


Hi, Codeforces!
AIM Tech Codeforces Round 4 will take place on August 24, at 19:35 MSK.
The round is prepared by AIM Tech employees: malcolm, Kostroma, Edvard, yarrr, zemen, gchebanov, VadymKa, zloyplace35, ValenKof, riadwaw and zeliboba.
Round will take place during Petrozavodsk Summer Camp, which is sponsored by our company.
Thanks to Mike Mirzayanov(MikeMirzayanov) for brilliant platforms Polygon and Codeforces and problem coordinator Nikolay Kalinin (KAN). Many thanks to qwerty787788, Zlobober, ifsmirnov and AlexFetisov for round testing!
Our company specialises in proprietary trading, the key concepts in our work are big data, low latency and high frequency. Our team mainly consists of graduates from the Moscow State University (MSU) and Moscow Institute of Physics and Technology (MIPT). You could read more on our website aimtech.com.
Participants of both divisions will be given 5 problems and 2.5 hours to solve them.
Problems C-D-E in the first division have almost the same difficulty, so we advise read all of them.
Scoring in the second division 500-1000-1500-2000-3000, in the first division 500-1000-1750-2250-2250.
We wish you good luck and high frequency rating!
Congratulations to winners!
Div. 1:
Div. 2:







How many problems are there in this contest?
5 problems, 2 hours, see russian version.
Why do people keep asking this? Do you prepare yourself somehow based on the number of problems?
I expect it will be a good contest :)
i don't agree with you :)
Usually, our contests are hard but interesting.
Why the contest time is late zeliboba
Why did you choose a working day to make the contest intead of holding it on a weekend?
Because it is a day off in Petrozavodsk camp.
so this contest is rated ?
you mean "Is it rated?" but in another style xD
ye LOL xD
High frequency :(
I had Digital Communications exam today, and it turned out terribly bad, why you would remind me of it now??? WHY???
Yeahh! Registering for Div1 contest feels really cool!
You can register for both divisions lol.
UPD: fixed
I already did :D Seems it will be try-hard contest, 8 problems in 2 hours
UPD1: They deleted my registration for Div2 lol :D Now I'm in Div1
UPD2: Now I'm in Div2 again :(
You are div1 in your soul xD
UPD: Roses are red, France is on West, you're again in div2 contest :(
is the round rated?
yeah, I guess... "We wish you good luck and high rating!"
Yes!
zeliboba , if registrant is an unrated
Too many setters. Gonna be a great contest :D YaaaaY
Will it be harder than cf rounds divXXX ? (solved 0, out of 5)XD
Good luck,everyone!
Please fix the time (it is wrong)
zeliboba I think the time you mention here is not the same as the time on the codeforces page, can you edit/clarify?
Thanks, fixed.
Will the CDE problems of Div. 1 have C, D, or E difficulty?
Yes
wrong answer Token "Yes" doesn't correspond to pattern "[CDE]"UPD:
ok correct, thank you!More seriously, it's hard to say objectively that some problem has C (or D, or E) difficulty. It depends on the person. So, we sorted them in order we think is correct, but recommend you to read all the problems because they are not too different in difficulty and you might be a person that likes D more than C or smth like that.
I think u didn't understand the question! :) he or she asked will CDE problems of Div 1 have C difficulty? or D difficulty? or E difficulty ? :) (coz the author said that their difficulty are the same) So cyand1317 hacked your answer :)
now cyand1317 fixed the checker to allow both understandings of the question.
No for sure.
It's not matter for you and me and all other coders that should participate in Div 2 :) but I think when difficulty of them are the same It means that u should just read all of them and chose a problem that u think u can solve it
Is this contest rated ??
Itachi was smart :|
Is it rating match?
Is it Rated ?
So basically I'll have to wake up at midnight to participate in this contest. XD PS : India
have a nice night :)
can anyone say how much harder is this contest than usual ??
Here you can find old years AIM Tech rounds:
http://codeforces.com/contest/709
http://codeforces.com/contest/624
http://codeforces.com/contest/572
Tanks.
There are many setters, we hope English will be better :D That's cool. Best of luck everyone!
I wonder how score distribution for both divisions works!
I see E in div. 2 is worth 3000 points when the corresponding problem in div. 1 which is C, is only worth 1750 points, while usually -and as div. 1 A, B problems in this round as well- the difference is constant which is 1000 points.
BTW, my question was totally out of curiosity I barely read E in the contests :P.
They wrote div 1 C, D, E are pretty much same difficult, so for a div 2 coder the div 1 C problem will be harder than usual.
Thanks, that makes sense :D
Back to codeforces after a long time, hope to increase ratings for me and all of you also :)
I think that the round will be very epic.
That moment when you want to get the A fast and watch the UCL draw at the same time
That moment when you want to get the A
about AIM Tech rounds
Yesss :"D :"D
Typical codeforces div 2 round: Solved A,B,C easily in 20 minutes, reads D and says "how the heck can this be solved ?" then spends the rest of the time trying to hack people.
How do you know what's typical here? =)
Registered: 8 months ago
Friend: of 0 users
:(
ok now im your first friend
:)
Why there are ~2000 people pass pretest C but so far less 100 passed D pretest. The difficulty is so large. Don't like this round at all
Are a pretest 1 and a sample from description of task same or different for task D (interactive)?
"Ctrl + R" also good)
Len hacked "Diversity"
Why wasn't I able to hack others even though I locked all my problems?
Try clearing your cache, it worked for me.
Not working :/
click room --> double click on the score of a solution --> click hack button .
I can't even open the source code, I can only check others' submission history.
I was having the same problem.
I just realized you need to be in the same room as the person you want to hack LOL
What's 6th pretest in Div2D?
I guess just a n>2000 random integers.
I would even say n > 32767
Pretests for d are so weak.
I've gotten 16 ans in D. I choose y random numbers and start. After that I choose the biggest number less or equal x. Then I go 1999-y-1 times to next number. What is wrong with this solution?
Windows rand() is up to 32768. 11 WA for me here.
How to solve DIV1B ?? Skip List ???
We can try 1000 times take random index and after all, we can go from biggest number which less than x on list. There is big probability that we can find at least 1 number in range [index_of_answer-999,index_of_answer], so we can find it.
I got WA DIV2-D final test-22, because I was type 20000 (20 thousands) instead of 2000. There are very weak pre-tests.
So what is the pretest 3 of problem E? :(
Not sure what your solution is, but I went from WA3 to pretests passed by noticing that just finding a minimum cut in the graph with capuv = guv?1: INF isn't enough since you might have a guv = 1 edge going from the T-side of the cut to the S-side of the cut. If you ignore this, you might get a flow that is valid, but not maximal. If that makes any sense.
EDIT: Specifically, my final solution was:
Finally, add both flows together. The idea behind the flow graph is that we find to find some cut using a minimal number of edges, but we can only use edges with g = 1. Additionally, we can't have any edge going from the T-side of the cut to the S-side, since then the flow is not a max-flow, since you could push back flow through this edge (in reverse). Hence the reverse INF edge.
Thanks for your explanation. ( I'm still trying to understand it :(
Will your solution fail on a graph with an isolated loop which needs positive flow?
EDIT:
Oh.... I got it. I didn't notice reverse edges will affect the residual flow network.
@ksun48: I think the answer is no. You can create such graph (1,2), (1,2), (2,3), (3,2), (3,4), (3,4). You can't cut the edge (2,3).
Eh, I assumed the graph would be connected. If an isolated loop is what kills my solution I will be very sad :c
EDIT: The story suggests they just ran a max flow algorithm from s to t, so fingers crossed I guess.
Is the answer (first line of output) still the same as the min cut in the g ? 1 : INF graph?
You mean without the reverse INF edge? I don't think so. Let's say we make a graph with two paths from s to some u, and three paths from u to t. Finally we add an edge back from u to s. For all edges we set g = 1.
Then the minimum cut has to be 3, you have to cut the final three paths. If you cut the first two paths, then either the edge (u, s) will have 0 flow, or it will have flow which you can push back, so you do not have a maximal flow.
Is flow (s,u) = 2/2, (s,u) = 2/2, (u,s) = 1/2, (u,t) = 1/2, (u,t) = 1/2, (u,t) = 1/2 not maximal?
EDIT: Yep, of course it isn't maximal.
Not sure if N = 50000 is intentional to fail the default
rand()in C++...Exactly rand() didn't work, but random_shuffle did as I noticed from solutions which passed pretests...
random_shuffle didn't work for me :(
Are you sure? I used random_shuffle too (ans was really scared). But it passed the pretests at least, and on my machine, rand_max is also 32767 (I'm using Windows) and locally testing it worked fine. Are you sure there is no other reason for it to fail?
I'm not 100% sure, but I think so. I added some shitty stuff after the first WA trying to minimize the useless queries and maybe I did some mistake in between...
I am not sure, but I think random_shuffle uses rand too.
I spent 32 minutes trying to figure out what the hell is going wrong. Ans it's not even the first nor the second time I've done it with the same exact problem...
I spent 2,5 h.
I spent atleast 200 rating.
rand()/double(RAND_MAX)*npassed. see 29761972Pick 1000 random numbers then the chance one of them is within 1000 of the answer is 1-2*10^(-9). Is this approach correct? If so then how can one miss pretest 6
I dunno, i picked 1500 and it passed pretests, not sure about systest.
Can anyone explain what amount is the best?
I didn't calculate the exact probability but here is how I estimated: Let K be the number of random numbers we picked initially, it would approximately split the list into chunks of length N / K. We are left with 1999 - K questions so we would want to maximize (1999 - K) / (N / K) which is equivalent to maximizing (1999 - K)K. Hence K is around 1000.
Thanks
1200 is even better. Generally, if you choose K, then the probability for the program to fail would be around (1-K/N)^(2000-K) because in order to fail you've got to move between two fixed points without going through one fixed point (a point is fixed if you've queried it in those first K) 2000 — K times. The probability for one cell not to be among those K is 1 — K / N. For 1200, evaluating the expression gives around 3e-9 probability of failure whereas with 1000, it's about 1e-9. Anyway, it's really small
999 is the best choice, look here: 29776215
Yep, you're right. Actually, I did the same computations, but just for a second thought that it's preferable to have higher probability (but it's not as that is the probability of failure, which you want to minimize).
rand() generates numbers less than RAND_MAX which apparently is 32767 on codeforces. (on my machine it's 2147483647)
I just used (rand() << 15) + rand()
Ahh — so does rand() depend on OS? I thought it was a compiler problem. The problem should be rejudged then.
I think RAND_MAX is also 32767 on my computer. What I always do i (double)rand()/RAND_MAX * n
Does anyone have div2D/div1B solution that's not randomised?
No, such a thing doesn't exist (assuming antagonistic test case) -- The main idea is that if you query for 1000 times, you may get results from the smallest 2000 numbers, and if x is among the largest 5000 numbers, this gives you no information about the larger part of the linked list at all.
So even deterministic solutions that pass systests are probably just "unpredictable" enough to pass off as random.
Can Div2.E be solved with centroid decomposition? I'm not certain because it says you can do up to 2*n transformations.. You don't have to reach that number, right?
I'm thinking, that for every centroid, perform a transformation with each of it's centroid children if the children's subtree size exceeds 2(otherwise it will be useless).
Will it work?
The order of transformation matters since you are deleting edges (and parent/children relationships in the subtree flip really often).
If my logic doesn't fail me, the way to solve this question is:
For each subtree of the centroid(s), transform such that a node is adjacent to all other nodes in the subtree and is connected to the root. This gives distance 2 between all other nodes and the centroid. This also can be done in 2n operations.
can you explain me what " squared distances " mean. i cant understand that and of course i didnt get the examples that made me very confused in the contest :(
Didn't think RAND_MAX was 32767.... really?
You can do smth like this:
or mt19937 rng(random_device{}())
Yup I did it but, after 15 failed submissions :D and wasted 2 hours
Oh the same.
time(0) is best syscall ever....
I was hacked even though I used srand(time(0)), I'm not sure if this is fair :(
I'm not sure if this round should be rated.
yes, it should be unrated at least for those who were attacked by subjective generators during a hack
you should use higher precision of time.
Because it's possible to predict range of values returned by rand and fail all of them (we can fail like 20 one time)
It's good suggestion to prevent such hacks, but don't you think that what happened is not fair and something has to be done regarding it? my solution is the same as the intended official solution and it would have passed the final system test if it wasn't hacked like this, and even there's an announcement saying it's guaranteed that the linked list doesn't depend on my queries while this is not true in the case of test which hacked me.
Well, I'm not 100% sure that was ideal problem but I don't think that's unfair: it's always good to understand limitations of your code
I failed not because of the limitations of my code, but because of violation of the guarantee given in annoucement. when I wrote my code I was expecting that tests which will be run on my code don't depend on my code itself.
It says that it's generated before your solution runs which is true
but second part of the announcement is not true "and doesn't depend on your queries."
Hacks are a thing.
I think srand(unsigned((long long)new char)) is better.
Div 2 D / Div 1 B solution:
If n < 2000 then we can check all positions and get the answer.
If n >= 2000, then we can choose 1000 distinct positions randomly, and query them. Choose the one with the highest value less than x, and then go over the linked list until we find an element with value higher than x.
Why does it work: Let's assume the answer isn't 1000 numbers after our chosen number. This means there are 1000 values higher than the chosen one, smaller than x, and we didn't query none of them in the 1000 queries. Chance for that is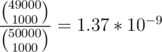 . So we have less than 0.000000137% chance to fail.
. So we have less than 0.000000137% chance to fail.
I've made the same and have 16 ans on pretest6.
Probably you used std::rand(), which generates numbers only up to 32767.
The probability of being fail is lower than the probability you hit by a meteorite. I think you should be careful next time you go outside
(Div2 B) Why are solutions using pow() function passing pretests? (Shouldn't there be a rounding error?)
I checked using custom test, (long long)(pow(2, i)) = 2^i for all 1 <= i <= 50. But I hacked some solution that didn't round it to integer.
Those using pow() may fail when the value becomes large (over 2^53), but even for the largest test cases they still remain smaller than 2^50 meaning pow() could reasonably work.
I have a question about C++ srand and rand.
I'm calling random_shuffle with the following random number generator
For some reason this gives WA. But if I take the srand(time(0)) out of myrandom and only call it once at the beginning I get AC.
This cost me 1 hour + 3 incorrect submissions so I'd really like to understand what's going on here. Does anyone know what's the difference when calling srand multiple times? Does it somehow make the distribution non-uniform?
srand(time(0)) re-seeds the generator with the current time. Assuming your solution is passing in < 1 second, it means that it will always re-seed with the same time, so your myrandom will just generate the same number over and over.
I see... I thought it was working since the result of random_shuffle was a valid permutation of 1..n and it was different on every run, but I guess it's not actually uniform since myrandom isn't actually random.
Are you sure that value doesn't generate the same thing over and over again? time (0) gives the time in seconds afaik, so I think that reinitializing each time with what seems to be the same seed should give the same number. I think that if you used srand (time (0)) in the main, just once, it've worked just fine (though I'm not sure).
Didn't expect an interactive problem, Usually they say in the blog before the contest
What a shitty task D in div2. I wrote tons of random solutions (choose randomly 500 positions, 1000, 1500, etc.) none of them passed.
I checked some solutions which passed pretests — choose 1000 random positions. WTF...
You used std::rand(), which generates numbers only up to 32767. It wasn't a nice move from the authors, they could easily make the constraint N <= 30000.
Authors knew about RAND_MAX issue: http://www.cplusplus.com/reference/cstdlib/RAND_MAX/
It explicitly says that the value depends on the library and should be at least 32767. It completely does not make sense to set the size limit to 50K.
The task wouldn't be too bad with the 30K limit. I think they should change the constraints and rejudge the submissions. Currently the judging is definitely not fair. Some people used random_shuffle and it worked, for some it didn't. There are also others who modified the result of rand() to get higher values, but this should not be required.
Unless the intended solution is not randomized, the problem should be rejudged to assure the fair judgment of the same randomized solutions.
I think that rejudge is still unfair. I usually start with problem D. I was sure that my solution is correct so I tried to find a bug and ultimately lost 2,5h.
There is no issue regarding RAND_MAX. There would be an issue if RAND_MAX was lower than stated in the standard.
Everything is fair. The judge was the same for everyone. Would you ask for a rejudge if many people forgot long longs?
It's not that easy to perform a rejudge in this situation, as some people could submit lot of solution to D and there's no fair or simple way to choose the one that should be judged at the end.
The last one.
Is this correct for Div1 E?
The minimal number of saturated edges will be the max flow letting the capacity be 1 if gi == 1 and infinite otherwise.
Case s = 1, t = 3, e1 = (1, 2), e2 = (2, 1), e3 = (2, 3), g1 = g2 = g3 = 1 is a counter example.
e1 cannot have max flow.
So why such answer isn't correct?
Then the flow of this configuration is 1. But real max flow value is 2.
That isn't a counter-example for what I said since the max flow would still be 1.
But I see what you mean, looks like adding a reverse edge with infinite capacity for gi == 1 solves that problem.
In my thought, the correct answer is set the capacity to 1 iff gi = 1 and (the reverse edge doesn't exist or the gi of reverse edge is 0). And it have same meaning to what you say now.
is this test even valid? if yes what is a correct output for it?
It's not valid because the statement says that there are no edges going to the source but a correct output would be
1
2 3
1 2
1 1
I believe that the key is to note that any edge contained in a (flow) cycle cannot be saturated in a maxflow. (Intuitively, if we have capacity to waste on making flow go circles, you cannot be the bottleneck). Finding edges contained in a cycle is easy, especially since m<=1000.
So we forcefully remove such edges from our bottleneck consideration by setting them to capacity 1000.
Now we find the mincut of the resulting graph (with all other edges weight 1). For any one such mincut, we set those capacities to be 1 and all other capacities to be 1000 for the output.
Did I miss other details?
You might need a capacity higher than 1 for the edges on the mincut
n = 5, m = 5, s = 1, t = 5
1 2 1, 1 3 1, 2 4 1, 3 4 1, 4 5 1
the answer should be something like
1, 1 1000, 1 1000, 1 1000, 1 1000, 2 2
You don't need to explicitly find the cycles, if you create a reverse edge with infinite capacity for edges with gi == 1 you do the same thing.
Can anyone please help me find out what's wrong with my solution for Div2.C? 29759810
Check out this test
5
3 1 2 5 4
Answer is
2
3 1 2 3
2 4 5
I think the answer to that case would be
No, I think that the answer is 2 3 1 2 3 2 4 5 because you also have to exchange 4 and 5
Ah you both of you are right. I simply misread the input data.
Yes, but that's the output of my program too.
It's wrong because you can't leave the two last numbers at the same position
No, my program actually groups them in the same group, so it sorts them
Sorry I misread what you were answering to -_-
What is the approach for DIV-II C ?
Consider current postion of an element and postion of the same element in sorted array as two nodes and make a graph with edges curpos->sortedpos. Now, you have to find all connected components of the graph. Here's my solution Solution
it is very annoying that you find the solution but when you code you make some stupid mistakes and your rank change from 600 to 1600
What's the best way to check that y and y' are in the same connected component after deleting edge x-y, in E?
Can someone please tell me??
When you use random() and it gives WA (submissions of Jatana)
The RAND_MAX is 32767 and it causes you WA on 6 i think.
Hack for Div 2 A?
Should give 0 right?
Yes
yyaannddeexx 1
abcde 1
Some solutions print negative answer.
abcdef
3
answer should be 0 while some contestants weren't aware of negative values.
First off, thanks to everyone contributed to make such a good round, your efforts are highly appreciated.
But I wanna say, validator or checker or whatever you call it of problem A sucks.
I accidentally wrote "Impossible" instead of "impossible" and got WA on pretest 3, I was so pissed off when I learned why I got WA.
Codeforces has been quite tolerant with case sensitivity of such words. I suggest problem setters stick to one kind of judgment (either literal words, or words regardless their letters case) so the contestants don't get confused.
And somehow I found the gap of difficulty between problem C and D div. 2 pretty big.
That's why They invented Copy/Paste :D
why interactive problem ?????
who like this kind of problems !!! i think a lot of participant hate it :( :( :(
Even worse it was an interactive problem + randomized solution combo. What a nightmare to test & debug.
I think they are really interesting. Most times solution of interactive problems is binary search or random like today's problem
what is interesting of that ?!! they can make problem solve with binary search better
Everyone have own options :)
I think who are make unvote only solve the problem !!!
For Div. 2 E I tried to centroid decompose the tree with the transformations. Is this the right idea? Also, if it is, what are you supposed to do when the transformation is illegal?
The transformation is legal iff x is closer to the centroid than y. You should also take into account the case where two nodes can each be considered the centroid.
If a transformation is illegal, try to make it legal by disconnecting and reconnecting the centroid. ;)
Far from solving all the problems, but I gotta say Div2 C and D were pretty cool
better than contest is after the contest,you just refresh the page,20 comment added :)
what can anyone gain if he solved problem using random ? the round was very good but problem D div2 was the worst problem i have ever seen
There are randomized algorithms for problems which don't have comparably feasible deterministic solutions (Miller-Rabin primality testing comes to mind). Instead of taking a purist stance on an area of knowledge, one can come to terms with its existence and use it.
i know but what problems like that test ? it tests luck i think :V
A problem with a randomized intended solution, naturally, tests the ability to come up with a randomized algorithm, which usually correlates with the ability to come up with a deterministic algorithm, plus being introduced to randomized algorithms.
As for luck, people in the comments already estimated the usual solution's error probability to be on the order of 10 - 9, so if it is implemented right and still fails, that would be an extreme amount of un-luck.
You can write a randomized algorithm where the chance of a wrong answer is on the order of 1 in a billion. So it would take about a billion submissions, on average, for something to go wrong — it's not so bad.
I think problems where you have to think of something unusual are refreshing.
the probability of fail (of correct solutions) is too small to test luck. It's more probable to be hit by a car
ahh i got it , you mean that it's okay to use solutions with a very little probability of failing right ?
Yes. Also, I will consider this problem to be more of a probability problem than a randomized problem. Once you find that the probability of failing is in the order of 10 - 9, then you are no longer worried about the random fact (It's another discussion that this round had an issue with RAND_MAX, as people in the comments are saying).
Problem D... I 1000 times call BFS on 105 vertices and 105 edges. And it gets TLE. 10 seconds. 108 operations, 10 seconds. Wow. Is it expected behavior? =(
P.S. Finally. I changed input-output to fast version, changed all vectors to handmade "lists on arrays" and got OK.
UPD: solution
How do you do a BFS to solve the problem? Can you elaborate?
Precalculate all distances using Dijkstra.
If weights of edges changes, let update distances. Denote d'v -- new distance, dv -- old distance. We have to find xv = d'v - dv. Notice that 0 ≤ xv < n, where n -- number of vertices.
We want to iterate all vertices in order of increasing of xv. Initialize all xv = ∞, x1 = 0. Let store v in q[xv], iterate x, and all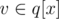 . It's like "bfs on many queues". All xv < n
. It's like "bfs on many queues". All xv < n  number of queues is n.
number of queues is n.
you may say that upper bound is not n but number of changed edges (it's a bit less number when summed over all queries)
Yes. In the implementation I use exactly this.
Afaik, if you use std::queue, it is likely to be the expected behaviour. Queue is by default very slow, not sure why. I've heard that it supports much more than it actually should.
You have probably got ridden of the std::queue, then you got AC :)
I used
vector.Both
queueandvectorare fast enough.Random access to 1MB of memory behaves like x10 multiplier to number of operations (up to x100 with ~10MB of memory)
BTW, it looks like a bug, that you don't do
k = 0afterbfs()in update query. Withk = 0your code works 10% faster.O_O
Yes. There's bug there, but another one =) We don't need
bfs()there, it was part of debug. After commenting this line OK in 3.962 sec.The time limit has been made strict to fail fast solutions which use Dijkstra every time to recalculate the distances. Our main solution runs in 4.0-4.5 seconds on all our tests.
Solution
We were aware that handmade "lists on arrays" worked faster than vectors. However, we had AC solution written fully in vectors that worked ~6.5 seconds.
We are extremely sorry for the guys who wrote correct solutions and could not optimise it to get AC. :(
Not a problem, it fits nicely within overall strategy of the contest, to fail expected solutions: B — set limit to 50K, so that normal random_shuffle or rand fails as it returns values up to 30K, set too strict time limit on D, so that vectors or queues will tle, etc.
I wonder what surprises did you prepare in other tasks :)
Why do you estimate the number of operations as 108 here?
The 1000 comes from the observation that at most half of the queries require answers so we may only do the BFS when the query of type 1 arrives.
However, the BFS itself is not a standard linear-time BFS, but more like emulating a priority queue with multiple first-in first-out queues. I'm not sure that the worst case can be achieved, at least not without degrading to actual changes, because the number of edges changed in the problem is at most 106 and the change itself (increasing by 1) seems too limiting.
actual changes, because the number of edges changed in the problem is at most 106 and the change itself (increasing by 1) seems too limiting.
In the code, I'm talking about the fact that a vertex may, in principle, be pushed to every queue, which should blow up the time from O(n + m) to O(k(n + m)) for k queues.
Lines 110 and 120 in your solution (link: http://codeforces.com/contest/843/submission/29769468)
Lines 133 and 141 in the solution by malcolm from the comment below (link: https://ideone.com/KnxwBY)
I've thought about it a little more and turns out there is no blowup apart from the memory needed to store the O(k) queues.
A vertex is pushed to the queue at most once per its incoming edge, and all outgoing edges from a reachable vertex are processed exactly once. So the total number of pushes to all queues is O(m).
I cannot believe solution of problem D was only choosing random positions, I mean that popped into my mind right after I read the problem but couldn't prove it, and it's still not crossing my mind how 1999 random positions would always fit..!! I mean there must be a counter test case that breaks any random solution, mustn't it!!!!???
If you ask 1000 random questions, the chance that the closest one to x you'll hit being farther then 1000 positions from the answer is ((50000-1000)/50000)^1000 = (49/50)^1000 = 1.68*10^(-9) ~= 0.
You don't need to formally prove it — I just simulated it. Pick 1000 random indices and find the maximum difference between any two consecutive indices. I ran it 1000 times and the worst was just over 600, so I figured it's very unlikely to fail.
Writing a custom judge for an interactive task: because having to debug only one program is too easy.
Can someone verify my approach to Div1D(I got WA4, I suspect it is a bug, not wrong idea):
Let's process queries backwards, so that we actually decrease weights and not increase. Let's run dijkstra for the final graph, we now have a tree rooted at 1(the one generated by dijkstra). Now, lets store Euler tours in a treap so that we can quickly(amortized logN) link and cut vertices. We use the following representation: for each vertex, we "record" it when we first visit it and on the last visit(we treat the tree as undirected). Now, in the first instance of a node in the treap we keep the value of the edge which comes from the parent and in the second(and last) instance we keep the same number but negated. Now, path from root(which is 1) to node V has the value of the sum of the euler tour from the beginning to the first instance of V in the tour. Now how we update: let's consider an edge from U to V. Now, if the sum (path_to_u + cost(u, v)) >= (path_to_v), we don't have to update anything. Otherwise, we cut V from the tree and link it as a child to U(this is modification to the dijkstra tree, so that it is accurate after edge update). We answer queries as the sum from the beginning of treap to the first occurence. Is this correct?
Can problem div. 2 D be solved with not random solution? I think it will be wrong to post this solution in editorial because we have some chances to fail.
I tried using skip list, but got hacked :(
The chance to fail is 1/1000000000 ((49/50)^1000). You'd have greater odds winning the lottery then failing with a correct solution.
But this chance exists
Also there is a chance that computer is broken and execute your program incorrectly.
I can tell about this problem to the CF-support and they will retest my program.
Probably not. By the time you are sure it was problem with the computer, the system test will be done, and rating changes will be assigned. They won't recalculate all the ratings, because of one contestant. It happened to me, they didn't accept a good hack case, but I don't blame them, I understand the rating can't be recalculated for everyone, because of one participant.
is there any solution except random? :D
I don't know such solutions.
so... WTF ? :|
Random algorithms are very abundant in competitive programming. Rabin-Karp string matching with random moduli, Miller-Rabin primality test (along with most efficient primality tests), Cipolla's algorithm for roots of quadratic residue, etc.
but they are not 100% okay !!
So? e.g. Let us say you have a randomized algorithm that has 1-4^{-k} probability of producing a correct result where k can be increased to about 100 without worrying about time constraints. What should stop you from using this algorithm?
you are right ! probability is ok :)
but it should have a solution with 100% correctness !
Then how are you ok with using quicksort with random pivot ? The probability of your computer getting stuck by lightning is higher than randomised quicksort having O(N2) complexity .
but we have merge sort instead !
Merge sort is comparatively slower than quick sort . And also you'll need auxiliary memory for merge sort.
There is merge sort which uses O(1) additional memory.
isn't it nlog^2n ?
No. Algorithm is called in-place merge sort. I have never implemented it, but I remember it was described in one of the Knuth's volume.
Thanks, I'll have to look it up
okay I am wrong they are 100% ok :|||
Nice task...
I think you need at least ~ n/2 queries in the worst case with any algorithm, as if you try an index you have no information about, you could end up having to try n/2 indices.
I don't see what the problem is with randomized solution. Many algorithms are randomized. Quicksort has a chance to run in O(n ^ 2), but you still use it as O(N log N) in problems (maybe not directly, but via std::sort which in most implementations is based on quicksort). Just because a solution is random does not mean it is incorrect :). In fact I think some of the most beautiful problems I have ever solved were based off random solutions.
btw std::sort is always O(n log n)
Since C++11 it is guaranteed O(n lg n). I believe it switches from Quicksort to Mergesort if the recursion tree becomes too deep.
sorry I made stupid typo, I meant the same thing: it's O n log n always
I believe the standard only mentions that std::sort must run "On average, linearithmic in the distance" (feel free to correct me) and does not impose an upper bound on the runtime in the worst case scenario. The fact that the implementation in GCC is such that the time is also O(NlogN) in the worst case is a (nice) feature of GCC but it might differ for other compilers (though pretty much every compiler I have used has guaranteed O(NlogN) at this point). But I don't think this is very relevant to the point I was trying to make :P
I don't want to look up in the Standard, but http://en.cppreference.com/w/cpp/algorithm/sort says it's alwasys O(n log n) starting from c++11
div2 D, the only solution that came to my mind during the contest was to choose random positions, but there is alway a probability of failure even if it is small, so I didn't write it. we are used to try to think of solutions with no failure probability.
+++
the main difficulty of this problem was that we are not used to find a solution with probability of failure
When will sys tests start? Last time it completely sucked!
For D I was thinking to take square root of total number of nodes in list and query at each of the square root multiples. Then take the one which is maximum less than the value required and go normally node by node from there. What is wrong in this?
Because a counter-test can easily be created by putting all the smallest values around each i*sqrt(n) point
Thanks. Did not think of that
is it fair that someone who solved 4 questions is below someone who solved 3 because of hacking?
Not really ACM standard.
Well this is not ACM, but CF. I don't want to be rude, but if you don't like it, then don't participate. The rules were like this from the beginning, and they won't change them. CF strategies have to include when to hack, and when to solve problems.
I believe that any deterministic solution for div2 D (including non initialized random generators) could be hacked. Is this true? Is this OK? (And why are undeterministic solutions prohibited in some contests (like IOI?) and allowed here?)
I think it would be really hard to hack solution which uses some info from input as random seed
agree :))
basically, yes it may be hacked and some of them actually were hacked
There was a deterministic solution in my room, so I deciphered exactly where it would probe and then arranged a custom hack that would exhaust the queries and still keep the solution out of reach. +100 points, thank you.
Where does it say they are prohibited at IOI?
First question: Yes. If there is no randomization, then there is a fixed set of queries are asked. You can construct a test case where all queried indices are next to each other, and not near to x (in terms of other elements), so there will be 48000 totally unknown elements.
Second question: It's because CF isn't IOI. ACM is different from IOI, TC is different from IOI, TC is different from CF. These are different contest types, so you can't really compare them.
I think IOI is not against randomized algorithms per se, but against programs that may generate different output when run multiple times -- If there was a program that generated correct output 1/4 of the time, does it count as an AC? I believe you can still use srand and things in IOI, but you must seed them deterministically.
For codeforces, such behaviour is tantamount to asking to be hacked. So allowing time-based seeds makes sense.
The IOI syllabus states that randomized algorithms are "out of focus" (see page 11), which means that
Which I think means that randomized algorithms won't happen because contestants are not required to know that a program that succeeds 99% of time is a correct program.
I'll probably get TLE for Div 2 C, I'm calling System.out.print() 3*n in worst case and the time limit is 1 second...Codeforces is unfair for Java :(
There is fast IO in Java too. Search for it, there are buffered readers and writers. For big IO you can't use cin/cout on C++ also, but CF isn't unfair for C++ because of that.
mt19937 eng(rd());
I used this for the generator of random numbers. Someone hacked my (probably correct) code by generating the random numbers as they would be generated on codeforces :(
Never seen such (ab)use of hacking before! I think randomized problems are not suitable for CF like contests without full-feedback and hacking.
Is there a way to prevent such hacks with mt19937?
the problems is that random_device is not random on mingw
Is that mean the random_device generator is possible to be predicated on CF?
yeah, it returns fixed sequence
I tried it on CodeChef (Codeforces custom invocation doesn't really work during sys test) and it didn't return fix numbers. Documentation also says: "std::random_device is a uniformly-distributed integer random number generator that produces non-deterministic random numbers."
Why do you think it returns fixed sequence? It happens only on CF?
it's "feature" of mingw — gcc port to windows
btw next sentence from doc:
Well, that's "good" to know, thanks for the information. I hope I won't fail sys test because of that.
PS: Do you know why it works on Codechef non-deterministically?
Codechef uses Linux and GCC
How to make your random seed secure
Read this article before submit something randomized((
to prevent this you can get current time in microseconds
Use time(0), clock() or (long long)new char will prevent the hacks.
clock is easy to hack. it returns too small number
Also you can always try rdtsc:
It seems using clock() and time(0) as random seed is OK, but the range of rand() is also a problem..
it's not OK if there's good hacker in your room:)
How to hack time(0)?
Get current time T and hack all the seed from T to T + 20, then hope that CF is fast enough to run solution in 20sec
How to hack all seeds simultaneously?
that is a nice exercise that i recommend you to solve
Just make a list with the maximal allowed size (50000) and assuming the solution you are trying to hack checks 1000 random positions defined by srand(time(0)) you can hack all possibilities "seeded" in the spam time(0) to time(0) + 20 by noticing that at most 20000 numbers will be the indexes in this 20 cases, so just put all those 20000 indexes in the first positions of the list. Then put the answer (the lower bound of x) in the last position of the list. In that way all of the 20 tests will get TLE
We had tests against clock() and for most popular seeds. But these tests were deleted.
Why were they?
The reason was that it is unfair to challenge popular seeds, but not challenge unpopular.
Nice, but I still get FST finally, maybe I should buy a lottery as someone said. that's weird to know random algorithm is so unreliable on CF.
No, it is not a lottery. May be someone challenged somebody with the same code as you. Or may be someone forgot delete this test)
got AC after I submit the exact same code 29749438 as language MS C++. maybe it has a real random_device.29760859
Also it could use another fixed seed.
I want to address the people who claim problem D was [insert word with negative connotation here] because the solution was randomized. Considering these two points:
Well theroticially yes, but technically no. If you get O(N2) because of bad luck, then you get TLE, which is pretty much not working.
It works with 100% chance, but it won't get Accepted on online judges with 100% chance (due to time limits).
O(N log N) solutions won't get AC with 100% chanches too
Actually, std::sort shouldn't be quicksort but an nlogn variant called intro sort which uses median of medians algorithm for choosing pivots after O(logn) standard quicksort iterations
Captain Obvious, need your help!
My solution for D was hacked by taow who seems to not even submit D himself. How is it possible?
It seems to be a glitch or something. I saw that he had a solution submitted.
If his solution is not counted, he has no right to hack mine. I want my solution rejudged.
His solution was rejudged(in systest) and failed pretest 1 I think.
If his solution fails pretest1, how was he able to lock it then?
Pretest 1 != Sys test 1. He passed pretests, but failed on 1st pretest.
I'm pretty sure they should be same.
I saw this on other problem also, and they aren't. Pretest 1 is sample case, which doesn't even require random because of small N, so he definitely would have passed that.
http://codeforces.com/contest/844/submission/29744761 this shows same test
It doesn't show any test cases for me. Also if you check the code it is supposed to pass example case.
It's probably because of srand()
On his submission page it shows WA on test 1 (which means he passed pretests, so could hack), but it doesn't show on standing pages. Weird.
Thankfully, the interactive problem was a hard one and had less submissions otherwise system testing would have taken more time :P
When random() betrays you (this is system tests and this guy was first(?) before systest):
Yes, he was, it's pretty sad, but sometimes happens. One time I had 30th place before sys test (back then it was like 1st for me) and failed 3 problems. Though I'm unsure if he is really unrated, or a good coder with a second account, which isn't too moral for real div 2 users, so in that case he pretty much deserved that.
Anyways, I'm currently on his ex-place, so I'm happy about that.
Oh ... that explains it. Actually, why doesn't it say that he didn't pass? It just has an empty box.
It must be some kind of bug.
Div1 Problem B
Wrong Answer on 107 here :P
WA/107 seems to be one of the standard solutions with no
srand()and arandom_shuffle. Since it behaves exactly the same as quite a few solutions hacked in other rooms, it goes down, too, but during system test instead of challenge phase.Using
random_shufflemore than once seems to work:1x : 29761406
2x : 29761568
5x : 29761106
Well, why not. Each deterministic solution has counter-tests. For 2x and 5x variations, no one saw them during the contest, so their killer tests were not entered. The 1x variation was common though.
FML >_<
Very long testing, I am going to sleep. I have never seen so long testing...:(
Edit : Finally finished
The previous contest took 4 hours in the system testing
2 hours of system testing! That is hectic and tiring!
LOL congratulations azukun for hacking SpyCheese's B and thus taking the win from him. Good luck burning in hell!
It is quite unfortunate :c
On the other hand, congrats to yosupo on winning both SRM and CF round at the same day!
Is problem D supposed to be a constant optimization problem?
Since you can solve it in O((n + m)q)
Unfortunately several solutions with correct complexity got TL. Using long long instead of int works very slowly on codeforces.
Well, to fail incorrect solutions we had to make TL a bit tight, but still you had to come up with idea and it was possible to have a solution in about half of TL
What is the best time for a "wrong" solution vs a "correct" solution?
can someone explain why this solution fails?
http://codeforces.com/contest/844/submission/29743029
DIV2B test 18
if i cast the result of
(long)Math.pow()then it works =/Try
1L << p.okay, but can you explain why
Math.pow(2, white) - 1this gets WA, but(long) Math.pow(2, white) - 1this gets AC?
Because
(long) += (double)operator truncate data and compiler didn't say about it!l:long += d:doubleworks likel = (long)(l + d)so you lose precision since l + d not power of two.Math.pow() returns a double so it may have something to do with the fact that you are subtracting 1 (which may be interpreted as a 32-bit int) from a double. As a tip, whenever you need to calculate 2 ^ p, I would just do (1L << p).
Use (1<<x) to get the x-th power of 2 :)
http://codeforces.com/contest/844/submission/29744761
Look that submission. It get Wrong answer on test 1 [main tests]. It is mistake.
Hell, I feel lucky today. It seems like I am one of few guys who used srand(kSeed) in div1B and just didn't meet any hackers in my room.
I can't believe my performance of today, is this a dream?
you've just made your dream come true
:( :( :( :(
any one else failed the test 18 div2 B for overflow :| :|
anyway,, this round was nice but problem D-div2 was a bit surprising actually
Can anyone explain why one the solutions get AC and another doesn't. I don't understand because I just changed order of the conditions in the second while
http://codeforces.com/contest/844/submission/29762117 AC
http://codeforces.com/contest/844/submission/29762065 WA
this screenshot shows the difference between the solutions
but WA code under C++14 gets AC under C++11
http://codeforces.com/contest/844/submission/29762789
And code that I sent on contest and got WA under C++14 now gets AC under C++11 http://codeforces.com/contest/844/submission/29758399 WA from contest C++14 http://codeforces.com/contest/844/submission/29763381 AC C++11
You are initializing the random number generator with time. It's not really a mystery that it could behave differently on different runs. I suppose that if you submit the same code a few times without changing compiler or conditions order you will also get some AC and some WA.
How to lose 8th place? Not handle the first element in [B] at all while everyone struggling with randoms =)
riadwaw, Kostroma, zeliboba and all other guys — I love your contests. They are hard, interesting and pretty much fun (even when everyone struggling with randoms). That's how it should be done. Thanks!
Could you help me with the question Div2. D? I think we must send the index of the desired element. So, the probability is 2000/50000. Why not?
Thank you, Rosklin.
Check this.
Hi, I have implemented a solution witch was accepted. However, I receive a wrong answer with the same solution without srand(time(0))! Why does it occur? The probability is almost 0 if we use the algorithm you have explained. I implemented it. Thank you, Rosklin.
Because without srand(time(0)) the sequence from rand() will be fixed and there's a case against that sequence.
Yes, I agree. But, the probability of error with a unique sequence is ( almost 0 ) * (# tests) = (almost 0), isn't?
If sequence is fixed, then there are tests for which probability to fail 1 and for which it's 0. If we consider tests random, then probability of fail would be almost 0, but tests are not random( they are prepared by authors or hackers)
But for correct solutions for each test probability of fail nonzero but small
Quite unfair in Div1 B
It's guaranteed in the problem that the data is prepared already, so any random seed could pass the system test. But one can hacks the other by choosing the exactly same seed to generate data. It is the BIGGEST problem which cause the hack (also the problem) to be meaningless.
Many(a big number) code passed the system test could be hacked this way and Many code which was hacked could pass the system test.
It's a conflict between interactive problem and hack.
Me: "My algorithm has 99.9999% possibility to get accepted."
Hacker: "Your algorithm has 0.0001% possibility to get UNaccepted. Let me try your random seed and see."
Spend my whole night on it (also the RAND_MAX problem).
Feeling tired about it. Sad.
Look like I've found my true rating
Sad! AC after changing queue to static array. :(
Where is the editorial?
Here.
Access not allowed?
MinGW and its quirks strike again. Using std::random_device seems to be fine on Linux and MSVC but in MinGW it surpisingly results in fixed seed. If we're stuck on Windows I would like at least an option to compile with MSVC2017 which I'm doing locally anyway.
Can anyone explain why one the solutions get AC and another doesn't? Div1B AC WA6
There was a test case against random_shuffle(), so not using anything else fails, but AC solution used rand() with random_shuffle(), and there weren't a test case against that.
After changing std::rand() to custom rand i got AC
but in my "stdlib.h" file i see...
shiiiiiiiiiiiiieeeeeeeeeetttt
Why am I not able to see the tutorials? It says "You are not allowed to see the requested page."
We are working on it now.
When will the tutorial be ready?
Problem B div2 I got wrong answer on test case 18.Please help. My_Code
I believe you should use "unsigned long long", not "long long int": the answer in test 18 is too big for "long long int".
My output:- 112589990684259972 Answer:- 112589990684259800 Making unsigned didn't change the answer. Still getting wrong answer on test case 18.
Maybe the problem is in function pow(). In some situations it's work is strange... It's more safety to use the array pow2[].
if you add
(long long)before your pow calls, it worksWhere is the editorial?
Div 2 C
I was able to think that we need a randomized solution but in no way was I certain that I will reach the correct output. It seems so unlikely, in an array of 50,000 elements, just in 1999 attempts reaching the correct answer. What is the math behind it?
Randomly choosing 1999 indices is indeed hopeless — you are only about 4% likely to stumble upon the right value.
The idea is to randomly choose K indices, and hope that you land within (1999-K) steps of the right one. For a properly chosen K (for example K=1000) the probability of success goes up to 99.999999999%.
Got what you wanted to say. I erred, the list was strictly increasing, so no duplicates. Whoch wasbtthe case bugging me.
Why do test cases unseen in these about 2 days? Does this happen only in problems of this contest or the whole CodeForces.com?
Why I can not view the test case anymore? I need to know test case which make me wrong to practice, but it seems to Codeforces has prevented this feature.
Can anyone kindly explain the question-Sorting by Subsequences?
You have to perform up to N "sortings" on subsequences of the array, in a way that every index is sorted exactly once. For example, you could always sort the whole array as a single subsequence but the problem is asking for the maximum number of sortings that we can perform.
For example, given the array {3, 5, 4, 1}, we can sort the subsequence of indexes {0, 1, 2, 3} and get the sorted array {1, 3, 4, 5}, but this way we only performed 1 sort.
Instead, we could sort subsequence of indexes {0, 1, 3} to get the array {1, 3, 4, 5} and then we could sort the index {2} on his own(as we have to include every index in at least a subsequence-sort). This way we perform 2 sortings and have the array sorted at the end of the process.
If we sorted the subsequences {0, 3}, {1, 2}, we would've ended up with array {1, 4, 5, 3} which is not sorted so these are not valid subsequences.
i am not able to see the tutorials (not allowed to view the requested page) please help me!
Hi! are there any editorials for this round ?
http://codeforces.com/blog/entry/54029
Not sure if it's just me but trying to do virtual contest with this round gives me error. (vc'ing other round works fine)
Hi, I think you should report to codeforces team.