


Hi all!
I'm happy to welcome you at the Div.1 and Div.2 shared rated round Mail.Ru Cup 2018 Round 1, it will start at Oct/18/2018 19:35 (Moscow time). The problems were prepared by me — Ivan Safonov. I'd like to thank Dmitry cdkrot Sayutin for an idea and preparation of one of the problems and Egor peltorator Gorbachev for an idea for another one.
This round is the first round if the new championship called Mail.Ru Cup, you can learn more about it following the link. The round will be rated for everybody!
The championship feature the following prizes:
- First place — Apple MacBook Air
- Second and third place — Apple iPad
- Fourth, fifth, sixth places — Samsung Gear S3
- Traditionally, the top 100 championship participants will get cool T-shirts!
In each round, top 100 participants get prize points according to the table. The championship's result of a participant is the sum of the two largest results he gets on the three rounds.
Huge thanks to Grigory vintage_Vlad_Makeev Reznikov and Ilya izban Zban for testing the problems, to Nikolay KAN Kalinin and Ildar 300iq Gainullin for their help in preparation, and to Mike MikeMirzayanov Mirzayanov for Codeforces and Polygon platforms.
The round will feature eight problems to solve in two and a half hours. The scoring will be announced closer to the beginning of the round.
I hope everyone will find some problems interesting. I wish everybody a successful round and a positive rating change!
Good luck!
UPD1,Scoring distribution:
500 750 1250 1500 2000 2250 3000 4000
Congratulations to the winners of Round 1!
UPD2







I hope scoring will be based on 2.5 hrs contest, unlike as happened in Practice Round i.e. for 500 pts problem points deducted per min = 2*(2)/2.5 per min instead of 2 pts per min.
Is the contest is combined (div1 + div2 ) or it will separately div1 and div2__
So I assume combined.
Lol. isaf27 and peltorator.
lol
Lol
/r/KarmaRoulette/
Lol
" I wish everybody a positive rating change! "
This is one of the wishes that everyone knows that can't happen :( .
Are you sure? If a lot of new users take part in round then, probably, everyone will increase his rating
Then let's wish for a lot of fake accounts!
If the sum of ratings before the contest equal to A and the sum of ratings after the contest equal to B, then A=B. So if a rating increases, there is some ratings have negative rating change.(new users rating is 1500)
Not really.
Wow! But what is that?
A lie. 9 year old post, it's probably outdated.
Positive rating change means if you lose rating, you will realize its positive aspect, like a kind of lesson you get after your failure.
I know learning is Psychologically difficult, but solving thousand easy problems doesn't make you a champion
It will put you on top of the problemset scoreboard at least.
Let's hope for a lot of algorithmic and data structure problems and no math/ad-hoc garbage.
ad-hoc is not a garbage!!!
Yeah, Numb, ad-hoc problem do suck everytime. They just plain suck. I've seen problems suck before but ad-hoc are the suckiest bunch of sucks that ever suck. But I gotta go now, the damn wiener ad-hoc lovers might be reading.
if you have problems with ad-hoc then you need to think better.
also i disrespect data structures ans algorithms because i suck at them
I can't believe people downvote me for saying ad-hoc is garbage while they upvote you for saying that you disrespect algorithms and data structures. Jesus Christ! We're in a programming community! Algorithms and data structures should be glorified!
Ad-hoc problems are more interesting because you can come with many kinds of novel solutions even without much prior experience, but for algorithms/ds problems if you don't know the algorithm/ds that the problem requires you're screwed :(
If you go to a Scrabble tournament and you don't have a wide vocabulary, you're screwed too.
And I can't see the Scrabble committee modifying the rules so that newcomers can beat experienced players.
Scrabble != competitive programming. Also, are you saying really good competitive programmers won't necessarily be able to solve ad-hoc problems as well? I don't think that makes sense.
No, I'm saying that a lot of purple or orange coders spent a lot of time studying techniques that are obsolete because of the current problem setting trends.
With many ad-hoc problems, contests end up being more of an IQ Test than a programming competition. And that's not the idea behind CP.
But if you don't think a lot about the problems but just keep coding and coding, it would be really boring!
Actually, I think it's the other way around. Thinking a lot about the same problem and getting stuck is what's boring and frustrating. Coding is always nice and fun.
Forget about programming. We are not in the programming community. We are not in the math community. We are in the game community. We just use programming and math to compete, but we don't actually do any exploring here. We just compete here. We learn data structures and math theorems only to compete better and have more rating.
This contest will be rated (div.1 & div.2) or unrated?
Rated.
A little bit of both.
Equivalent to "IS IT RATED". So down vote -_-
fourth, fifth, sixth places will be unlucky if they hadn't Samsung smart phone xD
They would be very lucky if they don't have Samsung and give them Xperia instead.
You can use them with any phone :)
Today you may fullfill your 35 challange, lol
Maybe, he can't since he was involved in preparation.
Himitsu I didn't realized before you pointed out, thanks and sorry to 300iq
why Syloviaely is not in top 10 !!! as per his rating he must be in top 10
He didn't join any contest in the last six months
He's invisible.
bet who will be gifted the macbook air :v
We can use the exclusion method, first of all, this person is definitely not me :)
Prizes are up for grabs, so I guess tourist is gonna participate :-p
Don't predict anything ever!
.
i hope that we dont have 15 min late :(
Is it rated?
No Delay yet.
Wow, I found net in a train (no way to connect from my phone since I forgot a USB cable), so it seems I'll actually be able to do this round...
Also 300iq wants to dye his hair pink.
Wish i was able to compete:(
Difficulty curve today, turning point = Problem D:
Another sad day for a panda :(
So apt :)
So , how to solve D ?
I did a greedy thing that means iterating over the array and changing the number to its complement if its better . i passed pretests somehow
But why does it work??
https://ideone.com/vmH4pj It works correct on sample test, will have to wait for systest to get over to submit. Too bad I was considering over k+1 bits and could not submit on time.
seriously, why is the time limit in E 1s? There can be 16 * 10^5 outputs! What difference would it make to set the time limit 2s like NORMAL PROBLEMS!
oh shit
Does anyone know what is pretest 3 in F or can share tricky input?
What is hack of A?
1 2 1 5 1 2
set
z = x, some guys used added 2*t3 in case when z = x, instead of 3*t3Also, some people forgot
abs(z-x)and/orabs(x-y).Was F finding maximal independent set using konigs?
Yes
Damm.. finding minimum value of H+V was easy but than finding those wires was just too much work..
It is easy if you see question in terms of mincut. mincut is just one dfs after flow.
Even vertex cover and independent set also same but you need to remember the construction technique for both.
But how are u finding min vertex cover using that? i think u r confusing between mincut and min vertex cover?
link
Didnt have just couple of seconds to get AC on F.
Submitted on last minute and only in the last seconds, i get that i have WA1.
I printed first vertical and then horizontal lines.
When i push to sumbit new code, just got message contest is over. ((
wa1 Life is pain
Is F, computing mincut of bipartite graph with all possible small horizontal wires on one side and similar vertical wires on one side. Now edge of size inf between all horizontal and vertical wires which intersect at a point not given in input. This gives n*n edges right, will it pass?
Yes, it's a correct solution
O(n*n) edges works or can we prove that number of edges are less (on top of my mind it seems we can create a tight bound of O(n*n) edges)??
Number of edges <= n*n/4. And on practice, it works very fast.
You can compute maximal independent set instead which is complement of minimal vertex cover.
i think he means no of edges in bipartite graph.. which can be of order n^2 i think?
Yes, misunderstood the meaning of edge.
Any ideas on pretest 7 for C?
Maybe something like
I had a submission that failed on 7, that also failed on this case.
Mine is correct for this one. Ok, will check after system tests.
YES 1 2 3 4 5 6
Ok maybe not then, what is your approach to the problem?
44506024
Something like
The moment I fixed this case, pretest 7 passed
YES 4 3 3 2
Maybe this? 4 0 1 2 3 3 2 1 0
Can someone please tell me how to solve D?
My (probably incorrect) idea is to maintain prefixes of xors and the count of them. Whenever I reach a number with even number of occurrences of xor prefix, I change it. Finally calculate number of subarrays using the same idea.
My solution passed pretests but I'm not sure of it though. I solved it greedily by iterating over each element and see if flipping it is better I flip it. To check whether flipping it is better I used trie tree. I hope not fail on system test :D
Sub-string [l, r] xor can be calculated as pref[r] ^ pref[l-1], where pref[i] is the xor-sum of prefix ending at i. So, sub-string [l,r] xor can be 0 if and only if pref[r] == pref[l-1]. Now, what is the impact of inverting some ai? pref[i], pref[i+1], ..., pref[n] will be inverted. So in general, you can invert some ai's to invert some specific pref elements.
Let the answer (ans) be initially n(n+1)/2. You can iterate on every pref element and its complement, check the counts of both elements (using map for example). Let the counts are c1 and c2. If you didn't invert any elements, c1(c1-1)/2 and c2(c2-1)/2 will be subtracted from ans.
To minimize the subtracted value, you can imagine you inverted some pref elements resulting in changing c1 and c2 to floor((c1+c2)/2) and ceil((c1+c2)/2), let these new values be x1, x2. So, x1(x1-1)/2 and x2(x2-1)/2 will be the values subtracted from ans.
What is complement of a number?
Its bit-wise not under k bits. For ex. under k=3, 1 (001) will be 6 (110).
can you please explain .how did you changed c1 to floor(c1+c2)/2 and c2 to ceil(c1+c2)/2.?
Suppose you are considering some value v1 from pref array, its count is c1. Let v2 be the bit-wise complement of v1 and its count is c2. if c1 is 9 and c2 is 2 for example, you can imagine you inverted 4 instances of v1 (becoming v2). So now c1 is 5 and c2 is 6.
I did same thing. Can you please explain what is wrong 44531845
In problem E you get the general strategy by looking at Jury's Answer for pretest 1. What the hell is this? I saw this at the end of contest :(.
Fact that Errichto's A got hacked by a specialist scares me.
Yoss))
What's the hack?
Quite the opposite)
;_;
How did you guys solve C? I spent 2 hours and didn't find a solution.
For every index sum the left and right. The answer is n-sum[k] for k < n.
Then you loop through the answer you found and check to see if it produces the correct left and right arrays.
But how did you get this? Please tell ? How should i think this way?
Idea is that if you have l+r bigger then l+r of other child, then you have more candies. And if you have same l+r then you have same number of candies
i also used the same strategy but can't submit. Waiting for system test to complete and will submit then :(
Can you guys tell me please, Why this is array[i] = n — l[i] — r[i]? I spent 1:30 hours but still didn't understand why this works. Any hint would be greatly appreciated. Thanks.
The sum of left[k] and right[k] is the total number of cells that are greater. If this is your answer, you will get a larger value for a cell for less candles, and a smaller value for a cell with more candles. Since this is the opposite of what you want and all the answers need to be between 1 and n, n-(l[i] + r[i]) gives one possible solution.
I solved it using the logic of fill from max to min. Max element should have l,r = 0,0. So fill all such elements in answer as max (we can use max = n). Let's move to the second max element (let it be n-1), It exists in the positions where l = the number of elements already filled in the left, and r = number of elements already filled in the right. And so on till you fill the array.
If at the ith step the array is not filled yet and there is no such element where you can put the ith max, there will be no answer.
so this will be O(n^2) isnt it?
O(n^2) will pass in C
Yes, but n ≤ 1000 so it will pass. Keep in mind that constraints can give you hints about the required algorithmic complexity.
perfect solution could not come to this even thinking for an hour
Friend's standing not working??
How to solve H?
My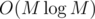 solution: let's write
solution: let's write 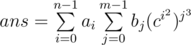 . As we can see, here
. As we can see, here 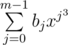 is polynomial which is same for all
is polynomial which is same for all 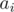 , we only have to compute its values for
, we only have to compute its values for 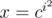 . We should take
. We should take 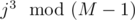 instead of j3 so polynomial will be of reasonable size. Now you should note that mod is prime and it has generating element g such that each element x can be represented as x = gi. Now only think you need to do is to compute value of polynomial in all powers of g which can be done with Chirp-z transform. But since you'll have to take
instead of j3 so polynomial will be of reasonable size. Now you should note that mod is prime and it has generating element g such that each element x can be represented as x = gi. Now only think you need to do is to compute value of polynomial in all powers of g which can be done with Chirp-z transform. But since you'll have to take 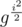 in elements, you can actually compute only powers of g2, i.e. all values in points g2k. But you can transform your polynomial to count all values in g2k + 1 as
in elements, you can actually compute only powers of g2, i.e. all values in points g2k. But you can transform your polynomial to count all values in g2k + 1 as 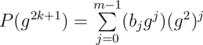 . The last thing to mention is that you can half the size of polynomial you need to calculate values in by abusing the fact that you calculate 'em in g2 (see my unreadable code below to get the notion of what's going on).
. The last thing to mention is that you can half the size of polynomial you need to calculate values in by abusing the fact that you calculate 'em in g2 (see my unreadable code below to get the notion of what's going on).
I couldn't make it below 4s during the contest, because author is probably a cuck and thinks that you can't say that you solved a problem if you didn't optimize all constants in your code or if you don't think exactly as the author does. But at the very end I realized that there is 2 times optimization in the length of vectors which probably would allow my solution to pass after system tests end. Optimized solution itself: #Jq5TzC. (I used quasisphere code for fast mod multiplication)
UPD: fixed solution gets AC with ~2900ms :(
H: let's say the problem asks for a[i] * b[j] * c^(i^2 + j^3) find the sum of that for every possible value K == c^(i^2 + j^3)
this problem is a lot easier, since you can find a primitive root R for 490019 (I'll call it MOD from now on) and write any A > 0 as R^(some value % (MOD — 1)) and R^x * R*y == R^(x + y). From this point, you can use FFT to calculate the answer easilly.
Now, we want to turn a[i] * b[j] * c^(i^2 * j^3) in the type of problem above. Notice that MOD — 1 = 2 * 491 * 499 so it has only 8 divisors. We'll group i^2 and j^3 into groups of gcd(value, MOD — 1). Note that X % (MOD — 1) can be represented as a tuple (X % 2, X % 491, X % 499) using the chinese remainder theorem. Now, for each pair of divisors of MOD — 1, you can put together those values ignoring the positions in the tuple that are 0 (since in multiplication you multiply the tuple and it remains 0). All that's needed now is finding a common primitive root between 491, 499 and 2 and use it for the calculations as explained before. Now, just pass through the values and plug them together using CRT or something else with the positions that were 0.
Is this correct?
I believe your solution is correct, we have something very similar to what you have written.
I just finished coding and it's working on samples, I'm gonna kick myself if this doesn't work. I failed E because I read that it pushes to the back and wasted too much time on H without finding the common primitive root part, found that minutes after the contest.
Well, actually there is no need to have a common primitive root. It is not important since you apply discrete logarithms, sum up and exponentiate discretely component-wise.
I had some trouble with precision but it passed, the primitive root idea isn't needed. You can take the discrete logarithm of ANY primitive root for every prime in the pair of groups and group it together after. http://codeforces.com/contest/1054/submission/44524051
In D, I thought of a greedy approach but it didn't work as I did not take into consideration the number of bits (k), so the complement operator didn't work the way it should for this problem. What is the ideal way to solve this problem of using custom-size integers? STL bitset doesn't seem to work as it doesn't allow the size to be defined at runtime.
I wrote a solution using vector after the contest, but it seems to be a very inefficient way of doing this.
Let c=2^k-1.
In that case complement to a is just c-a;
You can take the compliment and then mask the right k bits by taking bitwise AND with 2^k-1
Slowest System Test Ever
Nah. Crashed systests were slower. Systests taking hours just because they're slow aren't so uncommon on CF.
Is it me or was the system testing faster before moving to ITMO?
Are you sure it's related to being in ITMO? Some contests take longer to judge than others. It looks like today's was rather heavy in this regard; it seems like problems have a lot of tests. Also, problem B was solved by a lot of people, but had O(n) complexity with n = 105. Often, problems that get a lot of submissions have like O(1) complexity or much smaller n.
How to solve D?
In Problem D, using greedy to iterate over the numbers and flip if it's better passes systests. Can someone please explain why/how does greedy work here?
Example http://codeforces.com/contest/1054/submission/44511187
If you build prefix xor array, then xor of interval can be 0 if there is x and x in that array. If we count occurencies of min(x,x^((1<<k)-1)) then this is really similar, because we need to have as even number of x as flip(x).
We need to minimize the number of subarrays with xor==0.
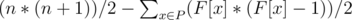
Let's build a prefix xor array, P, and use a map, F, to track the frequency of each element in P.
If we cannot change any element, then answer would be:
If we can change elements to its complement, we can try minimizing the summation.
To do so, we can try breaking up a single element with large frequency to many elements with lower frequency. This will decrease the sum because of the property a12 + a22 + ... ≤ (a1 + a2 + ...)2 for non-negative integers.
We can iterate over the prefix array and if x is the current element and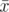 as its complement, we choose the element with the smaller frequency until this point and increment its frequency.
as its complement, we choose the element with the smaller frequency until this point and increment its frequency.
Now, the only case left is how do we handle choosing when .
.
It actually does not matter.
Suppose we choose x over , then it would only negatively impact us when we have another element later on with x as one choice and the second choice being some other value apart from
, then it would only negatively impact us when we have another element later on with x as one choice and the second choice being some other value apart from 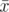 . But this will never happen because each x is associated with only one, unique
. But this will never happen because each x is associated with only one, unique 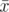 .
.
Hence, the greedy algorithm would work.
Got it, thanks.
I am a little confused. In these codes why value of curr does not matter. curr stores the current greedy cumulative xor till i.
Here if frequency of bb is less, then curr should be update to bb but every time if we update curr to aa it is giving correct answer.
aa denotes cumulative xor if element a[i] would have been taken, bb denotes if complement(a[i]) would have been taken till i.
Can someone please explain why?
https://ideone.com/VEJHBM
https://ideone.com/xzo4pe
Both are giving AC
If original P had the values x0, x1, x2, x3 and suppose you flip x1, then P would become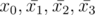 .
.
( prefix xor is basically prefix sum for each bit mod 2. If you flip the parity of any bit, then all the parities of further elements in that bit would be flipped too.)
Then if you flip x2, it would become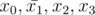 .
.
So, regardless of the elements you've flipped, either the current prefix xor is correct or it's complement is correct.
Knowing which one is correct does not matter since you will be comparing both of them anyway.
I am not getting the reason for F[0]++ in your code. We have not seen any prefix xor array element.
(F[x] * (F[x] - 1)) / 2 should give us the number of subarrays with XOR == 0.
This works for all positive x and fails when x = 0.
The correct formula when x = 0 is (F[0] * (F[0] + 1)) / 2. (You can just take a prefix of the array with ending element as 0 but this is not possible when x!=0 ).
Also (F[0] * (F[0] + 1)) / 2 = ((F[0] + 1)) * ((F[0] + 1) - 1)) / 2.
So we can just increment F[0] at the beginning to handle this case.
Thanks! Got it now.
I thought about the greedy approach but didn't implemented it, I learned it's better not to try proving things in contests, specially greedy ones... damn life
update rating please...
Just check out these two solutions for problem C ....there's a difference in code in the first loop ...still both the solutions got accepted? Weak test cases or something else? 44516044 and 44522031.He skipped his first solution to get it right.
Not sure what's going on, but the second solution is giving correct outputs too. It's just offset by a certain number (idk how), e.g. the first testcase is offset by 2 from the jury answer. The problem statement doesn't require for the smallest number to be 1, so that is fine. I don't think the testcases were weak.
Thanks dude for looking into it.
Standings page down and still waiting for rating update :/ I understand the ongoing transition to ITMO may have delayed things, but please look into these issues. Thanks.
when the rate is upd??
Failed on the problem H because of the precision error in my FFT library code. T_T
This contest will have Editorial?
http://codeforces.com/blog/entry/62563
Please provide with the Editorial ASAP. Really nice set of problems. Looking forward to the upsolving :)
http://codeforces.com/blog/entry/62563
Any English Version of it?
Please find my solution at : http://codeforces.com/contest/1054/submission/44512450
The algorithm I am following is this,
for each student, find out how many student have more chocolates than him, by adding l[i] and r[i].
This basically gives the standard competition ranking. see[1].
Next step is I am simply verifying if the ranking I am getting is a standard competition ranking.
And chocolate distribution is (n-rank[i])
My solution is failing on test case 6. And I am not able to download the whole test case( it is big).
Any body will be kind enough to point out what I am doing wrong ?
[1]. https://en.wikipedia.org/wiki/Ranking#Standard_competition_ranking_(%221224%22_ranking)
a
Here's a solution for G:
Let xi be the number of people in the i-th group. In any solution, we expect to get have exactly xi - 1 edges between these people (we can't have less since they wouldn't be connected, and we can't have more or it wouldn't be a tree).
Let wi, j be the number of groups that node i and node j have in common (and suppose we have these counts).
Let's find a max weight spanning tree on the complete graph where the weight of an edge between nodes i and j is wi, j. If the weight of this MST is equal to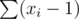 , then the answer is yes and we can print any max spanning tree, otherwise it is no.
, then the answer is yes and we can print any max spanning tree, otherwise it is no.
To show this is optimal, if a solution exists, the weight of that tree is exactly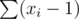 , so our algorithm will find it. The other way is if we do find a tree with this weight, then this is a valid solution, each group can only contribute at most xi - 1 to the weight of the max spanning tree, which shows it is also a valid solution since each group is connected.
, so our algorithm will find it. The other way is if we do find a tree with this weight, then this is a valid solution, each group can only contribute at most xi - 1 to the weight of the max spanning tree, which shows it is also a valid solution since each group is connected.
The only other tricky part is computing wi, j fast. This part can be done with bitsets
Really neat!
I had something else in mind:
let's imagine any correct solution, and find any leaf l in the tree. It's connected to some other vertex v. Then we can see that for each group A of vertices in the input such that |A| ≥ 2, from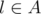 follows
follows 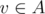 (l is connected to v only, so any "non-trivial" set containing l has to contain v).
(l is connected to v only, so any "non-trivial" set containing l has to contain v).
Moreover, if we find any two vertices (l, v) fulfilling the property above, we can safely assume that l is a leaf connected to v only. (Proof: let's take any solution. If a group of people contains l, then it also contains v, which means it also contains a whole path between l and v. We can safely remove l from the tree, attaching all subtrees that were connected to l to the second vertex on the path. Then we can reattach l as the leaf connected to v only.)
The idea is now straightforward: find a leaf, remove it, find a leaf in the remaining tree and so on. The only problem is how to find a pair of vertices (l, v) as above. For each pair of people i, j, I am maintaining bi, j, the number of groups larger than 1 containing i, but omitting j. (These can be computed directly from wi, j in the parent post.) A pair of vertices (l, v) fulfills the condition above if bl, v = 0. bi, j's can be straightforwardly updated after the removal of a single vertex.
This leads to another solution in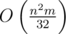 time.
time.
How to solve E?
My approach:
In the steps 1 and 2, we move every digit at most twice. In the moves 3-7, we again move each digit at most twice.
Thank you :)
There's a classical idea that you can go from the beginning and the end to some "ideal" state, and then output something along the lines of [beginning to ideal] + reversed([end to ideal])
With that your solution stops at step 2 out of 7
I moved all 0-s to (0, 0) and all 1-s to (0, 1), then moved from them. Handling columns ≥ 2 is easy, then rows ≥ 1 need to be processed (columns 0 and 1 give you two queues, you can either move a number from the front of one queue to the back of the other or just move it to row 0) and finally, the initial strings in (0, 0) and (0, 1) can be processed using empty (1, 0) and (1, 1) as temporary queues. Moving everything the other way is very similar.
The condition that we can't move from the front of a queue to its own back makes this problem a lot more complex than it seems.
Yeah looks pretty similar to majk's solution above. Thanks :)
I did it using at most 3·s steps.
Let's assume we don't have the restriction (x0, y0) ≠ (x1, y1).
Step 1: Move all 0s to the first row, and all 1s to the second row. Including all that already belong to the 1st and 2nd row. Since I remove the restriction of moving one digit from one cell to itself this is easy. We move each digit once in this step, so exactly s steps are performed.
At the end of step 1, all 0s are in the first row, and all 1s are in the second row.
Step 2: Calculate how many 0s and 1s belong to each column, and how many are currently in, so we can rebalance them in order to have in column jth as many 0s and 1s are needed. In this step, each digit does at most 1 step (moving to the right column).
At the end of step 1, all 0s are in the first row, all 1s are in the second row, and the number of 0s in the jth columns coincide with the final amount of 0s in the jth column. The same happens with the 1s.
Step 3: Build the target board. Just move each 0 and 1 to build properly each cell using only 0s and 1s that are in their current columns, i.e. each digit moves vertically. Notice that we need to build also cells on the first two rows, and we can do that in any order we want. In this step, each digit moves exactly once, so we need at most 3·s steps in total (counting moves from step 1, 2, and 3).
Finally, this works fine, because I assumed we can move one digit from cell c to itself. But, when is this going to happen? and how can we fix it? From this point on you can think on several fix that will work fine, here goes mine.
Invalid movements will happen in step 1 and 3. Since we are performing step 2 optimally we won't try to move one digit from one cell to itself.
The fix in step 1 is really easy. If we find a 0 at the end of some cell in the row 0, instead of moving this digit from its cell to itself (as suggested in this step) we can move it to any other cell in this row. I move it from (0, j) to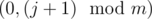 a different cell in the same row.
a different cell in the same row.
What can we do in step 3? Here the solution was a little bit trickier. Regarding 0s, I shifted the first row one step to the left (cyclic) and when counting (on step 2) number of 0s on column jth, I counted that on the shift-ed board. That way, after step 2 on the cell (0, j) there are only 0s, and the amount of 0s is equal to the number of 0s on the jth column minus 0s in the cell (0, j) + 0s in the cell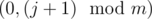 . So, on step 3, instead of pushing 0s from (0, j) to itself I moved them from
. So, on step 3, instead of pushing 0s from (0, j) to itself I moved them from 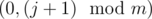 to (0, j).
to (0, j).
I found this solution easier (except for the fix of moving one digit from some cell to itself) than other solutions, and the funny thing is it performs at most 3·s movements.
My solution
Well, I understood the problem C clearly. But cant find a proper way that how to solve it. Can anyone give me some hints how to solve C. Any hint would be greatly appreciated. Thanks.
Set last element as 1
Increase element on left according to left array
Decrease element as per right array
Check if your array now satisfies the left and right array both
If yes
Then print all elements as arri - minarray
Please publish the editorial for this contest.
How to solve E ?
How to prove the greedy solution to D ?
Can you tell me please, Why this is array[i] = n — l[i] — r[i]? I spent more than 1:30 hours but still didn't understand why this works. Any hint would be greatly appreciated. Thanks.
Sure.
Keep in mind that l[i] + r[i] represents the number of people which are greater than i.
So, if l[i] + r[i] > l[j] + r[j], it means that the i-th person has more people greater than it, than the j-th person does.
In other words, it implies that the i-th person gets fewer candies than the j-th person.
Let f(x) be the function which decides how many candies person x gets.
Then, f(x) must obey few properties —
1 <= f(x) <= n, for everyone.
If (l[i] + r[i] > l[j] + r[j]), then f(i) < f(j)
The function f(x) = N — l[x] — r[x] satisfies both these properties. :)
Thanks a lot man.
Here is my code for reference. :)
No problem :)
Can you explain me,how & why
f(x) = N — l[x] — r[x]works?I cannot feel it.I explained right ?
It obeys the two conditions necessary.
It ensures the person with highest (l[x] + r[x]) gets least candies and the lowest (l[x] + r[x]) gets highest candies.
Please elaborate your doubt :)
.