


Hello, Codeforces!
The 2018 ICPC Asia-East Continent Final has ended on last Sunday. At this site, over 380 teams have competed in 5 hours, trying to solve 12 problems.
The problems are prepared by CommonAnts, Claris and me. Thanks to skywalkert, quailty, zscc, yefllower,niike0goood, AHdoc, C_SUNSHINE for discussing and testing the problems, whzzt, sunset, TLE for their amazing performance in the test contest.
Moreover, special thanks to CommonAnts, skywalkert, C_SUNSHINE, Claris, niike0goood for preparing the statement. To ensure the correctness of the statement, they updated it for over 180 times before the conetst. Thanks a lot for their efforts.
Although I had set 6 ICPC contests before, I felt a lot of difference between official contests and online contests during the process of preparing. In response to the responsibility, we tried our best to seek out the most interesting tasks and to make a tradeoff between difficulty and discrimination.
I'm proud of this contest, and I could hardly wait for sharing these interesting ideas to you. So we will hold two online-mirror contests soon, just choose the one which is convenient for you:
- One is this week's OpenCup. The contest will start on Sunday, December 23, 2018 at 16:00 (UTC+8) .
- The other will be held on Codeforces. In our plan, the contest will start on Saturday, December 29, 2018 at 18:00 (UTC+8). The contest follows the ICPC rule and it will be unrated.
Besides, we kindly ask everybody who has already read the problems not to participate or discuss solutions in public before the OpenCup contest has ended. Your cooperation will be greatly appreciated.
Hope you enjoy the problems!
Update: Since the external storage of GYM is not responding for nearly one week, the mirror contest on Codeforces may not be held today as planned. We are so sorry about this delay. We will confirm another date for the mirror contest and update this blog once after the external storage is on.
Update2: It seems like everything is working now. The mirror contest on Codeforces will be held today, Saturday, January 05, 2019 at 18:00(UTC+8). Hope you enjoy the contest :)





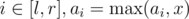 ) operations into interval add/subtract operations in
) operations into interval add/subtract operations in 
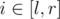 , change
, change 
 and I could not proved the exact time complexity yet, maybe It is still
and I could not proved the exact time complexity yet, maybe It is still 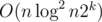 .
.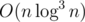 .
.

 each interval min operation.
each interval min operation.
