


Hi, Codeforces!
Educational Codeforces Round 4 will take place on 25 December 2015 at 18:00 MSK for the first and second divisions. You can read about educational rounds here and here. This time a little time has passed since the previous round. Although we planned this round at Monday, we forgot to include it to schedule, so it was appeared only now. So it is the fourth and the last educational round this year.
<Maybe this paragraph will not be changed ever>
The round will be unrated for all users and it will be held with extented ACM ICPC rules. You will have two hours to solve six problems. After that you will have one day to hack any solution you want. You will have access to copy any solution and test it locally.
</Maybe this paragraph will not be changed ever>
This time the round was prepared only by me, Edvard Davtyan. Thanks a lot to MikeMirzayanov for helping to invent the problems. Also thanks in advance to Maria Belova Delinur who will check English statements, when they will be ready :-)
I think this time the problems is simpler than usually, because at first we have too hard problemset and removed the hardest problem and added very simple problem. I hope you will enjoy the problems and solve all of them!
Also I want to wish you Happy New Year!!!
Good luck and have fun!
UPD 1: The first phase is ended, hack the solutions of your opponents!
UPD 2: The editorial is ready.







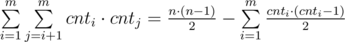 . In first sum we are calculating the number of good pairs, while in second we are subtracting the number of bad pairs from the number of all pairs.
. In first sum we are calculating the number of good pairs, while in second we are subtracting the number of bad pairs from the number of all pairs. . In this case the difference between maximal and minimal elements is
. In this case the difference between maximal and minimal elements is 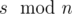 numbers
numbers 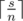 and
and 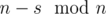 numbers
numbers 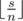 is balanced with the difference equals to
is balanced with the difference equals to 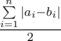 .
.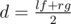 . If
. If 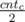 occurences of symbol
occurences of symbol  ,
,
 and
and  , he would get the
, he would get the  ) and should replace exactly one of them with their mediant. In such way first fraction is first parent to the left from mediant while second fraction is parent to the right. The process described in statement is, this way, a process of finding a fraction in the Stern-Brocot tree, finishing when the current mediant is equal to current node in the tree and
) and should replace exactly one of them with their mediant. In such way first fraction is first parent to the left from mediant while second fraction is parent to the right. The process described in statement is, this way, a process of finding a fraction in the Stern-Brocot tree, finishing when the current mediant is equal to current node in the tree and 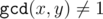 ,
, 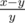 from the root. If
from the root. If 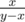 from the root. This gives us Euclidian algorithm, which could be realized to work in
from the root. This gives us Euclidian algorithm, which could be realized to work in  complexity.
complexity.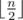 we should consider all
we should consider all 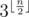 variants. Let in some variant approval values of three companions are
variants. Let in some variant approval values of three companions are 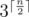 of them) and
of them) and 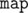 structure or any fast sorting algorithm). If one would then consider every variant from the second half, he just need to find
structure or any fast sorting algorithm). If one would then consider every variant from the second half, he just need to find 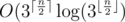 complexity.
complexity.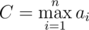 ,
, 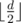 . Let's add them all to
. Let's add them all to 