one love
@CF :((
My solution of F fails(returns 2) on this test:
3 2
1 2 1
2 3 1
But got accepted! :-?
What's wrong with it?
It says weights of the edges should be in strictly increasing order.
The same here. Realized it during the contest and resubmitted. Facepalm
Problem D was really a very interesting problem.
Get your code Accepted then, sir.
What is the relation between seeing that the problem is interesting and getting it accepted ?
It will make you feel good!
Not that I'm complaining, but this solution 37079339 for G passed all tests (3493 ms), while on test "100000 32768 32768" it works 4461ms in "Run On Server" tab. It is strange not to add such a test, given that 2n - 1 is the worst case for logarithmic exponentiation.
(if anything, I'd complain about such an ambiguous TL, which allows to pass only some of the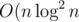 solutions)
solutions)
I think the major issue is in CF server, which runs in 32bit environment (Thus being very slow on 64bit integer operations)
Your NTT code is slow. Example, when multipling two small polynomials, you still need a inversion function. O(NlogN) may be found at here: https://discuss.codechef.com/problems/CHEFKNN.
And this submit in last 5 sec of contest threw me out of top 15 =(
Sorry about that :) I wasn't submitting this till the end of the contest, just because I knew the test for which it is too slow on CF servers. In such case the best tactics is to submit at the very end (=> no hacks), and hope that tests are weak. This is exactly what happened.
For the 3rd question I assumed that the elements of the array should be distinct and then for next 1 and half hour I was busy solving the question,also with 3 failed pretest.Later Did I recognised that no-where it was mentioned that the element should be different. Feeling so stupid.
Ok contest, the problems were kinda standard-ish, but at least the pretests and tests weren't dumpster fire quality and everything that needed to work (server) worked. sebinechita could learn from this.
F was way, way too easy. It's LIS, just with a graph, and it's solved exactly like LIS, just with a graph. I spent about 10 seconds thinking about how to solve it. It would've been better to use something with difficulty between E and G rather than below (this) D.
My rating increased! by 2 points
Top 15 Indians:
gvaibhav21
evil666man
Baba
yashChandnani
teja349
jtnydv25
ajinkya1p3
polingy
hitman623
GT_18
Equinox
sinus_070
ShivRam
abisheka
nishant_coder
i think problem D E and F have same diffilculties
nice problem and rapid rating update anyway
IN PROBLEM "A" it is written that-> " they have made sure that at this point, at least one 'a' and one 'b' exist in the string." how have they given test case with only bbbbbbbbbb!!! this seems unfair
You misinterpreted the question. It means that the string has to have at least one a and b to be valid.
YES..Thank you..
In such a test case, you're suppossed to output NO.
Can anyone tell me what's wrong in my solution 37078196 for D. And why commenting this line gives AC. m=m-(pow(2,t1));
Got wrong answer in Problem C pretest 1.
vector < int > v = {1, 2, 3};printf("%lld\n",v.size());Output in codeforces ( GNU++11 5.1.0 ) : 55834574851
output in my pc ( g++ follows c++11 ) : 3
You can't print a variable of data type size using printf and %lld, you should cast it to long long first or use cout
With
printfyou need to be very careful about types. If you give the function a parameter of the wrong type, it will print garbage.And here is the problem. The size of the type of
v.size()is not standardized. It doesn't have to be a 64 bit integer (although g++ will usually use 64 bit). However Codeforces uses a g++ compiler wherev.size()is only 32 bit.Solutions: cast the variable to a
long long, or simply usecout << v.size() << '\n';:-POr use
%zuto printf a variable of typesize_t(which is the return type ofvector::size).The size of
int,longandlong longisn't standardised either. The C standard only requires that they're enough to hold specific ranges. In the same way,size_tonly has to be able to represent the return value ofsizeof().Different types are differently represented in memory, and you should be very glad implicit type conversions exist in the simplest cases at all (casting a 4-byte
intto an 8-bytelong longcould give you 4 bytes of garbage, but it doesn't).When will we get the Editorial of this contest?
TIA. :)
During the contest my code for D kept getting TLE. Now it's AC in 2 seconds. The servers are really unreliable; I had to spend a bunch of time optimizing AC code with good complexity. :/
This was an amazing contest! When will the editorials be published?
How Solve E?
I saw many of my friends AC 4 problems but fst 3 of them! I have too say E and F are too standard ,Why don't put int the Education contest!?
where is the editorial??
Hey guys!
Before the official editorial comes, here are some of my thoughts on problem A, B, C, D, F: RobeZH Blogspot Article
I am glad to hear any suggestions or questions! Thanks!
problem F http://codeforces.com/contest/960/submission/37093065
KAN this solution got accepted but fails on this test case
4 5
1 2 3
2 3 4
3 3 5
1 3 5
3 3 6
true, the tests were weak, i dont get why they didnt reevaluate the solutions
I gotta a native question that hou can I get purple? Desire to improve my ability of coding...
It is not the right place to ask such question. If you search on google, you will find plenty of posts regarding such question and replies on Codeforces and Quora. If you still think that you need to ask something regarding this, you may create a blog post on codeforces or ask on quora.