


Hi all,
Consider n lattice points in a 2D grid {(x1, y1)....(xn, yn)}. A point (x1, y1) is said to dominate another point (x2, y2) if and only if x1 > x2 and y1 > y2. Obviously this dominance relation defines a DAG: G has an edge 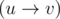 if point u dominates point v. Let us call this the dominance graph.
if point u dominates point v. Let us call this the dominance graph.
My question is this, is it possible to efficiently (say in time O(nlog(n))) compute the dominance graph?
Obviously, the dominance graph could have O(n2) edges. For example, if every point lies on the x = y line, then each point would dominate all points below it, giving us nC2 edges. But I would be happy with a graph that would INDUCE the dominator graph by transitivity.
So, in the example above, instead of nC2 edges, it is sufficient to keep n - 1 edges.
This is not from any contest. It's just something that I'm curious about and haven't been able to make progress on. I don't even know if this graph is going to be sparse enough to be explicitly computed.







The dominance graph can have O(n^2) edges. For example- in this case-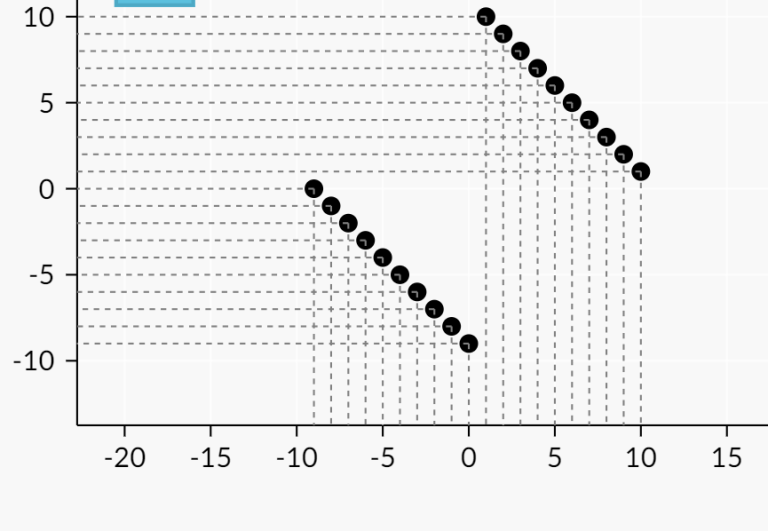
Wow. That absolutely settles it.
How about this follow-up question: If we decided to clump the nodes that have the same ancestors and the same descendants, then would the graph be smaller than O(n^{2})?
Because we have derived this graph from such a compact representation, I want to see if the graph has some interesting properties.
Edit: Its possible with some additional nodes. See radoslav11's comment below.
I don't think there will be less than O(n^2) edges. Just move any of these lines parallely towards the other and we will have different nodes having different set of ancestors. While all over it will still be O(n^2).
Also, how did you generate this graph?
I used csacademy geometry tool.
You can actually create a dominance graph with some additional nodes that will have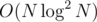 edges.
edges.
The overall idea is to imagine you have a 2D segment tree and for each node in it create an additional vertex that has directed edges to its children nodes. We will also add edges from the leaf nodes of the tree to the corresponding vertices at that coordinate. Then if we want to add an edge from a vertex to all other vertices that are dominated by it, we do 2D query for the interval [(xi + 1, yi + 1), (∞, ∞)] and add directed edges from the current node to the corresponding nodes. This way if we use dynamic segment tree we will have only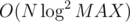 edges and the amount of vertices will be
edges and the amount of vertices will be 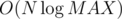 .
.
By compressing the coordinates we can easily achieve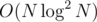 edges and
edges and  memory.
memory.
The same thing can be done with Quad-tree and in practice it should perform better.
Your construction is quite ingenious.
So, if I understand your idea correctly, the length of the maximum antichain doesn't change in your new construction. Could you confirm that?
If you don't include the additional nodes in the antichain — yes, because you can think of the additional nodes as blocks of compressed edges.
If you do include them, I again think the size of the antichain will stay the same. But I unfortunately don't have a nice proof for that.
On a side note, I also found an easier and better way to compress the dominance graph. It works in and the memory is also
and the memory is also  . If anyone is interested I can explain the idea. In short it's based on persistent trees and going through the points from right to left, based on their X.
. If anyone is interested I can explain the idea. In short it's based on persistent trees and going through the points from right to left, based on their X.
I am VERY interested.
For convenience, imagine that all X are different. Also we will compress the coordinates.
Now sort the points in decreasing order of their X and go through them one by one. If the current point has coordinates (xi, yi), we need to add edges from it to all points that we have already passed with a larger y.
Let's maintain a 1D persistent segment tree. Initially build it like normally creating O(n) new vertices and linking them to their children. You can think about it as a vertical line, where each leaf is linked to the points with the corresponding Y that we have already passed.
So back to looking at a point (xi, yi). We basically want to add edges from it to the part of the "line"/persistent tree that is the interval [yi + 1;n]. Well we will make a query on the tree and add edges to the needed nodes. With this we have finished adding the edges from point i.
edges to the needed nodes. With this we have finished adding the edges from point i.
Now the last part is to add the point to our "line". We create new vertices for the path from the root of the persistent tree to the leaf for yi. We will also add edge from the new leaf to the vertex i. Now we add edges from this new path to its prototype and replace the old path with the new one in the "line".
new vertices for the path from the root of the persistent tree to the leaf for yi. We will also add edge from the new leaf to the vertex i. Now we add edges from this new path to its prototype and replace the old path with the new one in the "line".
This way the complexity and memory will be .
.
Oh, I understand. This construction is quite magical.
Again, just to reconfirm, in the final graph we will have ...
... all the edges of the persistent segment tree + edges from leaf to relevant nodes of the previous version of the tree.
Yep.