


Considering all the color revolutions my last blue point was after Codeforces Beta Round 62
Considering all the color revolutions my last blue point was after Codeforces Beta Round 62
I like to build my cp library. I am not aiming to fill it by each algo I have met, so content looks poor. Instead I am focusing on frequently used features or implement convenient api for powerful methods.
Also I like to rate cp libraries of others and currently I noticed that my lib have enough implementations which I never seen before, so I want to share it with community.
Hope it will inspire you to improve or rewrite your library and eventually rethink about some algorithms (which happens to me couple times).
graphs/trees/centriod_decomposition.cpp
This one is the perfect example of what I am calling convenient api. I've seen a lot of centroid decomposition snippets and almost all of them is template code or unfinished data structure with piece of code where you need to add your solution. I have snippet that doesn't need changes at all and I need to just call it.
centriod_decomposition(tree, [&](auto &g, size_t centroid, size_t sizeof_subtree) {
//g - is current subtree and I can freely traverse it from centroid by dfs
});
Once I've seen almost similar implementation but author passed to lambda original tree and vector of blocked vertices. I feel this uncomfortable to code: you still need to take in mind that vertex can be inaccessible.
It has little overhead from coping graph but I have never stubbed on this because overall running time is more crucial.
misc/parallel_binary_search.cpp
Well, it is actually not general (can't solve this) but I am working on this. This one about "find first version of data where query is satisfied".
It rarely used but api is really sweet. Here I need to describe scope where I set predicate, implement evolution of data and just commit all changes — internally all queries will be executed in necessary moments.
auto res_bs = parallel_binary_search(qn, m, [&](auto vc) {
//usually create init data
vc.pred = [&](size_t qi) {
//check query in data and return true/false
};
//do changes of data and call vc.commit() on each
});
Some examples:
As bonus this implementation has very low time and memory overhead. It not uses map or vector of vectors: you can store all unfinished ranges sorted by left and very easy to split it to new groups in place.
Implicit splay tree with iterators (stl style). It has api close to std::vector and not invalidating iterators like in std::set.
ilist<int> a;
a.push_back(0);
a[0] = 10; //O(logn) access
a.assign(begin(vec), end(vec));
for(int &x : a) ++x; //traverse from begin to end
while(std::size(a) < 10) { //calls a.size()
a.insert(begin(a), 1); //O(logn) insertion
}
ilist<int> b = a; //makes copy
a.insert(begin(a), b.extract(begin(b) + 3, begin(b) + 6)); //O(logn) cut
a.insert(end(a), std::move(b)); //moving without coping
auto it = a.at(5); //iterator to 5th item
assert(begin(a) + 5 == it); //iterator advance in O(logn)
assert(it - begin(a) == 5); //iterators distance in O(logn)
assert(std::next(it) - begin(a) == 6); //also has ++it
assert(std::prev(it) - begin(a) == 4); //and --it
This snippet is biggest one but is not in final state. As TODO I want to implement reversible option and build link-cut trees that use it as black box.
My ntt is very default and maybe slow but it have no hardcoded ntt-frendly modulos. Actually I can understand why you add 3-5 modulos in ntt snippet but what I do not is hardcoding attendant stuff for it like roots. Seriously all this can be calculated in runtime easily. But with power of c++ all modulos can be calculated too!
As result convolution receives parameters and compiler will generate modulos that satisfy them.
convolution<modint<998244353>>(a, b); //will recognise as ntt-mod
convolution<modint<786433>>(a, b); //same! check codeforces.com/gym/100341/problem/C
convolution<modint<1000000007>>(a, b); //will generate 3 modulos and combine result by CRT
convolution<uint64_t, 1<<20 ,5>(a, b); //will generate 5 modulos good for length at most 2**20
And finally my favorite... strings/hasher.cpp
My hashing snippet uses famous rolling hash with $$$mod = 2^{61}-1$$$ with magic bit multiplication which works really fast.
Lets define core usual primitives about hashing and just implement it:
hash_t — wrapper of uint64_t containing raw hash (special case of modint)
hashed — what remains from string after it... hashed: hash_t and its length
hashed h = str; //from std::string
h.length() // length of hashed string
if(h1 == h2) // equality check in O(1)
h = h1 + h2; // concatenations in O(1)
h += 'a';
hasher — hash array of string/vector, allows get hash on range in O(1)
hash_span — reference to some range in hasher
hasher a(str), arev(rbegin(str), rend(str));
a.substr(start, length); // hashed
a.subhash(start, length); // hash_t
hash_span s = a(l, r);
assert(s.length() == r - l);
assert(a[s.start()] == s[0]);
hash_span also have overloaded operator< (in $$$O(\log len)$$$) which can be used in std::sort or std::lower_bound.
Looking at language statistics in last rounds I have wondered why so many Java and so extremely low Kotlin coders?
Kotlin, in a rough sense, is modern replace for Java, so...
I don't want to note basic advantages of Kotlin which described everywhere. But it is language with modern syntax, and I think it is cool for cp almost as Python. I have more than one year experience of coding in Kotlin (but not cp!!), and I can describe my feelings as "I will never write even single line again in Java".
Maybe you remembered Kotlin as not so cool language when it was 1.4 but now (1.7 in moment of writing this blog) both syntax and std lib have improvements. For example, instead of readLine()!! now it is readln(). Or modulo function
val MOD = (1e9 + 7).toInt()
println((-1).mod(MOD)) //1000000006
println(((MOD-1L)*(MOD-2L)).mod(MOD)) //2
Usage of lambdas in Kotlin is awesome. Just look at this custom comparator:
data class Segment(val l: Int, val r: Int, val id: Int)
...
segments.sortWith(compareBy<Segment> { it.l }
.thenByDescending { it.r }
.thenBy { a[it.id] }
)
Last what I really like is extensions, great for templates/libraries
fun IntRange.firstFalse(pred: (Int) -> Boolean): Int {
var l = first
var r = last + 1
while (l < r) {
val m = (l + r) / 2
if (pred(m)) l = m + 1 else r = m
}
return r
}
//usage:
val i = (0 .. 2e9.toInt()).firstFalse {
1L * it * it <= s
}
range_sum_range_add with only two BITs.Suppose we have (sub)task to proceed following queries:
range_sum(l, r)range_add(l, r, x)Most familiar solution is segment tree with lazy propagation. And maybe you didn't knew, but such segment tree does not needs pushes!
Every time I see segment tree with pushes in this problem, my heart is bleeding... But! This is unnecessary, because this problem does not needs segment tree!
range_sum_range_add to range_sum_position_addAll following is described in 1-index numeration, and by range I mean half-interval $$$[L, R)$$$.
Let me remind you that sum on range can be reduced to sum on prefix (or suffix). And in the same way — adding on range can be reduced to adding on prefix (or suffix).
OK, suppose we have some changes of array (adding on prefix). We have for each $$$i$$$ value $$$a_i$$$ means this value is added on $$$i$$$-th prefix. How to calculate sum on particular prefix $$$k$$$? All added values inside prefix, i.e. $$$i \leq k$$$, must be added fully as $$$a_i \times i$$$. Values outside prefix, i.e. $$$k < i$$$, must be added as $$$a_i \times k$$$.
Lets keep two classic range_sum_position_add data structures. First, call it f, takes $$$a$$$ as is. Second, call it t, as $$$a_i \times i$$$. It means, if we need to proceed adding $$$x$$$ on prefix $$$i$$$, we call f.position_add(i, x) and t.position_add(i, x*i).
To answer prefix sum query we need:
all values inside: it will be t.range_sum(1, i+1),
all values outside: it will be f.range_sum(i+1, n+1) * i.
That's all! With help of Binary Indexed Tree, as most popular rsq, we can achieve fast, non recursive and short way to implement required data structure.
We can change prefix/prefix to other three combinations and get similar formulas. As example, my code library have prefix/suffix version to achieve only prefix summation and suffix addition in both nested BITs:
sqrt versionsIt is well-known that with classic sqrt-decomposition queries can be proceeded in $$$O(\sqrt n)$$$ each. But with described reducing to range_sum_position_add we can achieve $$$O(1)$$$ / $$$O(\sqrt n)$$$ or $$$O(\sqrt n)$$$ / $$$O(1)$$$ versions for range_add / range_sum.
First is simple, adding to one element followed with adding to block contain this element, and summation is sum of $$$O(\sqrt n)$$$ blocks and sum of $$$O(\sqrt n)$$$ corner elements.
Second needs reducing range_sum_position_add to position_sum_range_add: lets support suffix sums (which gives sum on range as difference of two suffixes in $$$O(1)$$$) and changing one element $$$i$$$ affecting only suffixes sums from $$$0$$$ to $$$i$$$ (this part takes $$$O(\sqrt n)$$$).
Given a rooted tree.
Suppose query (v,d) is set of vertices in subtree of v in depth d from v.
Let's take all possible queries and leave only distinct sets.
Sum of sizes of these sets is $$$O(n\sqrt{n})$$$.
Actually, idk how to prove it. If you know proof, please post it here.
I met it in one Gerald's lecture with proof like "try to construct worst case and you see it".
I can construct such family of trees with $$$f(k)\approx \frac{n \sqrt n}{2}$$$ where $$$n(k) = \frac{k(k+1)}{2}$$$
Here tree with k=4: 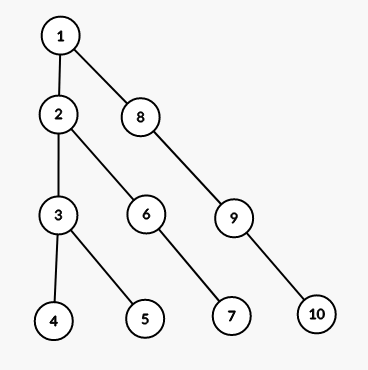
Only two times I tried to apply this as base of my solutions. But it was 1) useless — there are was easiest ones 2) painfull.
If you have some problems for this feature, post it please.
Есть довольно известная задача для заданного массива чисел и числа $$$K$$$ найти минимумы для всех отрезков длины $$$K$$$.
Более общий вариант: дан массив чисел длины $$$n$$$ и $$$q$$$ запросов о поиске минимума на отрезках $$$[l_i,r_i]$$$, причём $$$l_i \leq l_{i+1}$$$ и $$$r_i \leq r_{i+1}$$$. Решение должно работать за $$$O(n+q)$$$.
Решением задачи является поддержка скользящего окна, в котором хранится отрезок чисел. Нужна структура данных, умеющая в push_back (добавить элемент в конец окна), pop_front (удалить первый элемент окна) и get_min — текущий минимум.
С удивлением обнаружил, что такую структуру можно реализовать двумя способами. Первым является популярным и легко ищется в сети. Тем не менее, всю жизнь я использовал другой способ (который найти в сети не получается). Опишу их оба.
Идея в том, чтобы хранить последовательность возрастающих минимумов. Первый элемент последовательности равен минимуму всего текущего окна, следом идёт минимум на суффиксе после этого элемента, и так далее. Например, для значений в окне [2,3,1,5,4,8,7,6,9] это будут минимумы [1,4,6,9].
Когда происходит добавление элемента справа (incR, push_back), последовательность меняется следующим образом: все большие элементы убираются, сам элемент добавляется в конец.
Несколько примеров, для [1,4,6,9]:
Добавление 5: [1,4,6,9] -> [1,4] -> [1,4,5]
Добавление 100: [1,4,6,9] -> [1,4,6,9,100]
Добавление 0: [1,4,6,9] -> [] -> [0]
При удалении элемента слева (incL, pop_front) нужно знать, был ли главный минимум первым элементом окна. По значению этого не понять, поэтому в последовательности помимо самих значений нужно хранить в паре с ними позиции этих значении. Пример выше превратится в последовательность [(1,2), (4,4), (6,7), (9,8)], если элементы нумеруются с нуля. Границы текущего окна нужно хранить явно в виде пары чисел $$$L$$$ и $$$R$$$. Итак, если первый элемент последовательности является первым элементом окна, то есть его позиция равна $$$L$$$, то его необходимо просто удалить, более ничего в последовательности не изменится.
Для реализации потребуется структура данных, позволяющая эффективно делать операции удаления слева и справа, а также добавления справа. Для этого можно использовать дек (std::deque в c++)
Представим окно в виде двух стеков: префикс окна находится в левом стеке $$$L$$$ так, что первый элемент окна вверху $$$L$$$, а суффикс окна в правом стеке $$$R$$$ так, что последний элемент окна вверху $$$R$$$.
[2,3,1,5,4,8,7,6,9]<-------|--------->
L = [5,1,3,2]R = [4,8,7,6,9]
Когда происходит добавление элемента справа (incR, push_back), элемент попадает в вершину правого стека
При удалении элемента слева (incL, pop_front), элемент уходит с вершины левого стека. Исключение составляет случай, когда в этот момент левый стек пуст. Тогда перед удалением происходит операция перебрасывания правого стека в левый: пока правый стек не закончится, его верхний элемент перемещается в левый стек. Например,
[4,3,1,2]|------->
L = []R = [4,3,1,2]
L = [2]R = [4,3,1]
L = [2,1]R = [4,3]
L = [2,1,3]R = [4]
L = [2,1,3,4]R = []
[4,3,1,2]<-------|
Теперь, после перебрасывания, из левого стека можно удалять верхний элемент.
Чтобы отвечать в любой момент о текущем минимуме в окне нужно знать минимумы в стеках. Так как правый стек только увеличивается или очищается полностью, его минимум можно поддерживать в отдельной переменной $$$Rmin$$$.
В левом стеке вместо самих значений нужно хранить минимум среди значений от этого элемента до дна стека. Например для стека [5,7,3,4,2,1,8,6] это будет стек [5,5,3,3,2,1,1,1]
Итого, минимум в окне будет равен либо верхнему элементу левого стека, либо $$$Rmin$$$.
Оба решения работают за одинаковую ассимптотику. Второе считаю более простым для понимания как алгоритм, но в первом меньше кода. Про сравнительное время работы ничего сказать не могу.
Также, оба решения можно проапгрейдить до операции push_front, хотя кажется, такая операция нигде не нужна.
We have n points (xi, yi). Let both x and y be different and from [1, n].
Initially, all points have zero value.
Two types of queries:
1) add X — adding +1 to all points with xi ≤ X
2) sum Y — calculate sum of values of points with yi ≤ Y
What is best known solution? (Problem not from running contest).
I've heard more about how vector<bool> is slow, and we need to dodge him or use vector<char>.
But today I ran some tests in "Codeforces custom test" with GNU G++.
First simple erato sieve
//N = 3e7
for(int i=2;i<N;++i) if(!u[i]) for(int j=i*2;j<N;j+=i) u[j] = 1;
int cnt = 0;
for(int i=0;i<N;++i) if(u[i]) ++cnt;
cout<<cnt<<endl;
Depends on u:
bool u[N] : 420 ms, 31204 KB
vector<bool> u(N): 218 ms, 5484 KB
vector<char> u(N): 451 ms, 31164 KB
You can say like "memory constant speed up this code"
Second.
//N = 1e4
double total = 0;
for(int it=0;it<N;++it){
for(int i=0;i<N;++i){
int x = rand()%N;
u[x] = 1;
}
for(int i=0;i<N;++i){
int x = rand()%N;
u[x] = 0;
}
for(int i=0;i<N;++i){
total+=u[i];
u[i] = 0;
}
}
cout<<total/N<<endl;
bool u[N] : 2683 ms, 1860 KB
vector<bool> u(N): 2667 ms, 1832 KB
vector<char> u(N): 2620 ms, 1868 KB
We see its equal!
So maybe its not so bad? Or you have examples where vector<bool> is really slower than alternatives?
Your given a simple task:
For given number 2 ≤ n ≤ 1018 check prime or not it is.
Limits are: 1 second TL, 16Mb ML.
And we have solution:
bool isprime(LL n){
if(n<2) return false;
for(LL i=2;i*i*i<=n;++i) if(n%i==0) return false;
for(int it=0;it<1e5;++it){
LL i = rand()%(n-1)+1;
if(__gcd(i,n)!=1) return false;
if(mpow(i,n-1,n)!=1) return false;
}
return true;
}
where rand() returns 64-bit random integer and mpow(a,b,m) is ab modulo m.
Can you challenge this solution?
Hi people! I interested in problems with template name "Count of subrectangles" or "Best subrectangle" in rectangle. For example some well-known problems:
In given matrix of zeros and ones find subrectangle that contains only zeros and has largest area. It can be solved in O(n2).
In given matrix of integers find subrectangle with largest sum. It can be solved in O(n3).
Can you give me links or just statements on similar problems?
Here problems that i remembered:
Please, gimme other problems, any links in contests or archives:) I will add it here later.
Хотелось бы узнать, как проводится подготовка и проведение четвертей в разных регионах. Точно интересуют следующие вопросы:
Как готовятся задачи (полигон, папка на компе, папка в облаке и т.д.);
В чём проводится тур (известная система, или нет, название);
Кем прорешиваются задачи (коллектив авторов, или есть вообще деление на авторов — подготовителей — прорешивающих);
Условия задач на английском или на русском?
Интересна любая информация с разных регионов.
Всем привет!
Многим известны соревнования Google Code Jam, Facebook Hackercup, IPSC, ch24, deadline24 и т.п. Их объединяет то, что в задаче даётся инпут с мультитестом внутри, на который нужно посчитать ответ у себя локально. Мне стало интересно, пользуетесь ли вы распараллеливанием? Современные машины позволяют дать ощутимый прирост, например, чтобы избежать таких ситуаций.
А прошедший deadline24 мы писали так
Я решил написать свой вариант шаблона, и вот что у меня получилось: code.
Вот ещё другой подход от kormyshov: code.
Кто может предложить другие варианты, желательно на с++? А может на других языках это делается проще? А может у кого-то есть инструменты, позволяющие параллелить инпут на несколько машин (кроме рук и флешки:)? Интересны любые ответы и замечания по теме.
Производство остановится только в том случае, если существует такое целое K ≥ 0, что a·2K делится на m. Из этого следует, что K может быть максимум порядка log2(m). Так как K — это по сути сколько пройдёт дней до этого момента, то можно промоделировать описанные в условии задачи действия, например, в течение 20-ти дней (не забыв при этом про 64-битный тип данных). Если в какой-то момент производство остановилось, то ответ "Yes". Если не остановилось в течение этих дней, то оно не остановится никогда, а значит ответ "No".
Найдём минимальную длину, необходимую чтобы покрыть все точки по оси Ox — это будет в точности Maximum(xi) - Minumum(xi). Аналогично и для оси Oy — это Maximum(yi) - Minumum(yi). Так как нам необходим квадрат, то следует взять максимальную из этих двух величин в качестве длины его стороны.
Опишем функцию f(L, R), которая будет ответом на задачу. Она ведёт себя следующим образом:
если L = R, то f(L, R) = L;
иначе, если 2b ≤ L, где b — максимальное целое число такое, что 2b ≤ R, то f(L, R) = f(L - 2b, R - 2b) + 2b;
иначе, если 2b + 1 - 1 ≤ R, то f(L, R) = 2b + 1 - 1;
иначе f(L, R) = 2b - 1.
Итоговая сложность — O(logR) на один запрос.
Переберём все различные числа aj исходной последовательности. Так как нужно максимизировать 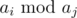 , то переберём в цикле по x все числа, кратные aj в диапазоне от 2aj до M, где M — удвоенное максимальное значение элемента последовательности. Для каждого такого числа нужно найти максимальное ai, такое, что ai < x. Ограничения на числа позволяют сделать это за O(1) при помощи массива. Обновим ответ величиной . Так как перебираются только различные aj, то итоговая сложность составит O(nlogn + MlogM).
, то переберём в цикле по x все числа, кратные aj в диапазоне от 2aj до M, где M — удвоенное максимальное значение элемента последовательности. Для каждого такого числа нужно найти максимальное ai, такое, что ai < x. Ограничения на числа позволяют сделать это за O(1) при помощи массива. Обновим ответ величиной . Так как перебираются только различные aj, то итоговая сложность составит O(nlogn + MlogM).
Заметим, что d-сортировка не зависит от того, какие символы находятся в строке, а значит является перестановкой (назовём её P). Посмотрим на операцию перемешивания по другому: вместо того, чтобы переходить к очередной следующей подстроке и сортировать её, сделаем циклический сдвиг всей строки на один символ влево. Таким образом, сортироваться будет только префикс строки, а строка сдвигаться. Осталось понять, что сдвиг влево — это тоже перестановка (назовём её C). Теперь всё просто, к строке нужно поочерёдно применять перестановки P и C, то есть нужно получить S·P·C·P·C... = S·(P·C)n - k + 1. После этого строку нужно сдвинуть ещё на k - 1 символ влево, чтобы получить то, что получится после операции перемешивания. Здесь используется умножение перестановок, а оно в свою очередь ассоциативно, а значит для вычисления (P·C)n - k + 1 можно воспользоваться бинарным алгоритмом. Итоговая сложность составит O(nmlogn).
Заметим, что существует оптимальный ответ такой, что любой отрезок, который образует группу, содержит свои максимальные и минимальные значения на границах. Иначе было бы выгодно разбить отрезок хотябы на два. Так же можно заметить, что каждый отрезок будет строго монотонным (элементы на нём строго возрастают или убывают). Выделим интересные точки в последовательности — это либо локальные максимумы (то есть ai - 1 < ai > ai + 1), либо минимумы (ai - 1 > ai < ai + 1), либо соседние с ними точки. Будем решать задачу методом динамического программирования, Di — наилучший ответ для префикса i. Тогда при вычислении очередного значения необходимо обработать не более трёх предыдущих интересных точек, а так же предыдущую точку. Итоговая сложность — O(n).
Заметим, что при поиске ответа на конкретный запрос можно воспользоваться бинарным поиском по ответу. Пусть в какой-то момент зафиксировалась высота h и необходимо узнать, помещается ли прямоугольник размера w на h в участок забора с l-ой по r-ой доски включительно. Заведём перед обработкой запросов структуру данных, которая поможет отвечать на такой вопрос. Это будет персистентное дерево отрезков с необычной функцией: максимальное количество подряд идущих единиц на отрезке (далее maxOnes). В листьях дерева будут только числа 0 и 1. Чтобы реализовать такую функцию, необходимо ввести ещё некоторые величины, а именно:
len — длина отрезка в вершине дерева отрезков, prefOnes — длина префикса, полностью состоящего из единиц, sufOnes — длина суффикса, полностью состоящего из единиц.
Вычисляются эти функции следующим образом:
maxOnes, требуемая функция, равна max(maxOnes(Left), maxOnes(Right), sufOnes(Left) + prefOnes(Right));
prefOnes равна prefOnes(Right) + len(Left) в случае, если len(Left) = prefOnes(Left), иначе она равна prefOnes(Left);
sufOnes равна sufOnes(Left) + len(Right) в случае, если len(Right) = sufOnes(Right), иначе она равна sufOnes(Right);
len = len(left) + len(Right);
Left и Right — соответственно левый и правые сыновья текущей вершины в структуре дерева отрезков.
Как уже упоминалось выше, дерево должно быть персистентным (то есть хранить все свои версии после изменений), строиться оно должно следующим образом. Сначала строится пустое дерево — из одних нулей. Далее в позицию, где в заборе находится самая высокая доска, ставится единица. Тоже самое делается для второй по убыванию высоты доски и так далее. Например, если забор описывался последовательностью [2, 5, 5, 1, 3], то изменения последнего слоя дерева будут следующими:
[0, 0, 0, 0, 0] -> [0, 1, 0, 0, 0] -> [0, 1, 1, 0, 0] -> [0, 1, 1, 0, 1] -> [1, 1, 1, 0, 1] -> [1, 1, 1, 1, 1].
При этом для каждой высоты hi нужно запомнить соответствующую версию дерева, назовём её как treeheight. Теперь, чтобы ответить на вопрос выше, нужно сделать запрос на отрезке [l, r] у дерева treeh. Если maxOnes этого запроса меньше w, то прямоугольник невозможно разместить, иначе возможно.
Построение дерева займёт O(nlogn) времени и памяти. Ответ на запрос займёт O(log2n) времени.
Привет всем!
Сегодня состоится Codeforces Round #276, который пройдёт в обоих дивизионах. Время старта — 19:30 по московскому времени (перейдите по ссылке для просмотра времени в других регионах). За помощь в подготовке контеста спасибо Zlobober, за перевод на английский спасибо Delinur, и спасибо MikeMirzayanov за сам проект Codeforces.
Желаю всем удачи, надеюсь, вам понравятся задачи :)
UPD Разбалловка в обоих дивизионах будет динамическая (подробнее об этом можно почитать здесь). Задачи будут упорядочены по возрастанию сложности, тем не менее, не забудьте прочитать все задачи до конца контеста.
UPD Контест окончен! Спасибо всем, кто решал задачи несмотря ни на что. Разбор будет опубликован позднее.
UPD Разбор можно найти здесь. На моё удивление задача div1C оказалась довольно сложной и по количеству посылок сравнялась с div1E, а во втором дивизионе эту задачу вообще никто не сдал за время контеста. Удачи вам в покорении разбора :)
Привет сообществу CodeForces! Рад сообщить о предстоящем 256-м раунде, который пройдёт для представителей второго дивизиона. Представители первого дивизиона смогут поучаствовать вне конкурса.
Надеюсь, для всех это юбилейный раунд. Для меня же это первый раунд, в котором я являюсь автором, по-этому я буду рад видеть всех. Хочу поблагодарить Gerald'а, который помог с подготовкой контеста, Delinur за перевод условий, и конечно MikeMirzayanov за сам проект CodeForces.
Я сам из Красноярска, а героем задач будет наш незаменимый командный талисман Бизон-Чемпион. Надеюсь, вам понравится провести с ним время:) До встречи и удачи!
UPD. До начала соревнования осталось несколько часов. Стоимость задач будет динамической (подробнее об этом можно почитать здесь).
UPD. Раунд завершился, разбор можно прочитать здесь.
Решение:7139559
Так как награды одного типа можно ставить на одну полку, то посчитаем общее количество кубков a и общее количество медалей b. Чтобы узнать минимальное количество полок, которое потребуется например для кубков, можно посмотреть на целую часть дроби a / 5 и учесть остаток. Но можно воспользоваться и более лаконичной формулой: (a + 5 - 1) / 5. Аналогично считается и минимальное количество полок для медалей: (b + 10 - 1) / 10. Если сумма этих величин превосходит n, то разместить награды нельзя, иначе можно.
448B - Про суффиксные структуры
Решение:7139584
Рассмотрим каждый случай отдельно. При использовании только суффиксного автомата от строки останется какая-то её подпоследовательность. Проверить, является ли t подпоследовательностью s можно разными способами, но самый простой и самый быстрый — известный метод двух указателей. При использовании только суффиксного массива можно добится любой перестановки символов исходной строки. Если вам не очевидно это, советую подумать, почему это так. Тем самым s и t должны быть анаграммами. Так ли это, можно проверить, посчитав количество каждой буквы в обоих строках. Если каждая буква входит в s столько же, сколько и в t, то это анаграммы. Осталось проверить случай применения обоих структур. Общая стратегия здесь такая: удалить ненужные символы и сделать нужную перестановку. Так ли это, можно проверить похожим образом, как и со случаем анаграмм, но каждая буква должна входить в s не меньшее число раз, чем в t. Если же ниодна проверка не выполнилась, то получить t из s невозможно. Итоговая сложность O(|s| + |t| + 26).
Решение:7139610
Для решения нужно понять несколько простых вещей. Например, каждая горизонтальная полоса должна быть как можно шире, то есть не упираться своими краями в другие полосы, так как иначе будет не оптимально. Вторая мысль — под каждой горизонтальной полосой могут быть только горизонтальные полосы, так как опять же, иначе это не оптимально. По-этому, если низ забора будет покрашен горизонтальным мазком, то этих мазков должно быть не менее min(a1, a2, ..., an). Эти мазки красят низ забора и, возможно, разбивают забор на несколько непокрашенных несвязных частей. Для каждой из этих частей нужно вызвать решение, учитывая что некоторая нижняя часть забора покрашена, и проссумировать эти значения. Теперь понятно, что функция рекурсивная — ей передаются границы отрезка l, r (часть забора) и уже покрашеная горизонтальными мазками высота h. Но нужно не забыть ещё про один вариант — когда нет горизонтальных мазков и все доски красятся вертикально. Это означает что ответ на отрезке следует ограничить числом r - l + 1. При данных ограничениях на n минимальный элемент на отрезке можно находить наивно, пробекаясь по отрезку [l, r]. Суммарная сложность в этом случае составит O(n2). Но если использовать для нахождения минимума например, дерево отрезков, то можно добиться сложности O(nlogn).
Решение:7139620
Воспользуемся бинарным поиском по ответу. Нам нужно найти такое максимальное x, что количество чисел из таблицы, меньших x, строго меньше k. Чтобы посчитать это количество для фиксированного x, просуммируем количество меньших чисел в каждой строке. В i-й строке их будет 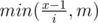 . Тем самым итоговая сложность — O(nlog(nm)).
. Тем самым итоговая сложность — O(nlog(nm)).
Решение:7139644
Научимся превращать Xi в Xi + 1. Для этого нужно действовать по определению и конкатенировать списки делителей каждого элемента Xi. Чтобы это сделать эффективно, предпосчитаем все делители числа X (потому что для любого i, Xi будет состоять только из его делителей). Это можно сделать стандартным методом за 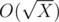 . Как посчитать делители делителей? Нужно знать, что для данных в задаче ограничений на X, максимальное количество делителей D(X) будет 6720 (у числа 963761198400), а значит, делители делителей можно посчитать за O(D2(X)). Имея эти списки, можно превратить Xi в Xi + 1 за время O(N), где N = 105 — ограничение на количество элементов в выводе. Теперь научимся превращать Xi в X2i. Что нам говорит последовательность Xi? Помимо того, куда перейдёт X за i шагов, она может сказать, куда перейдёт каждый делитель числа X за i - 1 шаг. На самом деле, Xi является конкатенацией всех Yi - 1, где Y — делители X. Например, 103 = [1, 1, 1, 2, 1, 1, 5, 1, 1, 2, 1, 5, 1, 2, 5, 10] = [1] + [1, 1, 2] + [1, 1, 5] + [1, 1, 2, 1, 5, 1, 2, 5, 10] = 12 + 22 + 52 + 102. Как узнать какой отрезок соответствует какому-то Y? Пусть pos(Y) — позиция первого вхождения числа Y в Xi. Тогда нужный отрезок будет начинаться в pos(prev(Y)) + 1, а заканчиваться в pos(Y). prev(Y) — это предыдущий перед Y делитель X (если их упорядочить по возрастанию). Итак, чтобы получить X2i из Xi, нужно для каждого элемента знать, куда он перейдёт за i шагов. Мы знаем его делители — это один шаг, а для каждого делителя знаем, куда он перейдёт за i - 1 шаг. Тем самым, нужно сконкатенировать нужные отрезки в определённом порядке. Это так же можно сделать за O(N). Как теперь найти Xk для любого k? Способ похож на алгоритм быстрого возведения числа в целую степень:
. Как посчитать делители делителей? Нужно знать, что для данных в задаче ограничений на X, максимальное количество делителей D(X) будет 6720 (у числа 963761198400), а значит, делители делителей можно посчитать за O(D2(X)). Имея эти списки, можно превратить Xi в Xi + 1 за время O(N), где N = 105 — ограничение на количество элементов в выводе. Теперь научимся превращать Xi в X2i. Что нам говорит последовательность Xi? Помимо того, куда перейдёт X за i шагов, она может сказать, куда перейдёт каждый делитель числа X за i - 1 шаг. На самом деле, Xi является конкатенацией всех Yi - 1, где Y — делители X. Например, 103 = [1, 1, 1, 2, 1, 1, 5, 1, 1, 2, 1, 5, 1, 2, 5, 10] = [1] + [1, 1, 2] + [1, 1, 5] + [1, 1, 2, 1, 5, 1, 2, 5, 10] = 12 + 22 + 52 + 102. Как узнать какой отрезок соответствует какому-то Y? Пусть pos(Y) — позиция первого вхождения числа Y в Xi. Тогда нужный отрезок будет начинаться в pos(prev(Y)) + 1, а заканчиваться в pos(Y). prev(Y) — это предыдущий перед Y делитель X (если их упорядочить по возрастанию). Итак, чтобы получить X2i из Xi, нужно для каждого элемента знать, куда он перейдёт за i шагов. Мы знаем его делители — это один шаг, а для каждого делителя знаем, куда он перейдёт за i - 1 шаг. Тем самым, нужно сконкатенировать нужные отрезки в определённом порядке. Это так же можно сделать за O(N). Как теперь найти Xk для любого k? Способ похож на алгоритм быстрого возведения числа в целую степень:
при k = 0 Xk = [X],
при нечётном k выполнить переход от Xk - 1 к Xk,
при чётном k выполнить переход от Xk / 2 к Xk.
Такой метод делает O(logk) итераций. Кстати, так как при X > 1 последовательность Xk будет иметь префикс из k единиц, то k можно ограничить числом N. Итоговая сложность составит 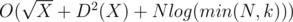 .
.
Здравствуй, сообщество CodeForces!
Пишу я задание для получения зачёта по проге и сталкиваюсь со следующей проблемой. В общем, имеется игра Реверси. Имеются несколько типов ботов, из них:
жадный: ходит самым максимальным из доступных ходов (greedy)
перебор minmax дерева игры глубиной до N (aiN)
то же, что и выше, но написанное с ab-отсечением. (aiN_ab)
Имеется проблема:
Счёт за 300 игр:
ai4 vs. greedy — 287:8 и это, я считаю, нормально
ai4_ab vs. greedy — 250:47 и это не очень нормально.
Насколько я понимаю, аб-отсечения должны давать такой же результат, но быстрее. Собственно имеется вопрос: это не так или я делаю что-то не так? Исходники-примеры я брал отсюда, отсюда, отсюда и ещё с некоторых других источников (мой код). Результат везде одинаковый. Может у кого-то есть реальный пример какой-то игры, а не просто сатья-мануал? Ну или какие-то комментарии по этому поводу, буду очень признателен.
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3843 |
| 2 | jiangly | 3705 |
| 3 | Benq | 3628 |
| 4 | orzdevinwang | 3571 |
| 5 | Geothermal | 3569 |
| 5 | cnnfls_csy | 3569 |
| 7 | jqdai0815 | 3530 |
| 8 | ecnerwala | 3499 |
| 9 | gyh20 | 3447 |
| 10 | Rebelz | 3409 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | maomao90 | 171 |
| 2 | awoo | 163 |
| 3 | adamant | 162 |
| 4 | TheScrasse | 158 |
| 5 | nor | 153 |
| 5 | maroonrk | 153 |
| 7 | -is-this-fft- | 152 |
| 8 | Petr | 146 |
| 9 | orz | 145 |
| 10 | pajenegod | 144 |







