


Добрый день.
Теперь Codeforces станет удобнее просматривать с мобильных платформ. Для большинства из них теперь доступен мобильный вид, при котором меню уходит в левую выдвижную панель, а сайдбар — в правую. Обе панели доступны либо по специальным иконкам вверху страницы, либо по свайпу влево/вправо. Скрывать их можно либо тычком в основную область страницы, либо обратным свайпом. В мобильном виде основные шрифты чуток увеличены, что на большинстве экранов можно читать сайт уже без увеличения.
Вот так, например, сайдбар выглядит на моем телефоне:
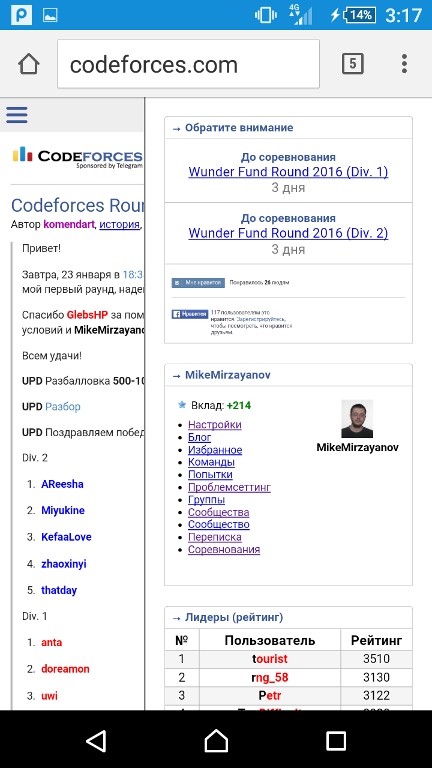
Отказаться от мобильного вида (или, наоборот, включить его) можно внизу страницы в футере.
P.S. На старых браузерах, да и вообще на не-webkit могут быть сложности. Не уверен, что их легко исправить :-(










 (на один тест в наборе).
(на один тест в наборе).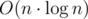 (на сортировку).
(на сортировку).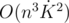 (
(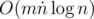 (для обработки одной прямой нужна сортировка всех точек пересечения её и многоугольника).
(для обработки одной прямой нужна сортировка всех точек пересечения её и многоугольника).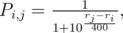
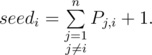
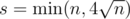 . Если
. Если 














