Привет, Codeforces!
25 декабря 2015 года в 18:00 MSK состоится четвертый учебный раунд Educational Codeforces Round 4 для участников из первого и второго дивизионов. С прошлого учебного раунда в этот раз прошло всего ничего. Несмотря на то, что проведение раунда мы спланировали ещё в понедельник, мы почему-то забыли включить его в расписание, поэтому в расписании раунд только появился. Таким образом, это уже четвертый и последний в этом году учебный раунд.
<Эти два абзаца может быть никогда не изменятся>
О формате и деталях проведения учебных раундов я писал уже ранее. Также об учебных раундах вы можете прочитать здесь.
Раунд будет нерейтинговым. Соревнование будет проводиться по немного расширенным правилам ACM ICPC. На решение задач у вас будет два часа. После окончания раунда будет период времени длительностью в один день в течении, которых вы можете попробовать взломать абсолютно любое решение (в том числе свое). Причем исходный код будет предоставлен не только для чтения, но и для копирования. Таким образом вы можете локально тестировать решение, которое хотите взломать, или, например, запустить стресс-тест.
</Эти два абзаца может быть никогда не изменятся>
Подготовкой задач в этот раз занимался только я (Эдвард Давтян). Пока благодарю, только MikeMirzayanov мы вместе придумывали задачи. Через некоторое время здесь появится благодарность тестеру. Также заранее благодарю Машу Белову Delinur, которая вычитает английские тексты условий, когда они появятся :-)
На этом раунде вам по традиции будет предложено шесть задач. Думаю задачи в этот раз будут немного проще, чем обычно. Это связано с тем, что исходный комплект задач оказался чересчур сложным, поэтому мы убрали самую сложную задачу (она скорее всего будет самой сложной на следующем раунде) и добавили очень простую задачу. Надеюсь комплект задач вам понравится и вы решите все задачи!
Поздравляю всех с наступающим новым годом!!!
Good luck and have fun!
UPD 1: Первая фаза соревнования закончена, ломайте решения соперников!
UPD 2: Опубликован полный разбор задач.







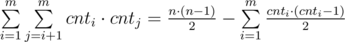 . В первой сумме мы считаем непосредственно количество хороших пар книг, а во втором из общего количества пар книг вычитаем количество плохих пар.
. В первой сумме мы считаем непосредственно количество хороших пар книг, а во втором из общего количества пар книг вычитаем количество плохих пар. . В этом случае разность между минимальным и максимальным будет равна
. В этом случае разность между минимальным и максимальным будет равна 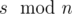 чисел
чисел 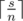 и
и 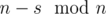 чисел
чисел 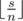 является сбалансированным с разницей минимального и максимального равной
является сбалансированным с разницей минимального и максимального равной 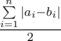 .
.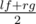 . Если
. Если 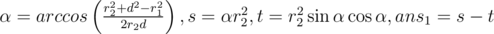 ,
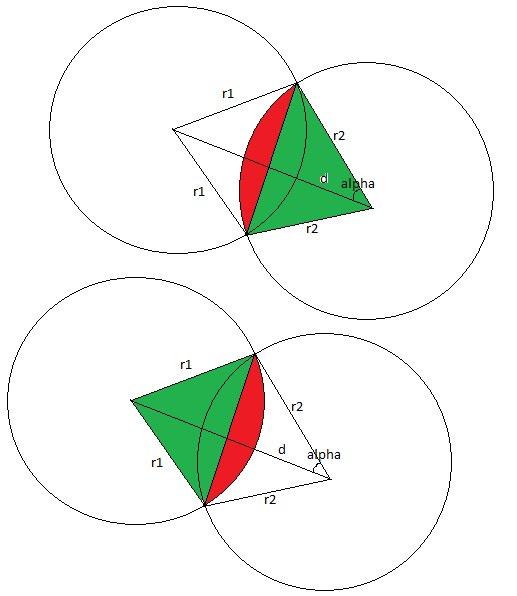
,
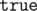 или
или 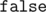 в зависимости от того, можем ли мы попасть из стартовой позиции в
в зависимости от того, можем ли мы попасть из стартовой позиции в 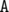 и
и  , то получится дерево
, то получится дерево 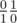 ) и мы заменяем либо первую дробь на их медианту, либо вторую. Таким образом, первая дробь есть первый предок влево от медианты, а вторая — первый предок вправо. Таким образом, искомый процесс это просто процесс поиска дроби в дереве Штерна-Броко, который завершается тем, что текущая медианта совпадает с дробью, которую мы ищем (момент окончания игры, описанный в условии). Значит, числа
) и мы заменяем либо первую дробь на их медианту, либо вторую. Таким образом, первая дробь есть первый предок влево от медианты, а вторая — первый предок вправо. Таким образом, искомый процесс это просто процесс поиска дроби в дереве Штерна-Броко, который завершается тем, что текущая медианта совпадает с дробью, которую мы ищем (момент окончания игры, описанный в условии). Значит, числа 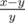 и никуда не спускались. Если же
и никуда не спускались. Если же 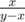 и пока никуда не спускались. Эти рассуждения легко формализовать, чтобы получить строгое доказательство. Таким образом, решение задачи сводится к выполнению алгоритма Евклида для пары чисел
и пока никуда не спускались. Эти рассуждения легко формализовать, чтобы получить строгое доказательство. Таким образом, решение задачи сводится к выполнению алгоритма Евклида для пары чисел 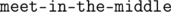 . А именно переберем для первых
. А именно переберем для первых 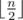 (первая половина) заданий с какими спутницами главный герой будет путешествовать. Пусть при этом симпатия первой спутницы оказалась равна
(первая половина) заданий с какими спутницами главный герой будет путешествовать. Пусть при этом симпатия первой спутницы оказалась равна 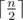 (вторая половина) заданий так и пусть симпатии при этом будут равны
(вторая половина) заданий так и пусть симпатии при этом будут равны 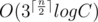 , где
, где 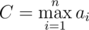 , а
, а 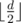 . Сложим все эти строки в
. Сложим все эти строки в  ,
,