


1. COLOR
This problem is trivial. Note that we want the resulting string to be monochromatic and thus we can just choose the color with maximal occurences and change the remaining letters into the color.
2. CHBLLNS
This problem is also trivial. For each color, we take k - 1 balls, or if there're less than k - 1 balls, take all the balls. Currently, there are at most k - 1 balls for each color. Then, take one more ball. By pigeonhole principle, there exists k balls of same color. So, this is our answer.
3. CHEFPATH
This problem is not hard. WLOG, assume n ≤ m. If n = 1, then the task is possible if and only if m = 2 for obvious reasons. Otherwise, if m, n are both odd, then coloring the board in a checkerboard fashion can show that no such path exist. If one of m, n is even, then such path exists. (it's not hard to construct such path)
4. BIPIN3
In fact, the answer is the same for any tree. For the root vertex we can select k possible colors. For each children, note that we can select any color except the color of the parent vertex, so there're k - 1 choices. So, in total there are k·(n - 1)k - 1 possible colorings. To evaluate this value, we use modular exponentiation.
5. FIBQ
The idea of this problem is to convert the sum in matrix language. Let T be the matrix[\begin{bmatrix} 1 & 1 \ 1 & 0 \end{bmatrix} ]
Additionally, let I be the identity matrix. Then, our desired answer will be the top right element of (Tal + I)(Tal + 1 + I)...(Tar + I). Now, to support the update queries, just use a segment tree. The segment tree from this link is perfect for the job.
6. DEVGOSTR
Despite it's appearance, this problem is actually very simple. For A = 1, there is at most 1 possible string, namely the string consisting of all `a's. The background of this problem is Van der Waerden's Theorem. According to the Wikipedia page, the maximal length of a good string for A = 2 is 8 and the maximal length for a good string for A = 3 is 26. Now, for A = 2 we can brute force all possible strings. However, for A = 3 we need to brute force more cleverly. The key is to note that if a string s is not good then appending any letter to s will not make it good. So, we just need to attempt to append letters to good strings. This pruning will easily AC the problem.
7. AMAEXPER
Call a point that minimizes the answer for a subtree rooted at r the king of r. If there are mutiple kings choose the one closer to r. The problem revolves around an important lemma :
Lemma : For the subtree rooted at r, consider all children of r. Let l be the children such that the distance from r to the furthest node in the subtree rooted at l is the longest. If there are multiple l, then r is the king. Otherwise, either r is the king of the node in the subtree rooted at l is the king.
Sketch of proof : Suppose not, then the maximal distance from some other vertex will be the distance from that node to root + the distance from root to the furthest node in the subtree rooted at l, so choosing r is more optimal.
Thus, for we can actually divide the tree into chains. A chain starts from some vertex v and we keep going down to the children l. For each node r, we store the distance to root, the maximal distance from r to any vertex in its subtree, as well as the maximal distance IF we don't go down to children l. (this distance is 0 if r has only 1 children) Now, for each chain, we start from the bottom. We also maintain a king counter starting from the bottom. At first, the answer for the bottom node is the maximal distance stored for that node. Then, as we go up to the top of the chain, note that the possible places for the king is on the chain and will not go below the king for the node below. Thus, we can update the king counter in a sliding window like fashion. How do we find the answer for each node? This value can be calculated in terms of the numbers stored on each node, and using an RMQ we can find the desired answer. The details for this will not be included here.
8. FURGRAPH
The key observation for this problem is the following : Instead of weighing the edges, for each edge with weight w, we increase w to the endpoints of the edge (note that for self-loops the vertex will be added twice). Then, the difference of score of Mario and Luigi is just the difference of the sum of weights on the vertices they have chosen, divided by 2. Why? If an edge has its endpoints picked by Mario (or Luigi), then Mario (or Luigi)'s score will increase by 2w. If each person pick one of the endpoints, then the difference of score is unchanged, as desired. Now, Mario and Luigi's strategy is obvious : They will choose the vertex with maximal possible weight at the time, so letting a1 ≤ a2 ≤ ... ≤ an be the weights of the vertices in sorted order, the answer is an - an - 1 + an - 2... + ( - 1)n - 1a1, i.e. the alternating sum of weights in sorted order.
Using this observation alone can easily give us Subtask 2. We can naively store the vertex weights in a map and update as neccesary. For each query, just loop through the map and calculate the alternating sum.
Subtask 3 requires more optimization. We will use sqrt-decomposition with an order statistic tree to store the vertex weights in sorted order. Note that for each update, we're cyclicly shifting the values of al to ar, for some l, r which can be found from our order statistic tree. Then, we update ar as al + w. To efficiently perform these queries, we divide the array (of vertex weights) into  parts of elements each. We start from element l. For each block we store a deque containing the elements, the sum of elements (we store the elements as negative if we want to subtract the value when calculating the alternating sum for convenience), and the sign of the elements in the block. We iterate through the elements and perform the neccesary updates until we reach the end of block. Then, for updating entire blocks, we perform the neccesary updates on the values, negate the sign, and since we're using deque we can pop front and push back the desired element (namely the next element). Then, when we reach the block containing r, we iterate naively again. The total complexity is
parts of elements each. We start from element l. For each block we store a deque containing the elements, the sum of elements (we store the elements as negative if we want to subtract the value when calculating the alternating sum for convenience), and the sign of the elements in the block. We iterate through the elements and perform the neccesary updates until we reach the end of block. Then, for updating entire blocks, we perform the neccesary updates on the values, negate the sign, and since we're using deque we can pop front and push back the desired element (namely the next element). Then, when we reach the block containing r, we iterate naively again. The total complexity is 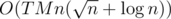 . My solution with this algorithm ACs the problem.
. My solution with this algorithm ACs the problem.
9. CHNBGMT
Unfortunately, I only get the first 3 subtasks to this problem.
This problem is similar to this, except it's harder. The solution for that problem uses Lindstrom-Gessel-Viennot Lemma. We can apply that lemma to this problem as well.
You can see how to apply the lemma from the old CF problem. Now, the problem reduces to finding the number of ways to go from ai to bj for 1 ≤ i, j ≤ 2, and finding the determinant of the resulting 2 by 2 matrix.
For subtasks 1 and 2, M and N are small so we can find these values using a simple dp. In particular, we can use something like dp[i][j][k] = number of ways to get to (i, j) passing through exactly k carrots. Since M, N ≤ 60, this solution can easily pass.
For subtask 3, N, M ≤ 105. However, we are given that C = 0. For N = 2 or M = 2 the answer can be calculated manually. So, from now onwards, we assume M, N ≥ 3. Then finding the values is equivalent to computing binomial coefficients. (The details are trivial). So, all it remains is to know how to compute binomial coefficients mod MOD where MOD ≤ 109 is not guaranteed to be a prime.
Firstly, the obvious step is to factor MOD into its prime factors. Thus, we can compute the answer mod all the prime powers that are factors of MOD and combine the results with Chinese Remainder Theorem. How do we find the result mod pk? This is trivial. We just need to store vp(n) of the numbers and the remainder of the number mod pk when we divide out all factors of p. Now, compute modular inverse mod pk assuming that the value is not divisible by p can be done using Euler's Theorem the same way we find modular inverse mod p.
I would like to know how to get the other subtasks where C > 0.






Auto comment: topic has been updated by zscoder (previous revision, new revision, compare).
Please explain your solution to FIBQ Problem. I solved it using the formula f(a+b) and segment trees for queries and update.
Your solution seems different.
Basically I used matrices (the usual matrix to find Fibonacci numbers) and consider the product stated above. Then, use a basic segment tree to support the queries.