


Hi, friends, just out of my curiosity.
Where is Uzhlyandia? Where is Uzhlyandian Park? What is it mean?
And is Uzhlyandian Wars the game exist in reality?
| # | User | Rating |
|---|---|---|
| 1 | tourist | 3880 |
| 2 | jiangly | 3669 |
| 3 | ecnerwala | 3654 |
| 4 | Benq | 3627 |
| 5 | orzdevinwang | 3612 |
| 6 | Geothermal | 3569 |
| 6 | cnnfls_csy | 3569 |
| 8 | jqdai0815 | 3532 |
| 9 | Radewoosh | 3522 |
| 10 | gyh20 | 3447 |
| # | User | Contrib. |
|---|---|---|
| 1 | awoo | 161 |
| 1 | maomao90 | 161 |
| 3 | adamant | 156 |
| 4 | maroonrk | 153 |
| 5 | -is-this-fft- | 148 |
| 5 | atcoder_official | 148 |
| 5 | SecondThread | 148 |
| 8 | Petr | 147 |
| 9 | nor | 144 |
| 10 | TheScrasse | 142 |
Hi, friends, just out of my curiosity.
Where is Uzhlyandia? Where is Uzhlyandian Park? What is it mean?
And is Uzhlyandian Wars the game exist in reality?
Hello, everybody!
Some of clever you maybe already noticed, 2016-2017 ACM-ICPC China Finals were already available in gym several days ago, and I'm glad to share another contest with you on this weekends.
China Collegiate Programming Contest is a local algorithm contest held since last year. This year, it has 3 regional as well as 1 finals. The finals have been hold 2 weeks ago before the ACM-ICPC China Finals, many of us regarded it as a rare practice chance before the latter one.
I think most of you on Codeforces haven't seen the problems yet, so this time, I'd like to schedule a virtual contest with you guys on 2017, Jan. 7th, 12:30:00 (MSK).
Thanks for mathlover who help me import the scoreboard!
Good luck and have fun!
Live
Hello, Codeforces.
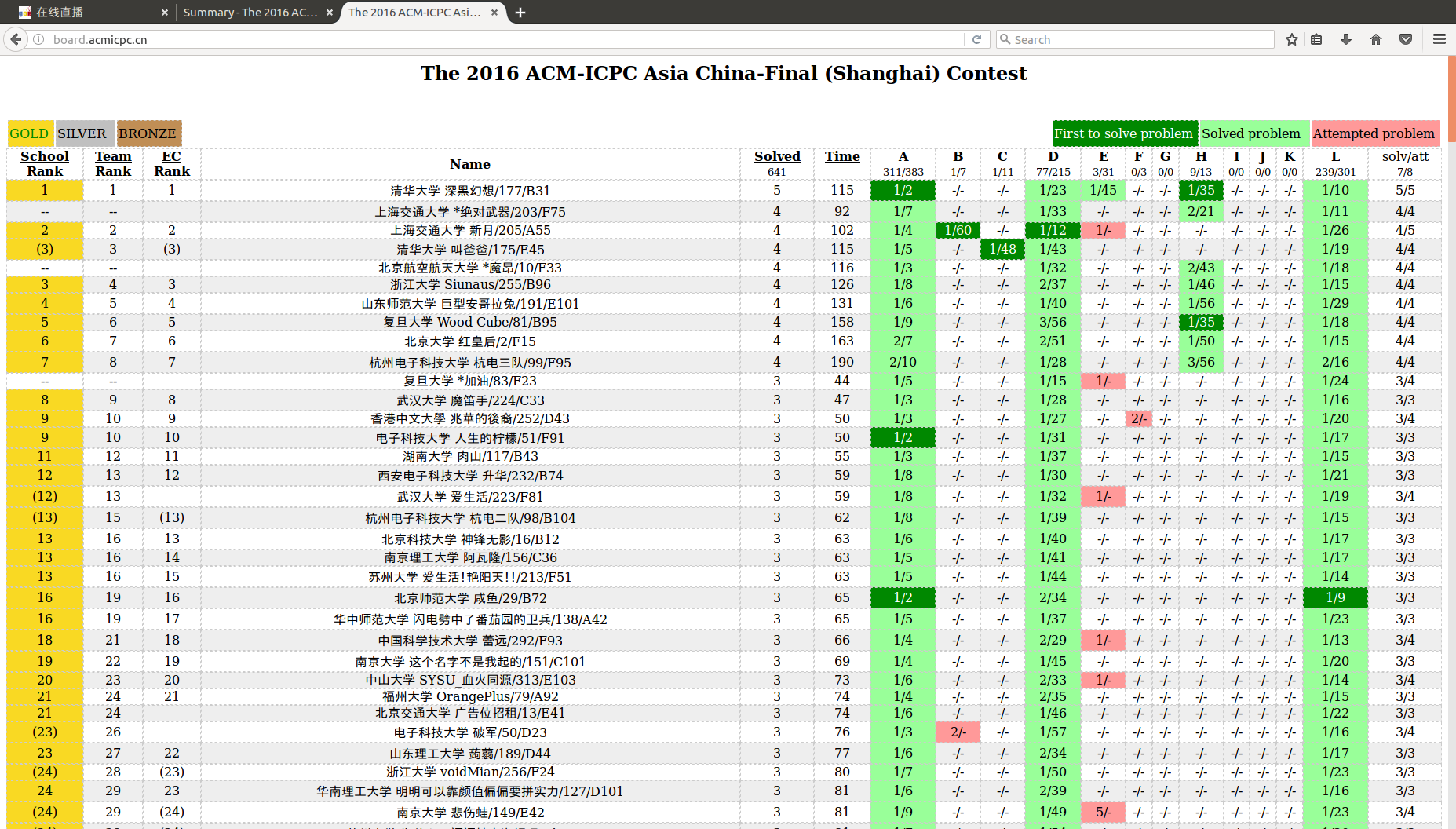
ACM/ICPC China Final 2016 is going to start on this weekends.
Over 300 teams will go to Shanghai University to participate in this contest to complete for the slot of qualifying to the World Final next year. There is no doubt that this will be the most important contest in China this year.

| Team name | Team member 1 | Team member 2 | Team member 3 |
| THU Deep Dark Fantasy | YuukaKazami | jqdai0815 | jcvb |
| SJTU Dread;Weapon | ftiasch | BaconLi | rowdark |
| SJTU New Meta | data_h | xyz2606 | Akigeor |
| FDU Wood Cube | t90tank | SakurakoujiRuna | tun |
Good luck!
Teams advancing to 2016 WF Phuket in Asia have been announced recently. This announcement is undisputedly tantamount to a death sentence for me. I am the one waiting anxiously, refresh Dr. Hwang's blog everyday. But it seems that for years, our training was meaningless.
I think many of us dedicate our passion to programming contests because we see them transparent, fair and without any corruption. And I also believe that as contestants, what we should do is only focus on the practice. And I thought those political business should never come to bother me one day. But sadly, it is my team who is going to become one of the sacrifices of a succession of the dissension.
The quarrel between the Asia director and the local community is a long story to tell. But it has never been as serious as it was in the past season. Now reflecting on this, I know on the surface everything is going okay, but I still feel something wrong. The number of slots is decreasing, as well as the power of those multifarious bonus are rising. So the feeling of the unfairness multiplied. According to this article, before the last day, you do not know the exact X or Y in his algorithm. That means, you can always put any number to these parameters after the contest. And the way he decided to put in those variables, which was quite arbitrary and dictatorial. I am afraid those parameters were used to suppress opponents and those who are close to Dr. Hwang will be easy to pass. Now can it be right, to reject a team on the relationship between the authority? But it is exactly what we do, and now it is almost a open secret for us. If you guys have any opposition, you are directly set yourself to the hard mode. In quicksort, there is a strategy called “killer adversary”, I think that is exactly our situation. In fact, last year in China, the contest divided into 2 events, one called ICPC and another is called CCPC. The CCPC event is simultaneous with Changchun site. And some of the school last year was united to refuse to take part in Changchun Site in order to against the overladen bonus, according to the board, we could see there are lots of strong teams seems didn’t come and take part in the Changchun site. But despite of this, Changchun site still get 1 more slot than other sites, and some site has 3 slots while some site is only 1 slot barely. Is that fair? I don’t think so. Last year, I thought staying in the top 6 could have a chance to enter final… This year, I thought staying in the top 2 must have a chance to enter final. As far as I know, there is no team in our region in history which get 2nd place but cannot go to final. And the logic is the same as what he has done on the Chennai flood. Initially a rule was brought out to reduce the number of slots from Chennai to 1. It was later decided to award an extra slot to Chennai. But it turned out, this extra slot was actually the bonus slot that was going to be given to Amritapuri (as it had proposed to host the world finals in future, smell some sense of Stockholm syndrome?). The net effect is, the number of teams from India is reduced due to postponement rule announced so hastily after the Chennai regional was postponed. This awarding of the extra slot to Chennai is just a sleight of hand designed to look like it is fair.
Well, don’t get me wrong. I am not against the rule this year, I am against the way the rule has been made. The problem with this system, is that it’s this sort of long, slow expansion in personal power. If you don't make a sound this time, things may become more and more dangerous in the future. One of my spiritual idol Aaron Swartz once argued that it was sometimes necessary to break the rules that required obedience to the system in order to avoid systemic evil. So, at my point of view, at least all officials concerned should be consulted. There should be some discussion before taking any decision. The voting should be transparent. The slot calculation is needlessly complicated and could be much simplified. There could be bonus slots but shouldn’t affect the acknowledged game rules. There should be no parameters remain to be determined after the contest. I know in the early day in the ICPC history, Dr. Hwang had done great contribution to bring this event for us. But as times alter, today, the power is overwhelming, and he is stand on the opposite of the sport spirit, the way in which Dr. Hwang makes decision should be questioned. What he has done this time is just to make an example out of us, to use this case for deterrence. So that next time we are submitted to his power. And if we could not do something that take a fair environment back, the reputation of the contest in the sub-region will be badly influenced. Do we really willing to see there are 5 CCPC together with 5 ICPC in the coming season? Do we really need this privilege to keep the health and vitality? I am afraid our students will be seriously exhausted on this issue and the community will appear to diverge further.
Thanks everyone!
Dr. Hwang has just replied to me that he will try after one week for an additional participation slot for Asia. But still said nothing about the X+Y scheme. Looking for the further reaction. The chance is slim. But no matter what outcome will be, I have already felt the warmth of the community!
People always hope strong pretests. There's reasons: it will be a huge lost if someone get the correct solution but fail by tricks (Especially for hard problem). But is that a good taste if we remain all tests in the pretest? Well, I don't think so, there will be no difference between ACM-ICPC rules if we do so.
The question is, the reward of hacking is uncertain while the cost is high. Not only the time, but also it will stop you from resubmitting. Imagine that you solve a problem and found a trick in it, will you lock it immediately? Well, since I do not know whether the trick is involved in the pretests. I prefer only to do hacking until there is no solvable problem.
In Round #201, cgy4ever resubmit the problem C, thus he knew the trick is not involved in the pretests definitely, this is a rare case.
So, what I suggest is, involved some things called detect submission. It won't increased the penalty and will skip during the system test. What the “detect submission” do is to tell you whether a trick is involved in the pretests, it can be only used after you pass the pretests.
With this feature, the risk of hacking could be reduce to a certain extent. So it will also benefit to other participant who doesn't do hacking without excessive strong pretests. Just a imagination, waiting for hear something better then this.
Greeting!
Codeforces Round #259 (Div. 1 and Div. 2) will take place on August 1st, 19:30 MSK.
Setters are: sevenkplus, xlk and me.
Testers are: vfleaking, GuyUpLion, ztxz16 , CMHJT and Trinitrophenol.
Many thanks to Gerald for his help in giving advise about the problems. And we gratefully acknowledge MikeMirzayanov and his team, who bring us the world best competitive programming platform!
Tonight, you will come to Equestria and help our Friendship Princess — Twilight Sparkle to solve those intractable challenges one after another.
Twilight Sparkle is a main protagonist of the series — My Little Pony: Friendship Is Magic.
She is a female unicorn pony who transforms into an alicorn and becomes a princess in the third season of the series. She has a cutie mark of a 6-pointed magenta star with a white one behind it and 5 more smaller ones at each end of the magneta star.

Of course, I guarantee not knowing the storyline and setting won't hold you back from solving these problems~
In Div. 1, scores for each problem will be 500-1000-1500-2500-2500.
In Div. 2, scores for each problem will be 500-1000-1500-2000-2500.
Contest is over! Congratulations to the winners! Here are the top 6 in Div.1 division:
And here are the top 6 in Div.2 division:
Editorial is here.
There are 3 normal tasks accompanied with 2 challenge tasks in div 1 as we usually do. You can check the Statistics by By DmitriyH for detail.
Problem B, C is by sevenkplus, problem D is by xlk and problem A, E is by me.
Problem E is rather complicated then hard, it means if you carefully broke down the problem into smaller ones, it became quite straightforward. During the contest, only kcm1700 managed to solve it successfully.
Problem D, which decided the round boiled down to the following nice Dynamic Programming subproblem: you are given 220 numbers. For each position i between 0 and 220 - 1, and for each distance j between 0 and 20, what is the sum of the numbers with such indexes k that k and i differ in exactly j bits? The fun part is not how to do it T times, it is how to do it even once on 106 numbers.
Petr solve A, B, C, D steadily and fast who indisputably, is the winner of the round. The second place came to msg555, closely followed by cgy4ever. It is worth mentioning that, cgy4ever solved Problem D in the last few seconds which is quite impressive.
Draw the grid graph as the problem said.
Just a few basics of your programming language. It's easy.
Ask the minimum unit shift you need to sort a array.
Just a few basics of your programming language. It's not hard.
Calculate the expected maximum number after tossing a m faces dice n times.
Take m = 6, n = 2 as a instance.
6 6 6 6 6 6
5 5 5 5 5 6
4 4 4 4 5 6
3 3 3 4 5 6
2 2 3 4 5 6
1 2 3 4 5 6
Enumerate the maximum number, the distribution will be a n-dimensional super-cube with m-length-side. Each layer will be a large cube minus a smaller cube. So we have:
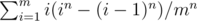
Calculate in may cause overflow, we could move the divisor into the sum and calculate (i / m)n instead.
You are given sequence ai, find a pairwise coprime sequence bi which minimizes 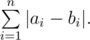
Since {1, 1 ..., 1} is a pairwise coprime sequence, the maximum element of bi can never greater then 2mx - 1. Here mx is the maximum elements in ai. So what we need consider is the first a few prime factors. It is not hard to use bitmask-dp to solve this:
for (int i = 1 ; i <= n ; i ++) {
for (int k = 1 ; k < 60 ; k ++) {
int x = (~fact[k]) & ((1 << 17) - 1);
for (int s = x ; ; s = (s - 1) & x) {
if (dp[i - 1][s] + abs(a[i] - k) < dp[i][s | fact[k]]){
dp[i][s | fact[k]] = dp[i-1][s] + abs(a[i]-k);
}
if (s == 0) break;
}
}
}
Here dp[i][s]: means the first i items of the sequence, and the prime factor have already existed. And fact[k]: means the prime factor set of number k.
Given a undirected graph with n nodes and the parity of the number of times that each place is visited. Construct a consistent path.
There is no solution if there is more than 1 connected component which have odd node (because we can't move between two component), otherwise it is always solvable.
This fact is not obvious, let's focus on one component. You can select any node to start, denoted it as r (root). Start from r, you can go to any other odd node then back. Each time you can eliminate one odd node. After that, if r itself is odd, you can simply delete the first or last element in your path (it must be r).
The only spot of the above method is the size of the path can been large as O(n2). We need a more local observation. Let's check the following dfs() function:
void dfs(int u = r, int p = -1){
vis[u] = true;
add_to_path(u);
for_each(v in adj[u]) if (!vis[v]){
dfs(v, u);
add_to_path(u);
}
if (odd[u] && p != -1){
add_to_path(p);
add_to_path(u);
}
}
This dfs() maintain the following loop invariant: before we leave a node u, we clear all odd node in the sub-tree rooted at u as well as u itself.
The only u can break the invariant is the root itself. So after dfs(), we use O(1) time to check weather root is still a odd node, if yes, delete the first or last element of the path (it must be r).
After that, all the node will been clear, each node can involve at most 4 items in the path. So the size of the path will less than or equal to 4n. Thus the overall complexity is O(n + m).
Given you a vector e and a transformation matrix A. Caculate eAt under modulo p.
Let's consider the e = [1 1 ... 1]. After a period, it will be ke where k is a const. So we know that [1 1, ..., 1] is an eigenvector and k is the corresponding an eigenvalue.
The linear transformation has 2m eigenvectors.
The i(0 ≤ i < 2m)-th
eigenvector is [(-1)^f(0, i) (-1)^f(1, i) ... (-1)^f(2^m-1, i)], where f(x, y) means that the number of ones in the binary notation of x and y.
We notice that the eigenvalue is only related to the number of ones in i, and it is not hard to calc one eigenvalue in O(m) time. To decompose the initial vector to the eigenvectors, we need Fast Walsh–Hadamard transform.
Also check SRM 518 1000 for how to use FWT. http://apps.topcoder.com/wiki/display/tc/SRM+518
In the last step, we need divide n. We can mod (p * n) in the precedure and divide n directly.
n ponies (from 1 to n) in a line, each pony has:
Also, you have m operations called Absorb Mana t l r. For each operations, at time t, count how many mana from l to r. After that, reset each pony's mana to 0.
The income of a operation, is only relevant with the previous operation. In other words, what we focus on is the difference time between adjacent operations.
Let us assume si = 0 and ri = 1 at the beginning to avoid disrupting when we try to find the main direction of the algorithm. Also it will be much easier if the problem only ask the sum of all query. One of the accepted method is following:
Firstly, for each operation (t, l, r), we split it into a insert event on l, and a delete event r + 1. Secondly, we use scanning from left to right to accumulate the contributions of each pony.
In order to do that, you need a balanced tree to maintenance the difference time between adjacent operations, and a second balanced tree to maintenance some kind of prefixes sum according to those "difference".
The first balanced tree could been implemented by STL::SET. For each operation, you need only constant insert and delete operations on those balanced tree, thus the overall complexity is O(nlogn).
Instead of scanning, now we use a balanced tree to maintenance the intervals which have same previous operation time and use a functional interval tree to maintenance those ponies. For each operation, we use binary search on the first balanced tree, and query on the second balanced tree. Thus the overall complexity is O(nlog2n).
In DIV 1, there are 4 interesting problems together with a normal one. We think it is reasonable because we can't have a round fullly with intelligence. Problem A, C have weak pretests while others intended to be strong. About more then 200 participants solve A in the early 45mins, then a few of them start from C while most of the other start from B.
Problem B is a rather standard problem, but if you're unfamiliar with the algorithm, it can be very hard. Problem C is a more intersting problem. As the name implies, there was a similar version in the previous round before, but this time it has a brand new constrains.(So here we have a psychology experiment: could different constrains make people thinking in a slightly different way?ww)
The standard solution of problem C is O((b - a) + nlogn). The first expected correct solution was written by zeliboba. http://codeforces.com/contest/346/submission/4512654
After that, some people start to solve problem D. Problem D looks like a hard dp problem on a graph at the first glance, the key point is how to avoid the circle in the transfer equation. It turn out to be elegant after you could found a right order of the evaluation. Problem E is challenging which you need find a way to transform the original question into a smaller scale, and cut off many many corner cases ... And in the very end, you find a way like binary search to get O(logn) as the time complexity. No one manage to solve problem E during the contest, maybe Petr is the man who closest to it.
The winner comes to cgy4ever, because he found the draw-black in his previous C submission during the very beginning even when there is nobody hack him! He resubmit it decisively and get back when finished problem D. After that, he use the same trick which made him failed before to hack others and got a handsomely rewards. The second place went to rng_58, because of the combination of decent speed in A, B, C, D.
Problem B belongs to me, problem C belongs to CMHJT and others belong to UESTC_Nocturne. The illustrator of problem C is Chairman Miao(貓主席).
Alice and Bob play a game, the rules are as follows: First, they will get a set of n distinct numbers. And then they take turns to do the following operations. During each operation, either Alice or Bob can choose two different numbers x and y from the set, as long as |x - y| is not in the set, then they add it to the set. The person who can not choose two numbers successfully will lose the game. The question is who will finally win the game if both of them do operations optimally. Remember that Alice always goes first.
First, no matter what happend, the number set we get at the very endding will be same all the time. Let's say d = gcd{xi}. Then the set in the endding will be some things like {d, 2d, 3d, ... max{xi}}. So there is always max{xi} / d — n rounds. And what we should do rest is to check the parity of this value.
You have been given two strings s1, s2 and virus, and you have to find the longest common subsequence of s1 and s2 without virus as a substring.
This is a rather classical problem, let's say if there is no virus, then it is the classical **LCS ** problem. You can solve this by a O(n2) dynamic programing.
When consider about the virus, we should add 1 more dimension on the state to trace the growth of the virus. It can be done by wheather Aho-Corasick automation, or KMP when there is only one virus in this case. The overall time complexity is O(n3).
You have a number b, and want to minus it to a, what you can do in each step is weather subtract 1 or b mod xi from b. And we ask what is the minimum number of steps you need.
I bet there is a few people know the greedy method even if he/she have solved the early version before.
Codeforces #153 Div 1. Problem C. Number Transformation
Let dp[k] denotes the minimum number of steps to transform b+k to b. In each step, you could only choose i which makes b+k-(b+k) mod x[i] minimal to calc dp[k]. It works bacause dp[0..k-1] is a monotone increasing function. Proof: - Say dp[k]=dp[k-t]+1.If t==1, then dp[0..k] is monotone increasing obviously.Otherwise dp[k-1]<=dp[k-t]+1=dp[k] (there must exist a x[i] makes b+k-1 also transform to b+k-t,and it is not necessarily the optimal decision of dp[k-1]). So dp[k] is a monotone increasing function, we can greedily calc dp[a-b].
In the first glance, it looks like something which will run in square complexity. But actually is linear. That is because, we could cut exactly max{xi} in each 2 step. It can be proof by induction.
So the remians work is to delete those same xi, and watch out some situation could cause degeneration. Many of us failed in this last step and got TLE
Let's dp from t to s.
dp[u] = min(min(dp[v]) + 1 , max(dp[v])) | u->v
Here dp[u] means, the minimum number of orders mzry1992 needs to send in the worst case. The left-hand-side is sending order while the right-hand side is not. At the beginning, we have dp[t] = 1, and dp[s] will be the answer.
We can see there is circular dependence in this equation, in this situation, one standard method is using Bellman-Ford algorithm to evaluate the dp function.
But it is not appropriate for this problem.
(In fact, we add a part of targeted datas in pretest, these datas are enough to block most of our Bellman-Ford algorithm, although there is still a few participator can get accepted by Bellman-Ford algorithm during the contest.
Check rares.buhai's solution
dp[u] = min(min(dp[v]) + 1 , max(dp[v])) | u->v
The expected solution is evaluating the dp function as the increased value of dp[u] itself. Further analysis shows, wheather we decided sending order or not in u can be judged as the out-degree of u.
while (!Q.empty()) {
u = Q.front(), Q.pop_front()
for each edge from v to u
--out_degree[v]
if (out_degree[v] == 0) {
relax dp[v] by dp[u]
if success, add v to the front of Q
}
else{
relax dp[v] by dp[u] + 1
if success, add v to the back of Q
}
}
Check Ra16bit's solution to see how it works.
You have been give a, p, n, h (gcd(a, p) = 1), For each ai mod p, (i∈[1, n]), check weather the maximum distance in neighborhood after sorting is <= h.
Take a =5, p =23 for example ... Divided the numbers in group.
0 5 10 15 20
2 7 12 17 22
4 9 14 19
1 6 11 16 21
3 8 13 18
We start a new group when the number > P
We found the difference between the elements of the first group is 5, The subsequent is filling some gap between the them ...
After some observation we could found that we should only consider into one gap ...(e.g. [0, 5] or [15, 20] or [20, 25] ... )
0 5 10 15 20
2 7 12 17 22
4 9 14 19
1 6 11 16
That says .. a =5, p =23 is roughly equal to some things in small scale?
So let's check it in detail. Lemma 1. In any case, the gap after 20 won't better than any gap before it.
0 5 10 15 20
2 7 12 17 22
4 9 14 19
1 6 11 16
For example, in this case, the gap after 20 is: 20, 22 And it has 16 in [15, 17] but no 21.
Is there any chance that [20, 23] is better than [15, 20]?
No, that is because, when there is no 21, then (19+5)%23 = 1, go to next floor. and there is no corresponding gap after 20 ([22, 24]) for this gap ([17, 19])
So we only need to consider [15, 20] ... and we found [15, 20] is roughly equal to [0, 5]
e.g. : 15 20 17 19 16 18
equal: 0 5 2 4 1 3
we say 'roughly' because we havn't check some boundary case like there is 3 but on 18 ...
0 5 10 15 20
2 7 12 17 22
4 9 14 19
1 6 11 16 21
3 8 13
If it happend, we should remove the number 3. .. If we can remove the element 5, then we can from a=5, p=23 to a'=2, p'=5 ...(n' = an/p, a' = a-p%a, if there is 3 but no 18, n'=n'-1)
The rest things is to discuss wheather 5 is necessary or not.
Let's we have:
0 2 4
1 3
If the 2*n'<5, then there is only one floor, the answer is max(2, 5-2*n'). If there is more than one floor, we could conclude that 5 is useless.
Proof: Elemets in 1st floor is:
0 a 2a 3a ...
Let's say the maximum elements in 1st floor is x, then the minimum element in the 2nd floor is b0 = x+a-p, because b0 — a = x-p, so the difference between b0 and a is equal to the difference between x and p. That is, we can consider [b0, a] rather than [x, p], when there is a element insert in [b0, a], there must be some element insert in [x, p] in the same position.
So we have have succeeded to transform our original problem into a small one. Of couse, this problem havn't been solved, we haven't consider the time complexity. Says a' = a — p%a, when p = a+1, then a' = a-1, but we have a equal to 10^9, it won't work.
But, let's we have A1, A2, ... An ... and we subtract d from all of them, the answer won't be changed. So we can use p%a substitute for a-p%a, this is equivalent to we subtract %p% from all of them ...
So we set a' = min(a-p%a, p%a), so a'<=a/2, therefore, the final time complexity is O(logn).
You can check Petr 's solution for detail.
As usual, the team of Peking University consists of the winners of National Olympiad in Informatics in the previous year. Among of them, Chao Li(chnlich) keep ahead in the rat race and became one of the national team member in IOI 2012 at Sirmione, Italy.
Because of the long-term experience in algorithm contest during senior high school, they have been quite familiar with each other, every team member has their division of labor during the contest. Although living in Peking University is quite busy because of the first year foundation courses, they still spare some time to do regular training as much as possible.
Unfortunately, one of their men missed the Battle of Giants in Yekaterinburg because of visa issue last month, we still have no idea with their actual strength.
 Photo by me
Photo by me
Personal achievements:
They won 3rd place in Changchun(长春) and 2nd place in Tianjing(天津) in their first year regional journey, and 3rd place in Changsha(长沙) just a few month ago. You should not underestimate their potential to win a gold in the coming ACM/ICPC world final.
。。。(; Д ;) 。
Math, implementation
This problem can be solve by brute-force, but it come up with a nicer solution if we involve some math.
Check the following article if you are interested.
http://en.wikipedia.org/wiki/Pythagorean_triple#Generating_a_triple
Math, implementation
This problem can be solve by brute-force, but it come up with a nicer solution if we involve some math.
Check kabar's code if you are interested.
http://codeforces.com/contest/304/submission/3715756
Math, Constructive algorithms, Congruent
S = \Sum_{i=0}^{n-1} i = n/2 (mod n) but 2*S = 0 (mod n)
See also at:
http://codeforces.com/blog/entry/7499#comment-133446
Math, Geometry
Give you n, m, x, y, a, b.
Find a maximum sub-rectangle within (0, 0) — (n, m), so that it contains the given point(x, y) and its length-width radio is exactly (a, b). If there are multiple solutions, find the rectangle which is closest to (x, y). If there are still multiple solutions, find the lexicographically minimum one.
Split the problem into x-axis and y-axis. Then you can solve the sub tasks in O(1).
d = gcd(a,b)
a /= d
b /= d
t = min(n/a, m/b)
a *= t
b *= t
Be careful, when the length is outside the original rectangle.
Math, Graph theory, Brute-force, Congruent
It is hard to solve this problem at once, so at first, let us consider on k = 0, this easier case can be solved by enumerate on the ans. Let us define a bool array diff[], which diff[x] is weather there are two number, ai, aj, such that abs(ai - aj) = x.
So ans is legal <=> diff[ans], diff[2*ans] … are false.
The time-complexity O(n2 + mlogm). Here m is the maximum ai.
Consider on k > 0, we need to know how many pairs which has difference x. Store them invector<pair <int, int> > diff[x];
Then use a dsu to maintain the how many a_i are congruent when enumerate on the ans.
Math, Number theory
(Coming Soon...)
http://codeforces.com/blog/entry/7499#comment-133342
Math, Probability
(Coming After D...)
Three drops in a line, back to yellow so quickly ...
Anyway, Codeforces Round #183 will be take place on Sunday, May 12th at 17:00 MSK(21:00 CST). Right after the Google Code Jam Round 1C.
Setters are:
Testers are YuukaKazami, havaliza, Velicue && me.
We gratefully acknowledge Gerald Agapov(Gerald) for his help in giving advise about the problems, Delinur for her help in translating the problems to Russian, and MikeMirzayanov, who has designed such a powerful platform.
We strongly recommend you to take a glance over all five problems, there must be one suitable to your taste.
Oh one more thing, this time, scoring will be dynamic, but problems are sorted by increasing order of their difficulty as usual.
Good Luck!
In DIV 1, there are 3 normal tasks accompanied with 2 challenge tasks. About 40 competitors solve first three tasks during the contest and I believe there will be more if we extended the duration a little bit.
Task D is a standard data-structure problem hidden behind a classical maximum cost flow model. This kind of problem are usually trick-less, but hard to implement especially under the pressure. Because of this, it becomes tonight's draw-breaker.
Task E is a extended version on a classical DP && Math problem. There are many solutions to the original problem, one is giving a global view under the state transition, and using a data structure to handle it carefully. However, this one is even more harder, few people have ever tried it except Jacob. (Although is wrong.)
As a seasoned competitor, Petr took the C-B-A order which proved to be the best choice through out the night. And after quickly solved C and B, he has sunk into problem A, it takes him about 45 minutes to cut-the-knot and got 2 Successful Hacking Attempt as a reward.
On the other hand, peter50216 gave his response to Problem A straightly! It only took him about 15 minutes to write a code which is full of trigonometric function and if-else. And on top of this is another 15 minutes to solve the successors. After that, he gave 2 Successful Hacking Attempt on A and 1 Successful Hacking Attempt on B as the end.
While we were marvelling at peter50216 for his solid skill in geometry, al13n gave the first attempt to problem D among the game. Unfortunately his solution get TLE on the pretests.
This is a O(mk^2logn) algorithm, and we think it is hard to optimize it to pass the pretests even for our setter. And abandoned the O(mk^2logn) solution and totally reconstructed the O(mklogn) from the sketch now became more difficult and audacious.
While we were praying to al13n, Jacob gave the first solution and the only solution for Problem E among the whole game! It cost all of his time and led him no time to solve others. It sounds like a miracle ..
We were all sooooooo excited and opened his code and look carefully, but, actually I myself got quite confused by his solution, and didn't know why it can work at all.
While all we setter and tester were checking the solution carefully. UESTC_Nocturne (XHXJ) gave the first correct solution among the game for problem D. It is a huge code more than 12kb, and perform as same as our std solution. Although he haven't solve A && B, this break-through has already establish his winner position.
After the contest, I interview her to "how can you solve this problem so quick", and replied as “I have solved the simplified problem, and have thought about this method before.”
At the same time, we found that Jacob's solution was wrong, we generated a few maximal random data, and it return WA about one-quarter of them. After some discussion we decided to add one of them into the tests.
In both problem D and E, our pretests intended to be as strong as possible. How I wish to let Jacob know about his solution is wrong so he can quickly get out of the impasses and get Accepted in the end... .
al13n also pass from the pretests after UESTC_Nocturne, we are relieved to hear about it at first, but found it is a O(mk^2logn) solution with a wrong optimization soon, this solution will definitely fail in system test, but he may didn't aware of it at the time.
There are other three correct solutions for Problem D near the end of the game, among them FattyPenguin's solution is the fastest one, and he make it in ten minutes ago before the contest end and liouzhou_101's solution actually is a O(mk^2logn) one but with some dramatic optimizations. It is hard to block this kind of solution or it could cause some trouble for our Java Users.
http://assets.codeforces.com/statements/280-281/Tutorial.pdf
Backstage: The screencast of my screen during the contest, you can see what happened behind the scene if you are interested, just have fun ~.
Daniel Sleator (A professor at CMU who invented many data structures such as splay trees, link-cut trees, skew heap and discovered amortized analysis, see Wikipedia ...)participated in Div 2 and get promotion to Div 1 after the contest. And he checked our Div 1. E and write a miraculous DP solution1 2 in Ocaml which based on a conclusion.
Hello there!
Codeforces Round #172 will take place on Sunday, March 10th at 19:30 MSK(23:30 CST).
This is my second time participating in prepration a Codeforces Round. Last time assist with YuukaKazami is an unforgettable experience. This time, the hardest problems were created by Jiatai Huang(CMHJT) and others by me and Yuping Luo(roosephu).
Testers are sevenkplus, YuukaKazami, pashka and Seter.
We gratefully acknowledge Gerald Agapov(Gerald) for his help in giving advise about the problems, Delinur for her help in translating the problems to Russian, and MikeMirzayanov, who has designed such a powerful platform.
Here let me express my personal thanks to the Codeforces community, which has given me so much gleamy idea in the past two years.
Believe it or not, Codeforces has kept her feet in China's ACM community since last year. AFAIK, some of the hardest problems have been used as this year's Winter Camp homework for our National Olympiad in Informatics.
Also thanks to watashi, ftiasch and xlk. Discussing problem with all of you, has inspired me a lot.
500 — 1000 — 1500 — 2000 — 2500.
We are going to use a standard score distribution in both divisions.
The problemset is a little bit easier than last time, but we still believe, getting all of those five problems accepeted will be a challenging mission even for an seasoned International Grandmaster. The problemset has been marriaged with variety flavor. Take a glance over all five problems before going to coding might be a wise strategy.
UPD:
The contest is over, congratulations to the winners:
Div1:
Div2:
Congratulation to tclsm2012, who also solve the problem D!
We feel so pity to al13n, your last optimization for problem D is wrong. Problem D has a O(mklogn) algorithm. And we are extremely sorry to Jacob, your solution for problem E can pass most of the random tests but actually is wrong.
Jacob... can you explain your solution for us :)
We need collect some feedback about this round .. So the editorial will appear after a period of time.
UPD:
I used to hate those guys who set problems, but didn't write editorial at all! But when things turn to myself, I found it is really difficult to cover all cases. Anyway, it has been done.
Here's me solving on #164:
Hi, I am so weak at Computational Geometry in some points, And I have heard that the best Geometry Template in the world is the University of Tokyo && Taiwan National University, I wonder where I can found them ... . Are they accessible online in signle a PDF document?
Thank you ..lol ...
http://www.spoj.pl/problems/NOTOKNOT/
Wiki:
http://en.wikipedia.org/wiki/Unknotting_problem
http://en.wikipedia.org/wiki/Regina_(program)
Discuss:
I have try to solve this problem for more than half a month. Read all the book I can found in the local Library and I can't even find a direction !...
Is there a polynomial complexity algorithm or only have a physical simulation algorithm ? ... I was particularly interested in the matter, any one can guide me a correct direction ~~
Thanks a lot!..
Such as the title .. .
I had a sort of feeling that this resource will be useful .. but is tooooo difficult for me to read those Cyril characters .. .Any one want to translate this web-page into English? or only a piece of section about the graph theory.
.. . Thanks a lot ! .. lol ..
(This post has originally been post at here ..(only with more pictures) .
This is the Chinese Mannual for Egor's CHelper 3.0 along with IntelliJ IDEA, see more infomation at here.
——————————————————————————————————————————
这里是 CHelper 中文配置手册,基本翻译自 Google Project 那里,顺便修正了少许版本更新后没有修改的地方。。。
首先 CHelper 是一个 IntelliJ IDEA 的一个插件,IntelliJ IDEA 是一个主要用于 Java 的 IDE,(C/C++ 似乎暂时还没有找到类似的东西。)
如果还没有安装 IntelliJ IDEA,那么先安装 IntelliJ IDEA .. .(这里以社区版为例。)
IntelliJ IDEA 打开后的页面。
File -> Settings ...
左栏 IDE Settings,选择 Plugins .. . (注意这里如果一直 Loading 请戳 HTTP Proxy (nimendongde
右上角搜索栏输入 CHelper ... 双击下载安装。
安装后会提示重启 (Restart),重启后 Create Project,选择第一个 from scratch.
注意区分 Project 和 Model,一般来说一个 Project 只有一个 Model。
然后建一个 Source Directory。(就叫 Source 好了。。。
如果是第一次配置,这里会自动提示您指定 SDK 的路径。
这样。。。
打开后是这样。。接下来要把 CHelper 放到工具栏上。
右击工具栏 -> Customize Menus and Toolbars
Main Toolbar 展开suru
可以再最后先加一个 Separator,然后点 Add After,弹出对话框
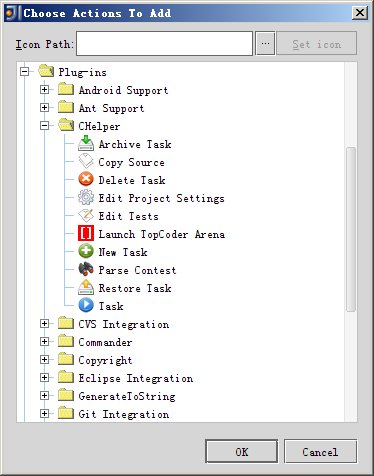
.14. Plug-ins -> CHelper ... (这里可以自由选择项目和根据自己的需要调整顺序,总之先全部加上。。
.15. 回到目录,Source 下新建一个 Package 。。(名字自己敲。。这里就用 Current 表示当前工作目录好了。。。
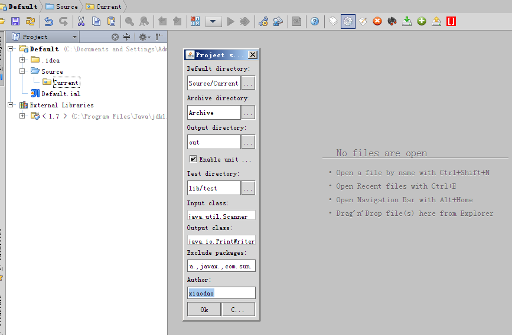
.16. 在刚才的添加的那组工具栏里找 Edit Project Settings ... (参考图中设定。。
.17. 设定完以后 CHelper 会出现在目录里,现在开始这个工程已经受 CHelper 支配了。。
.18. 现在来写几个题。。(以最近的一次 Codeforces , #142 DIV 1 为例。。
..19. 完成啦。。
。。CHelper 主要实现的功能:
.. . 以上







{kind=link}
{kind=link}
{kind=link}
{kind=link}