


Во-первых, поздравляем jqdai0815 с победой, LHiC и jcvb со вторым и третьим местом. Финал оказался сложным и мы рады, что борьба была жесткой.
Задачи для раунда придумали и готовили Aksenov239, GShark, izban, manoprenko, niyaznigmatul, qwerty787788 и SpyCheese, руководитель жюри andrewzta. Отдельно хочется отметить Илью Збаня izban, который является автором задач D, E и F, а также дал огромное количество полезных комментариев по всем задачам раунда.
Теперь перейдем к разбору.
Для начала докажем, что ответ всегда YES.
Будем последовательно перебирать bj и проверять, что при суммировании его со всеми ai мы не получим сумму, которую уже можно получить другим способом.
Оценим максимальный элемент в множестве B. Посмотрим, почему некоторый элемент bj2, может не подходить. Это означает, что ai1 + bj1 = ai2 + bj2, то есть bj2 = bj1 - (ai2 - ai1). Каждый элемент B таким образом запрещает O(n2) различных значений, из чего следует, что max(B) есть O(n3) в худшем случае, поэтому, в частности, при заданных ограничениях ответ всегда существует.
Теперь ускорим проверку, что очередной элемент подходит. Заведем массив bad, в котором будем отмечать числа, которые в дальнейшем не подойдут для множества B. Теперь при переборе bj, если текущее число не отмечено в bad, то его можно взять в ответ. В дальнейшем в ответ нельзя будет взять числа, которые равны bj + ai1 - ai2, отметим их в массиве bad. Сложность решения O(n3).
Рассмотрим следующий граф: множеством вершин в нем будет множество всех префиксов данных нам слов, ребро будем проводить между двумя вершинами, если соответствующие этим вершинам префиксы являются похожими. Заметим, что количество вершин в этом графе не превышает суммарной длины строк.
Несложно доказать, что получившийся граф будет являться лесом. Действительно, если два префикса похожи, то давайте скажем, что более короткий является родителем более длинного. Таким образом, у каждой вершины есть не более одного родителя, а при переходе к родителю длина уменьшается, поэтому циклов нет. Значит, граф является лесом.
Заметим теперь, что множество, которое состоит из префиксов исходных слов, и не содержит похожих слов, в построенном нами графе является независимым множеством. Построив этот граф, мы сможем применить какой-нибудь из методов нахождения максимального независимого множества в дереве, например, жадность или динамическое программирование.
Рассмотрим два способа построения этого графа.
Способ 1. Хеши
Для каждого префикса посчитаем его хеш, и сохраним все эти хеши. Теперь, для каждого префикса посчитаем его хеш без первой буквы, и проверим, есть ли этот хеш среди хешей всех префиксов. Если есть, то соединим соответствующие префиксы ребром.
Способ 2. Ахо-Корасик
Построим автомат Ахо-Корасик для данного набора строк. Вершинами нашего графа будут вершины автомата. Заметим, что ребро в нашем графе следует провести между двумя вершинами тогда и только тогда, когда глубины этих вершин отличаются на 1, и из одной в другую ведет суффиксная ссылка.
Воспользуемся признаком делимости на одиннадцать. А именно нам необходимо, чтобы сумма цифр, стоящих на нечетных позициях, равнялась сумме цифр на четных позициях по модулю одиннадцать. Значит, во-первых, из числа на карточке нас интересует только сумма его цифр по модулю одиннадцать, где цифры на четных позициях взяты со знаком плюс, а на нечетных — со знаком минус. Во-вторых, для каждой карточки нам интересна четность количества цифр в карточках до нее, а вся остальная информация о других карточках не нужна.
Все карточки разобьем на две группы по четности длины цифр на них. Вначале расставим все карточки, на которых числа нечетной длины. Половина из них будет взята со знаком плюс, а другая половина с минусом. Воспользуемся методом динамического программирования. В состояние будет входить количество уже просмотренных карточек, количество карточек, которое взято со знаком плюс и текущая сумма по модулю одиннадцать. Из каждого состояния всего два перехода — либо взять карточку со знаком плюс, либо со знаком минус.
Если нет ни одной карточки с числом нечетной длины, то вне зависимости от расстановки карточек, остаток от деления на 11 будет один и тот же, так что ответ равен либо 0, либо n!. Иначе, каждое число четной длины можно взять как с плюсом, так и с минусом. Также воспользуемся аналогичным методом динамического программирования, чтобы посчитать количество способов получить некоторый остаток по модулю 11 с помощью карточек с числами четной длины.
В конце объединим результаты для чисел четной и нечетной длины и посчитаем только те варианты, где суммарный остаток от деления на одиннадцать равен нулю. Итого суммарное временем работы O(n2).
Для решения воспользуемся динамическим программированием на корневом дереве. Пусть fv — максимальное число ребер, у которых оба конца лежат в поддереве с корнем в вершине v, и при их добавлении это поддерево становится кактусом.
Для подсчета функции f нужно разобрать два случая: вершина v покрыта каким-нибудь циклом или нет. Если вершина v не покрыта циклом, то fv равно сумме fu, для всех u детей вершины v.
Если же вершина v покрыта циклом, то нужно перебрать, каким именно циклом она покрыта. Для этого переберем все ребра (x, y) такие, что LCA(x, y) = v. Перебрав добавляемое ребро, нужно мысленно удалить этот путь из x в y, посчитать сумму fu по всем u — корням получившихся после удаления этого пути поддеревьев, и прибавить к ней красоту рассматриваемого ребра.
Так мы получили решение за O(nm).
Для ускорения решения придется воспользоваться структурами данных. Во-первых, надо будет вычислить LCA (наименьшего общего предка), чтобы понять, когда следует пытаться добавить это ребро. Любой достаточно быстрый стандартный алгоритм подойдет. Во-вторых, надо быстро вычислять сумму fu всех поддеревьев, получившихся после удаления пути.
Для этого заведем вспомогательные значения: gu = fp - fu, где p — родитель u в дереве, а также sv = sum(fu), где u — дети вершины v. Тогда сумма fu всех поддеревьев после удаления — это сумма значений sx, sy, sv - fx' - fy', суммы на пути [x, x') значения gi и суммы на пути [y, y') значения gi, где x' — это ребенок v, в поддереве которого лежит x и y' — ребенок v, в поддереве которого лежит y. Понадобится структура данных, которая поддерживает изменение в вершине и сумму на пути. Подойдет любая структура для суммы на отрезке, дерево отрезков или дерево Фенвика. Время работы: O((n + m)log(n)).
Любая точка X задаётся двумя углами α = XAB и β = XBA.

Точка (α2, β2) находится в зоне покрытия спутника в точке (α1, β1), если α2 ≤ α1 и β2 ≤ β1.
Пусть два спутника, между которыми нужно установить связь, находятся в точках (α1, β1) и (α2, β2). Ретранслятор должен находиться в такой точке (α0, β0), что α0 ≤ min(α1, α2) и β0 ≤ min(β1, β2). Поскльку требуется, чтобы он не находился в зоне видимости других спутников, следует выбирать α0 и β0 как можно больше: α0 = min(α1, α2), β0 = min(β1, β2).
Перейдём к решению. Рассмотрим запрос типа 3: даны два спутника (α1, β1) и (α2, β2). Нужно проверить, что точку (α0, β0) = (min(α1, α2), min(β1, β2)) не видит ни один другой спутник. Это означает, что среди спутников с α ≥ α0 максимальный β меньше β0.
Отсортируем все спутники из всего теста по α. В каждый момент времени для каждого спутника будем хранить его β, если он сейчас существует, и - ∞, если нет. Построим на этом дерево отрезков на максимум. При добавлении и удалении спутника будем обновлять значения. При запросе типа 3 будем запрашивать максимум на суффиксе. Чтобы не учитывать два спутника из запроса 3, перед запросом максимума присвоим в их ячейки - ∞, а затем вернём соответствующие β.
В этом решении используются числа с плавающей запятой. От них следует избавиться. Для этого не будем явно считать углы. Сортировать по α будем при помощи векторного произведения. Вместо того, чтобы хранить в дереве отрезков β, отсортируем спутники по β при помощи векорных произведений и будем хранить индексы.
Кроме того, нужно проверять, что точка (α0, β0) не лежит внутри планеты. Точка X лежит внутри, если угол AXB тупой, то есть, скалярное произведение XA и XB меньше нуля. Точку X плохо искать в явном виде, так как её координаты не обязательно целые, но векторы, коллинеарные XA и XB, найти можно — это некоторые из векторов, соединяющие точки запроса и точки A и B.
Перейдем в координаты y(x), где x = exp1 - exp2, а y = exp1 (exp1, exp2 — опыт первого и второго игроков в некоторый момент времени соответственно). Будем идти по отрезкам времени и поддерживать множество достижимых состояний на этой плоскости.
Лемма 1: есть оптимальное решение, в котором на всех отрезках, где могут играть оба, оба играют (доказательство в конце).
Есть три перехода:
- Может играть лишь первый игрок t времени. Это значит, что новый многоугольник — сумма Минковского старого многоугольника и вырожденного многоугольника на двух вершинах (0, 0) и (t, t).
- Может играть лишь второй игрок t времени. Это значит, что новый многоугольник — сумма Минковского старого многоугольника и вырожденного многоугольника на двух вершинах (0, 0) и ( - t, 0).
- Могут играть оба игрока t времени. Поскольку не выгодно, чтобы играл лишь один из них (лемма 1), нужно всем точкам с координатами в [ - C;C] прибавить 2t в y-координату, а остальным точкам прибавить t в y-координату.
Посмотрим на структуру множества достижимых точек. Это многоугольник, монотонный относительно оси OX (любая прямая параллельная OY пересекает его в ≤ 2 точках), при чем нижняя ломаная этого многоугольника — y = 0 при x ≤ 0 и y = x при x > 0. Эти два факта непосредственно следуют из того, что все три операции сохраняют эти инварианты. Таким образом, нам интересно следить лишь за верхней огибающей многоугольника.
Покажем, что y-координата верхней части многоугольника у нас будет не убывать с ростом x-координаты, и состоит верхняя часть ломаной из векторов (+1,0) и (+1,+1). Пусть по индукции это верно.
После переходов первых двух типов монотонность сохраняется на всей ломаной: первый переход лишь сдвигает старую верхнюю часть ломаной на (+1, +1), а второй переход сдвигает верхнюю часть ломаной на (-1,0). Но вот операция третьего типа может нарушить монотонность в точке x = C, так там происходит сдвиг по OY на разные величины. Исправим это, несколько изменив смысл многоугольника, который мы поддерживаем: если раньше это было множество всех достижимых состояний, то теперь будем поддерживать монотонное множество точек, возможно не все из которых можно получить, но имеющее такой же максимальный достижимый опыт из любой точки множества.
Для этого докажем лемму: если в момент времени t взять две точки (не важно, достижимы ли они к моменту времени t) P1 = (x1, y1) и P2 = (x2, y2) такие, что C ≤ x1 ≤ x2, и y1 ≥ y2, то ответ для точки P2 не больше, чем ответ для точки P1. Для этого возьмем сертификат, ведущий к оптимальному ответу из точки P2 — это некоторая последовательность переходов первого, второго и третьего типа, и выкинем из нее первых переходов второго типа ровно на x2 - x1 (единственных, уменьшающих x). Можно заметить, что полученный сертификат — корректный набор действий из точки P1, и имеет такой же сдвиг по y, так как области двойного опыта будут ровно такими же (до момента совпадения x-координат его быть не может, т.к. x2 - C ≥ x2 - x1, а с этого момента времени графики движения будут совпадать).
Таким образом, после операции третьего типа можно взять на суффиксе x для [C; + inf) максимум между сдвинутой ломаной и прямой y = y(C). Абсолютно аналогично доказывается, что ломаную можно промажорировать прямой y = y(C) - (C - x) на отрезке ( - inf;C].
Таким образом, после перехода ломаная все еще осталась монотонно неубывающей, состоящей из ребер (+1,0) и (+1,+1).
Для решения задачи нужно научиться быстро совершать необходимые переходы с этой ломаной.
Легко заметить, что в ней линейное число вершин, так как все операции добавляют константное число новых ребер: первые две не изменяют количество вершин ломаной, а третья создает два новых ребра и, возможно, выкидывает несколько старых.
Можно хранить ломаную в декартовом дереве — тогда легко разрезать ломаную в точках - C и + C, вставить в нужное место новые ребра и удалить несколько старых. Таким образом, получили решение, работающее за O(nlogn).
Лемма 1, доказательство: рассмотрим оптимальное решение, и посмотрим на первый отрезок, где могли играть оба, но играет лишь один. Если |x| = |exp1 - exp2| ≤ C, это делать точно не выгодно. Иначе, для определенности, x < - C. Понятно, что в оптимальном решении точка еще вернется в полосу |x| ≤ C (иначе оба могут спокойно играть). Если сейчас играет лишь первый игрок (прибавляется вектор (+1, +1)), то раньше, естественно, был момент после последнего посещения полосы двойного опыта, когда играл лишь второй игрок (вектор (-1, 0)). Пусть в тот момент второй игрок не играл, а сейчас играют оба, итоговая позиция сохраняется, а первый момент, когда играет один, но не оба, отдалился. Случаи, когда играет лишь первый игрок, и x > C, разбираются абсолютно аналогично, убирая момент времени, когда играет лишь один из игроков, но добавляя момент, когда играют оба.





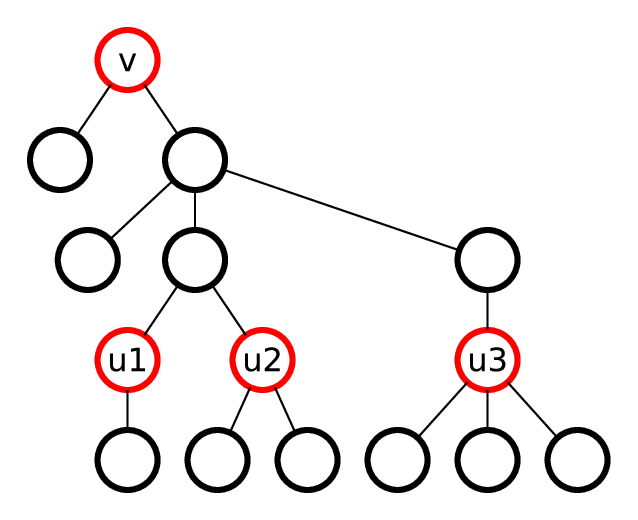


 . Доказать это можно следующим образом. Для некоторой вершины рассмотрим размер компоненты, в которой она находится. Тогда каждый раз, когда она будет рассмотрена, размер этой компоненты уменьшается как минимум в два раза. Заметим, что каждая вершина будет рассмотрена
. Доказать это можно следующим образом. Для некоторой вершины рассмотрим размер компоненты, в которой она находится. Тогда каждый раз, когда она будет рассмотрена, размер этой компоненты уменьшается как минимум в два раза. Заметим, что каждая вершина будет рассмотрена  раз.
раз.