This application is designed to transform test data, for example,
0.in|0.anstoTest01/abc.inp|Test01/abc.out,input/input1.txt|output/output1.txtto01.inp|01.out,- ... and so on.
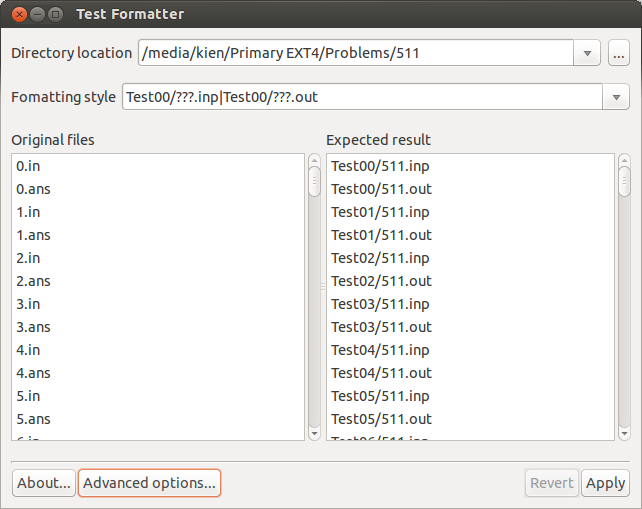
Usage
- Enter "Directory location" of a test data.
- Choose a "Formatting style" from the drop-down list (or write your own formatting style and press Enter).
- Preview the change in the box "Expected result".
- Click "Apply".
If you want to know more about "Formatting style", place cursor onto "Formatting style".
Download links
Windows
https://sites.google.com/site/kc97bla/test-formatter/testfmt3-installer.zip?attredirects=0&d=1
- Extract testfmt3-installer.zip.
- Run testfmt3-installer.exe as administrator (right-click, Run as administrator).
- Follow instructions.
Linux (32-bit)
https://sites.google.com/site/kc97bla/test-formatter/testfmt3.tar.gz?attredirects=0&d=1
- Extract testfmt3.tar.gz.
- Run testfmt3. If you want to install it: sudo make install.






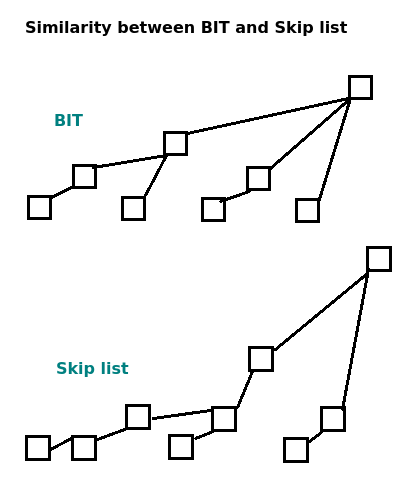
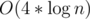 states. I don't like to prove this, but I can ensure it is true by doing some following experiment. Let's divide n into groups by depth, you will realize a special property: Each depths only contains at most 4 values of n.
states. I don't like to prove this, but I can ensure it is true by doing some following experiment. Let's divide n into groups by depth, you will realize a special property: Each depths only contains at most 4 values of n.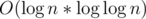
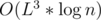 , equally to solution using matrix multiplication. Note that there are only
, equally to solution using matrix multiplication. Note that there are only 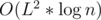 states, not
states, not 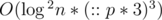 . In fact, we can avoid using map to reduce the complexity. If we do, it becomes
. In fact, we can avoid using map to reduce the complexity. If we do, it becomes 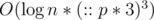 , equal to the complexity of using matrix multiplication. (I used map for easier readability)
, equal to the complexity of using matrix multiplication. (I used map for easier readability)
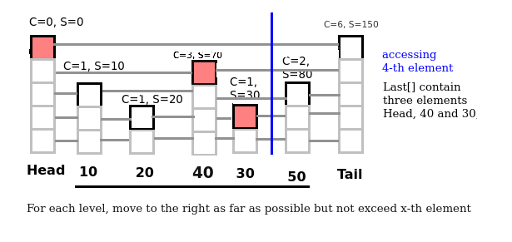
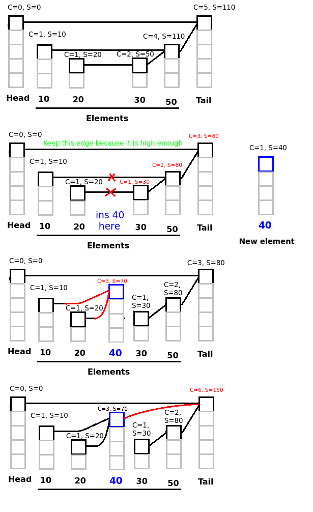
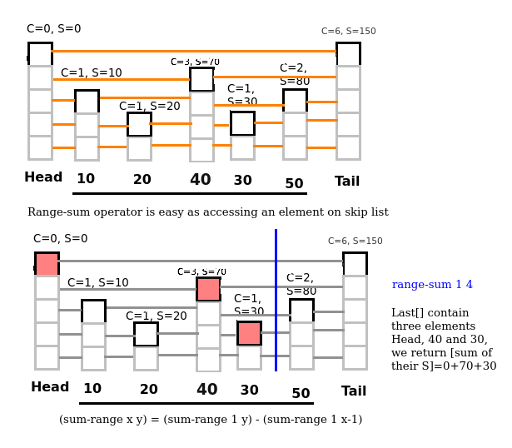
 Thank you for all of your help and replies.
Thank you for all of your help and replies.