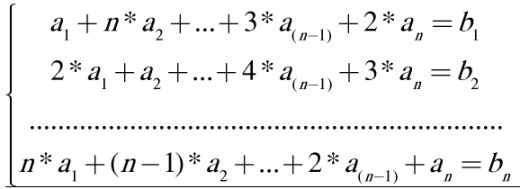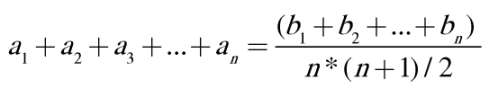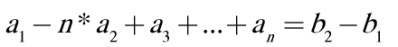Hi, I collected the solutions for the problems of April Fools Day Contest 2023. Before the official editorial being posted, we can discuss about the problems here.
P/s: The editorial was published.
Solution
Solution
Solution
Solution
1812E - Не задача по геометрии
Solution
Solution
Solution
Solution
Solution
Solution