After Round 512 finished, I took a look at the rating changes from Div 1 and ended up calculating their average.
To my surprise, the sum of the rating changes was -5383 (anyone want to help double check the math?). This means that for the 500 participants the average rating change was -10.77. I know this contest is probably an outlier, but this seems way too extreme to be reasonable.
If anything, I think the average rating change ought to be slightly positive, in order to reward participation over time. For example if the average rating change per contest is +0.5, then if someone participates in 100 contests over two years (which is some serious dedication), the most this could contribute to their rating is +50, which seems perfectly fine. This also serves as encouragement for relatively inactive people to be more active.
However, averaging more than a 10-point loss in a round is unreasonable and likely to discourage people over time from participating if it keeps happening; i.e., people who maintain a similar level of performance will see their rating go down over time, and people who improve slightly will see their rating stay flat. If my calculations all check out, the rating algorithm likely deserves some reconsideration.
EDIT: After some more observation, it looks like what's happening is that new accounts who do just a few contests, lose rating to everyone else, and go inactive are potentially offsetting this effect overall. It's hard to say for sure without more specific data.






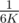 .
.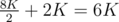 again.
again.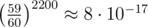 , extremely low.
, extremely low.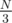 = 1,000,000. Even if you don't want to do the math, you can observe that the answer is between
= 1,000,000. Even if you don't want to do the math, you can observe that the answer is between 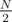 = 1,500,000, the average distance for index
= 1,500,000, the average distance for index 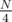 = 750,000, the average distance for index
= 750,000, the average distance for index  by using an
by using an 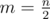 . Let's define the function
. Let's define the function  , which I'll describe here:
, which I'll describe here: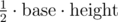 , if we picked two of the
, if we picked two of the  time.
time.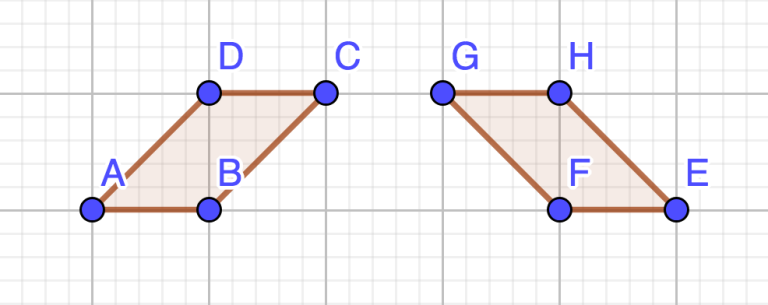
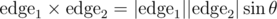 , and the solutions above use this idea.
, and the solutions above use this idea.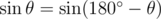 . The case above makes use of this fact by alternating angles of
. The case above makes use of this fact by alternating angles of 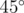 and
and 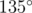 , making all cross products the same despite angles being different.
, making all cross products the same despite angles being different.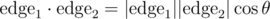 , and
, and 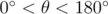 (our polygons are convex). A similar idea that also works is to use the distance between vertex
(our polygons are convex). A similar idea that also works is to use the distance between vertex 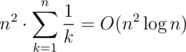 .
.