



Hi everybody!
These days Moscow is conducting the 3rd International Olympiad of Metropolises that is an international competition for high school students from biggest cities and capitals all around the world. One of the disciplines of the competition is informatics. Rounds of the competition were prepared by the jury members invited from St. Petersburg, Minsk, Belgrade and Moscow olympiad scientific committee which you may know by Moscow team Olympiad, Open Olympiad in Informatics and Moscow Olympiad for young students (rounds 327, 342, 345, 376, 401, 433, 441, 466, 469).
Scientific Committee of the olympiad consists of: darnley, Endagorion, Jelena Hadži-Purić, Elena Andreeva, Zlobober, GlebsHP. The problems were developed by kraskevich, ch_egor, cdkrot, Schemtschik, GoToCoding, malcolm, akvasha, darnley, wrg0ababd, achulkov2, vintage_Vlad_Makeev under the guidance of GlebsHP and Zlobober.
Problems were adapted for codeforces by KAN and cdkrot, also thanks for MikeMirzayanov for systems codeforces and polygon, which was used to prepare problems of this olympiad. Also, thanks LHiC and V--o_o--V for testing!
Good luck and high ratings for everybody!
Round will happen on Sep/05/2018 19:35 (Moscow time) and will last for two hours. There will be 5 problems for each division.
P.S. We kindly ask everybody who knows problems of an onsite event not to participate in a round and not to discuss them in public, as this may be a subject for disqualification.
Upd: Editorial was published here!
Aaaand congratulations to winners!
Div1:
Div2:






Sad :( Another midnight contest for Chinese. My sleep schedule is totally messed up.
Me too in South Korea. Start time of this contest was AM 01:35.
It would be great if the contests open up an hour or two earlier sometimes...
According to this currently the 3rd IOM is running.
fixed it =)
Really, the olympiad of metropolises is at the same time as the IOI?
When will be post about IOI)))?
There is a educational round right before this contest according to the calender, but I can't see it in the contest list... is it canceled ?
Asking the same question. the Educational round is still on calendar.
It is obviously canceled
Is it postponed by few days or was it an error in the Contests list?
I think it is postponed
two rounds in one day? That's crazy!
there is only one round. edu round is canceled
Why downvotes for providing right information?
Scoring?
top 10 classified secrets.
Why I always receive You have submitted exactly the same code before but I haven't submit any code?
No idea for now. You can try to submit source file instead of source code and vice versa. Sorry about it, I'm looking in the code to fix it right now.
what a poor pretests :(
Do you mean pretests for A, huh?
Well, I agree. However, this is a hard way to learn to avoid stupid mistakes. Going back to Green, I guess...
Well played anyway! I enjoyed this round so much! Thank you, everyone.
When you check in 50 minutes late and notice that 1/3 of all participants have 0 points
Me after reading Div-2 C
Sorry :(
The onsite contestants struggled with this problem as well and we have made really big changes to the statement in hope that it will become much easier to read.
But looks like it didn't help. Maybe just the problem is too difficult for this position.
The problem is, its more difficult to understand than to solve. Even after scratching my head for 10 minutes and asking twice in announcement I cannot get why second sample was invalid and how X in second example was forced to be (2, 2) if it were to be valid.
Anyways, keep doing your best! :)
I really don't want to be rude, I really enjoy the many contests that Codeforces offers, but I've struggled with some tasks because of weird wording. I think the coordinators should ask for help with the wording. It looks like you have some problems with English ("didn't helped") or maybe your comment was in Russian and then translated to English. I'm not a good English speaker either, but I think a lot of people would like clearer statements in the future. Anyway, just a minor observation. :)
Well, when I write statements I try to be more accurate with grammar and reread again text later and even use some helping programs, I hope my statements are not that bad :).
But in this particular round most of the statements were almost untouched by me, since some part of jury have already worked on the statements for the onsite round.
Thanks for the reply. I understand how hard it could be to write a task. Keep up the good work!
Thank you :)
Can we call this a standard contest?
What an unbalanced contest
This round is so ...ing ...(*CENSORED*)
What do you mean to say by predefined plan in question D?
It means that you can use randomized solution)
Predefined means that the sequence of xi (the location of the train) is fixed for the test, also |xi - xi + 1| ≤ k.
And in future it is much better to ask a question through the contest interface.
Yeah, in practice this means that the solution can be randomized :)
Hackforces again...
I do not C what Timetable is trying to say.
It took me a while to understand the problem, passed the pretest when it was only 5 min left. Here is my explanation:
Suppose that you have a sorted timetable A = [a1, a2, ..., an] of when the buses depart and a sorted timetable of when they arrive B = [b1, b2, ..., bn]. One interesting question is when will the buss departing at ai arrive? There might be multiple possible arrival times, so let bXi be the last possible time.
In the actual problem you are given A and X, and your task is to create an arrival timetable B that matches the given X.
Thanks for the explanation. I think I understood most of the problem, but forgot to realize that X was a constraint and not something you could change. :((
wtf with div 2 ?? very difficult to understand and more difficult to solve it :)
I think this round should be unrated...
One of the poorest pretests one can ever see.
Another AnnouncementHackForces Round :(
div2D isn`t too hard, just a little bit probability
div 2 rank 1500/4400, rating 1450, will my rating be increased or decreased ? :v
Use the extension called CF-Predictor
Install it to your browser-> Rating Predctor
According to my CF Predictor, you're projected +4 currently.
thank you :D
more than 1 hour and half trying to understand C , LOL :D
why c so hard to understand
I understood c right away, but didn't see that b's should be all different. Then there are cases you have to worry about, much harder problem then D. I passed presets in the end though.
Question D just reminded of Heisenberg Uncertainty Principle. I can only zero in the location of train to a range of 2*k . How would one perfectly predict the next position of the train? Can somebody enlighten me with the solution.
4500 query is enough to check your luck s.t you can win on 1/2*k probability
Was this the intended solution?
probablistic solution seems intended solution
I used binary-search. If r — l + 1 < 4k (because it made next query's range larger than current query), i queried a pair of random x in range [l, r]. I also subtracted k from l and added k to r in the end of each query. But i got WA. Do you know where did i wrong?
I can't look at your code yet but there are several edge cases to consider:
What if k = 0? Then r — l + 1 < 4k will never be true.
If you subtract k from l and add k to r you need to make sure than r never exceeds N and l never goes below 1 or you might give incorrect queries.
After guessing a bunch r — l grows, if r — l gets big enough you should consider binary searching again so that the range you guess in is very small again.
Yeah, i got it. I might fail when k == 0. Everything else seem fine.
Lot of people used random numbers.
You can use random.
I haven't solved it but I thnk the solution is probabilistic. If you are put enough times in a situation where you have to guess a number between 0 and 2 * k you will eventually guess it.
You can't predict it, but the plan is predefined so you can keep guessing until you find the position.
maybe it's based on randomness. if you randomly predict for 1000s of times you have a good chance of getting it correct after reducing possible range to min of course.
I tried choosing the position randomly after that, and if incorrect, moving the left range to left — k and right range to right + k, and repeating the process, but it got tl. I dont think it is possible to prefectly predict the position of the train, because, for example, if n = 3, k = 2, then each turn the train can be at any possible spot.
Exactly, more accurately since k=10 the probability reduces to 1/(2*k)= 5%. If this is the actual solution I would be disappointed.
The math behind it is, if there is 5% chance of success, and you ask X queries, how many will be successful? For 1000 queries, you get E(X) = 50 where E(X) = expected number of correct guesses- we only need 1 correct guess. So if we can keep the range small, constantly querying a random number in that range can give us the answer quite good. We can prove that huge deviation from expected value is not very probable.
If you got TLE either you're solution is unnecessarily slow or you forgot to flush the buffer or exit on a wrong answer.
Can you please explain what i am doing wrong? i really dont understand. 42528924
I'm not sure why you're TLEing but in your binary search when you get "Yes" your setting right = mid + k but you also need to set left = left — k and similarly for your "No" branch.
thank you!
In 1040D - Subway Pursuit, Is it possible to use randomised index when range falls below a certain limit (say 2k)? And doing binary search otherwise?
I used this approach and failed pretests: 42525760
I passed pretests with something similar. Binary search normally so that you know that the car is in [a, b]. Then at every step, set [a, b] <- [a - k, b + k], and then check if the car is in [a, (a + b) / 2] like in normal binary step. Continue until the length of the interval is something like 40, then pick a random one and ask it. You get to ask over 1000 times so there's almost no chance you fail.
I had exact similar idea, but kept failing pretest 6. My idea was that, First Binary Search for interval until we get [l, r] such that r - l < = 21 (2*10+1, 10 as 10 is max K). Now ask a random query in [l, r]. If it fails, then the train can be in [l - k, r + k], so narrow down again. Anything wrong here?
Link: https://codeforces.com/contest/1040/submission/42517845
You should probably add k to both ends of the interval, not just the side where the car happens to be. Also, if you do that, 21 is too small.
Damnnnn!! I think I know the bug now. Yes, should have added k on both sides of interval :(
Indeed, I first queried for [a, b] and then based on response, I changed both ends to [a - k, (a + b) / 2 + k] or [(a + b) / 2 - k, b + k]. But this approach failed for me on pretest 3.
If you don't consider k shifts in your binary search, how can you be sure that the car is in [a, (a+b)/2] ? I was shifting in the binary search too and got WA. I see many people cleared pretests with this way.
For instance, trains is at 5 and you start binary search from [1, 10], so guessed [1, 5] and got Yes. Then train moved right and you proceed to search in [1,5].
You start binary search from [1, 10]. You guess [1, 5] and get yes. In the next step, you decrement the starting index by k, and increment the ending index by k, so you get [1, 5+k]. Then you binary search more.
Here's my code: 42507358
Okay I interpreted the code wrongly. I implemented the same thing, but with narrower gap and once I found narrow gap, I was guessing several times considering shifts on borders. Unnecessary cleverness :(
Same idea, and also used 2*k for the gap. It seems our gap is wrong. :(
Edit: Yup, using 50 for the gap instead -> ACCEPTED
At last minute it seems i figure out solution for D: Bruteforce for k small, and binary search for k large.
Yeah, this will do. It is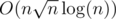 solution.
solution.
It's actually O(n*sqrt(n * logn)) if you bruteforce until sqrt(n * logn). Was the time tight? My solution is exactly this but doesn't pass...
It should pass rather comfortably, maybe the constant in your solution (I mean the "sqrt of n" constant) is not good enough?
Turns out that using DFS is TLE and BFS is AC :|
Div1 B and C are trivial, and Div1A is the hardest Div1A I have ever seen. Still no idea how to solve it ;_;
Contest with worse problem statements than the standard.
Me in the contest:
Failed D2A (ACed at 10 minutes, -1 | UPD: Will fail system test, well, screw myself :<).
Failed D2B (ACed at 30 minutes, -3).
Failed to understand a single bit of D1A.
24 times attempting to random D1B and failed all of them...
Hmm. One year later and I still got no luck with Informatics Olympiad of Metropolises.
My worst contest so far as well, was too hesitant to try out random even after seeing applications of it in comments section of neal's recent post! (Apart from 2B epic fails as well, +5)
hand-shake Well, we shared the same fate.
I did believe 1B needs randomization, thus confidently thought my solution would pass it for sure. Yet, what happened in the contest denied that idea.
What was your logic for 2B
I did it in two clean cases, finally, after multiple mistakes and brain fails.
1) 2*k+1>=n — cout 1 and n/2 2) Take the k+1th skewer to be turned over, and then turn over skewers with a difference 2*k+1. Then, check whether this gives a possible solution. If not, take the 1st skewer to be turned over and turn over skewers with a difference 2*k+1.
For a quick observation, the maximum number of flipped skewers when touching one arbitrary skewer will be 2k + 1.
Therefore, the minimum number of actions will be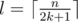 . The logic is, we choose positions such as all skewers will be touched once only.
. The logic is, we choose positions such as all skewers will be touched once only.
With that in mind, the number of non-existent skewers (The "skewer" that would be touched if there exists indices lower than 1 or higher than n). Obviously, non-existent skewers will only exist at the leftmost and/or rightmost position.
That value will be A = l * (2k + 1) - n.
The remaining will be case-handling:
If A ≤ k, we only need to fix the leftmost position so that it creates A "non-existent skewer(s)" (you can instead fix the rightmost position, suits yourself). The position for the leftmost should be A + 1.
Otherwise, fix the rightmost at n, then fix the leftmost at A - k + 1.
The other positions would be easily found henceforth, since the remaining skewers not being flipped yet is a subsequence with size guaranteed to be divisible by 2k + 1.
(Sorry for the long explanation, I'm quite bad in writing such though :P)
what was the hack in B?
I was hacking people by just replicating their rand() behavior and making my moves in such a way that I don't get caught.
Some participants had following interesting approach:
I wanted to ask you specifically (since you did 13 successful hacks): did you retype the code of each solution you hacked? Or how did you reproduce the exact behaviour of the victim-solution?
I was personally looking for those who generated random number from L to R with non-inclusive R (which means the solution will never guess 10**18). I found one (and only one) such solution and successfully hacked it with 4500 maximum (10**18) numbers.
You can see generator of test clicking "view test" on hacks page. You may notice he just used the same generator with different way of choosing random numbers (the same way as author of code hacked, if I understand correctly)
Basically, idea that you don't have to know what numbers person generates, you just want to be able to generate them the same way in your test generator
Thanks riadwaw. I analysed the code of I_love_Tanya_Romanova:
but I still don't quite get why it works: he takes rand()%10 but people take rand()%(R-L+1) and this should give different results in general.
He has n=k, so l and r are always same
Ahh...! Now it all makes sense! Very smart hack. And great challenge! Teaches you to be aware that other people might hack you. I was thinking during the round that "static" solutions can be hacked but I didn't think it could be done that easily. I submitted the problem in Python which I think generates different random numbers every new launch by default so I am fine. (Creates new .py file and checks) Yes it does.
I think bad condition for randomizing, there was a guy who do binsearch till r-l+1<=4k. But I think there could be test when r-l+1=4k+1 and it will comeback to this length again and again. But I couldn't found this
The majority of contestants using C++ still get deterministic pseudorandom sequences instead of unpredictable sequences. In various ways, some of which are system-dependent and thus surprising for the first time.
And such problems on Codeforces are few and far between, otherwise everyone would remember to make their randomness unpredictable to a hacker.
Edit: the easy test itself is:
The
xs are NOT the 4501 numbers the solution generates as pseudorandom (for example, transformrintor mod 10 + 1).Decent blog about random number generators in C++ and how to use them properly
Which problems were from the olympiad cdkrot?
Basically all, with some modifications.
D2B was hardened a bit considering the onside competition (there k was fixed and equal to 1, so you flip 3 items at the same time)
D1D was instead simplified (we have a solution in O(nlog2(n)), but it turns out, that to beat the O(nsqrt(n)log), it must be unbelievably efficiently written and still we got only 2 times faster than sqrtlog, so we decided to simplify the problem.
All others are taken unchanged, with 1 problem removed.
Whats test case 8 for Div2C?
Was DIV.2 D just about testing if you are the luckiest man on Earth???
seemingly yes but i didn't risked it
Just testing if you're wise enough not to use a fixed randseed
i used srand(time(NULL)) but i saw many hacks so didn't submit
In fact they were hacked only because they used a fixed randseed, not because they were too unlucky
What do you gain by not submitting?
well nothing just cursing myself now
Well, this contest basically checks history knowledge.
If you don't remember that legendary aimtech contest with interactive lowerbound, you may get caught in a fixed-randseed-trap.
If you have read Blogewoosh #3, you can instantly get AC on D.
And if you don't remember the most legendary aimtech contest ever, you still have a chance after reading a blog posted 3 days ago: Don't use rand(): a guide to random number generators in C++.
Well, Blogewoosh turned to be some pain in the ass :)
This problem is authored by GlebsHP and has a solution in O(nlog2) or even O(nlog). To be precise, these solutions differs a lot from the notes in Blogewoosh. However it turns out that implementation is really complicated and even more complicated if you want it to be faster that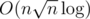 in practice, so we decided that lowering constraints for the codeforces edition is the best thing we can do.
in practice, so we decided that lowering constraints for the codeforces edition is the best thing we can do.
Also, it was expected for the problem to be revealed few months earlier, but we remembered that there was a Radewoosh contest in mipt with slightly similar problem a bit earlier, and it was decided to postpone the problem.
So few days ago we decided that it is a good time for this problem to strike back, and nobody have read the Blogewoosh until very late =/.
What is wrong with this solution for D?
http://codeforces.com/contest/1040/submission/42527188
By the way, I really liked problem D. Does anyone know any similar problems?
Div1 B told us to use
srand(time(NULL))or random number generator in C++ STL(for who uses C++), instead of a fixed seed.In fact I hacked a guy two times before he realized it :P
(And I'm curious why there isn't someone to hack me...Mine is
srand(19260817).)UPD: Thanks to krock21, mt19937 without a seed could be hacked too.
can u share how to hack a solution with fixed seed?
To hack a guy, copy his code (by your hands) first.
Then run his code while generating the input file.
When he is using binary search, just always lead him to the left side.(Just answering 1 is OK.)
When he is randomly guessing, answer 2 if he guesses 1, otherwise just answer 1.
this is not a valid hacking test case
valid test cases are predefined
i.e. tests must be written without knowing anything about the solution code
most of the hacks are invalid probably
Why wouldn't this be valid?
"When he is randomly guessing, answer 2 if he guesses 1, otherwise just answer 1."
such sequence is not predefined
And why should the hack be predefined? It can be generated using the solution.
from the problem statements :
" Note that AI is not aware that you are trying to catch the train, so it makes all moves according to its predefined plan. "
so, such test case is invalid to me.
however, it is accepted to the testing system and nearly impossible to prevent it from being accepted .
The "makes all moves according to its predefined plan." still holds, as the hack file is given before the submission is ran.
The fact that you can actually copy someone's submission by hand while hacking should be known by everyone using CF.
It depends on how you define "predefined".
After all, according the rules of Codeforces, that is just legal.
yeah you are right but I'm just saying
The validity rules you list are not the official contest rules.
This problem shows a subtle yet important difference between two solutions. One is pseudorandom but deterministic: it has the same output every time you feed it the same input. The other is pseudorandom and non-deterministic: its output depends on some other factors except input, like time of run. The former can, in principle, be hacked. The latter, unlikely.
Or you could just make your deterministic pseudorandom sequence too hard to reproduce in the contest (an example from my room: 42518451).
I think this should be forbidden. Making something harder to reimplement shouldn't give anyone an AC. The following rule is close to this issue, but it doesn't forbid that.
It is forbidden to obfuscate the solution code as well as create obstacles for its reading and understanding. That is, it is forbidden to use any special techniques aimed at making the code difficult to read and understand the principle of its work.
Hmm, for the sake of the argument, here goes.
The intent of the code is very clear: to make the seed hard to know. The long garbage string is intended to be garbage, it's isolated and doesn't prevent understanding of any other part of the solution. OCR'ing the string is forbidden by the rules. So I'd rather applaud Wild_Hamster's cleverness, not forbid the approach.
It may be against the spirit of the rules, but currently I don't see how.
Just to make things clear: I think that the quoted rule does allow this method.
Why does "the intent of the code being clear" matter? If I write
#define while ifat the beginning, and usewhileinstead ofif, the intent would be clear too: to make it harder to read. And it would be forbidden.No no, I meant the intent of what the code does when it runs, not the intent of what the code does to the reader when it's read.
I don't see how it matches the description "to make the seed hard to know", but I understand your point.
Ouch, my argument is indeed messed up. Sorry!
Why copy by hands? Is image text processing considered cheating?
Yes it is. Reading the rules can be too hard for people nowadays, so here's how to know: otherwise, why would Codeforces developers take effort to make the code un-copyable when hacking in regular rounds? If there was no such rule, it would be a win-win in the amount of effort if the text was copyable.
IIRC long time ago it was just a plain copyable text.
The amount of effort it would take to create a script which reads the code from an image is not particularly big. And there's no clear way to tell whether a person has cheated.
Why bother with the rule in this case at all? It might only give an advantage to those who prepared a handy script.
However, I believe that the community here is mostly honest.
Currently, the programs are not copyable in regular rounds, but copyable in educational and div3 rounds for after-the-contest hacks. The rules are set accordingly.
And yeah, the rule is hard to enforce. Although with some investigating help from the community, stories such as this are possible (TopCoder forums link going back to 2005).
What I did for pretty much all hacks:
And just retype SUPER_AWESOME_RANDOM implementation used in particular submission.
This kind of test structure usually requires very little modification when going from one bad solution to the next one, so you don't need to retype everything.
Yeah, yours is just much simplier. Thank you so much for sharing your idea.
Nice idea!
How will you type SUPER_AWESOME_RANDOM() if someone codes in java?
mt19937 without seed doesn't work
mt19937 should be seeded with time(nullptr) to avoid hacks:
time(null) is actually far from perfect because it can be predicted with a good precision during the hack
So there is no correct solution:(
You can get something that changes faster e.g rdtsc or high_resolution_clock. They are more or less impossible to hack
idk then, maybe you can slightly change it with << or % operations, but still it's hard to predict it perfectly and slight change of random seed should change generated numbers completely
In some problems(maybe not in todays one) it's possible to make a test against several seeds in the same time.
That's kinda sad :(. So instead of ctime it's better use chrono clocks?
Yep, more precision clock more unpredictable it is (because you have more possibilities for a seed)
For solutions with such a trivial seed generation (including mine, which does srand(time(NULL))) following approach should be good enough to kill them:
Take n = 11, k = 10. Pick 10s time window that you are aiming at. Now you can cover all 10 seeds from that window: for each step they can generate at most 10 different values of the guess performed, and your choice of n and k allows you to pick any of 11 positions every time.
Ok. I wrote "maybe not in todays one" because I didn't read the statement:)
Div1B should not allowed hack..
On the contrary, it is an opportunity to learn how to prevent the randomness being hackable.
At least the condition "AI is not aware that you are trying to catch the train, so it makes all moves according to its predefined plan" is given, I think hack someone's code is contradict with those condition.
But as you mentioned, on the contrary, I learned it is okay to use time(0) in CodeForces.(Some online judge prevents time(0) as restricted system call T_T)
It just means that AI's strategy is not adaptive during the execution.
I haven't seen a judge like that yet, though I doubt that they have hacks in this case. If they don't, then you can use srand(SOMERANDOMNUMBERYOUTYPE) and it will be fine.
http://codeforces.com/blog/entry/61670
I write some articles about today's anti randseed hacks. Please give your oppinion.
P.S Why so many negative on my comment ㅜ_ㅜ
Best typing/hacking/luck-based contest ever <3
Problem D was quite nice though :)
in Div2D we cannot answer for sure. so if this contest had hacking phase all of ACCEPTED submissions for Div2D would be hacked!(of course some of them got hacked in this round!)
i think it wasn't good problem because we can't be sure about the result of our submission.
You can't be sure, but you have like 10 - 12 probability to fail on a particular test.
The hacks were because people used fixed seeds, instead of seeding with time(0).
I don't think problems that have a probabilistic solution are a good idea. I didn't code the solution because I had no guarantee that it can pass all possible inputs. Am I correct in saying that there exists some input for each solution such that it will fail on that?
I don't think it's good to be outside of your house, because a lightning can strike you.
Both events are pretty unprobable, so we usually ignore them.
Regarding the input, there isn't, because if you use the current system time as a seed, then you will get different queries for each run.
I used to think that in contests like these, a solution exists for every problem such that the probability of it getting accepted is 1. Guess I was wrong.
It's never 1. There is always a non zero chance for a bit flip caused by an error in the physical hardware that's running the judging machines (background radiation, heat, etc. occasionally cause these). So even in "typical" CodeForces tasks the "correct" solution has a non zero chance of failing the tests. It's just a ridiculously small chance. Same thing with this Div2D.
A simple google result Probailty of getting hit by lighteing showed probability of getting hit by lightening is 1 in 700,000 while here it is 1 in 40. Don't write bad analogical approach.
What's 1 in 40?
When I estimated the probability of my solution being incorrect, I used a rough estimate of (49 / 50)4000 which is 8.022371·10 - 36. Looks good to me...
The numbers are from "if the current segment is of length 50 or less, pick a random point in it; otherwise, do a binary search step". OK, 4000 points is a bit exaggerated, but 2500 are a sure thing.
You can have 1 in 50 chance of failing by one random guess, and you can have like 1/4 of your queries be a random guess on a segment of length 50, so the probability of not finding the train is,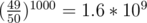 , which is even smaller than your lightning probability.
, which is even smaller than your lightning probability.
Even I had the same doubt.
I know, a silly question, but...what was the trick for getting good time complexity in Div2C?
I know, a silly question, but...what was the trick for understanding in Div2C?
more than 10 times asked several question, they tried hard too, but I was unable to understand and after all... :(
Why late System Testing? it's midnight in my region....
It's 4am in Japan.
In Div2C my approach (which got WA on pretest 8) was as follows:
First of all, if the distinct values of x's are k values, then x array should be in the form of k groups (each group consists of consecutive elements), where each group from x[i] to x[i+v-1] (where v is the number of elements in this group) must have the same value and x[i+k-1] must be = i+k-1, otherwise the answer is No. Also, a[i+v-1]+t+v-1 must be < a[i+v]+t (if i+v <= n), otherwise the answer is No.
Then to construct the answer, assign a[i+v-1]+t to b[i], and a[i+v-1]+t+1 to b[i+1] ....., and a[i+v-1]+t+v-1 to b[i+v-1]. What is wrong with this approach?
Maybe you can try the following testdata:
5 2
1 3 5 7 10
4 4 4 4 5
I think that your code will give "No" to this data. However you can indeed construct valid b[i]. The result by my code is "5 7 9 10 12".
Thank you for your reply.
I have should assigned a[i+1]+t to b[i] and a[i+2]+t to b[i+1] ..... and a[i+v-1]+t+1 to b[i+v-1]. So, a[i+v-1]+t+1 only is what must be < a[i+v]+t (if i+v <= n). Is this correct?
EDIT: added some missing t's.
EDIT2: If v==1 then it is enough to assign a[i]+t to b[i] and in this case a[i]+t only must be < a[i+1]+t (if i+1 <= n). It is accepted now. Thanks a lot.
But how exactly do you hack fixed seeds in this problem? I can't think of any approach.
P.S. I'm yet to solve it myself. Maybe, I would understand it myself, if I did that.
here is a detailed manual
Tasks were interesting, but hard for understanding. I think you should add 4 - 5 random people for each round and ask them to understand problem. In case they spend more than 10 minutes in undestanding, something is wrong with statement.
As I promised I skipped interactive one, it looks as mistake now :D
"Your solution is incorrect because it uses a fixed seed".
Now on the serious note.
As the author of problem Div1B/Div2D i kind of feel the need to apologize for the hack fiesta for this problem that happened during the contest.
As noted above its not very hard to see resemblance to Aim Tech Round 4. The phrase at the top was said back then by one of its authors. The comment is edited or deleted now. I still remember the phrase because it is one of the most bs things said by a contest author, if not the most.
Those solutions were undoubtedly correct, yet they did not get AC. Ultimately you probably should care more about how well you actually did in the contest and not about how well you did with your problem Div1B/Div2D WA for no reason.
In my defence: this problem was meant to be used in a standard IOI style format (and The Olympiad Of Metropolises uses this format). No one is retarded enough to do anti seed tests there.
In the round defence: it probably is still better to have a round or not to have one. One other thing to note is that this situation with hacks does not impact quality of problems, it only impacts your result. The former is arguably more important.
P.S. I do know that this post is not very well structured and might not be easy to comprehend. (.
What about "Hi, ok so to me it seems like a notorious coincidence"?
Off topic: I know that the phrase is basically a meme in Codeforces, but where does it originate from?
This
Thank you :D
The problem with Div 1B is that, not all solution that use fixed seed get hacked or failed system test.
Well, every solution which didn't use srand(), and called rand() simply failed for sure, because they must have added that hack case in systests.
The issue still stands for people using srand(GIVENNUMBER) or making up some function with using rand(), but I doubt that would be too many people. CF is like that :/
I think the situation is fine, but I don't agree with your "round defense". Being hacked makes you not solve other problems in a round.
Personally, I would prefer forbidding hacks at all in this problem. But allowing them is ok.
If you forbid hacks on a problem you might as well scream at the contestants that the solution is randomized
That's a very valid point.
"Hi, ok so to me it seems like a notorious coincidence"
I meant codeforces contest author, but wrote otherwise. The phrase was (and is) pure gold back then (it was in English).
"Being hacked makes you not solve other problems in a round".
Afaik most hacks happened closer to the end of the contest.
"The problem with Div 1B is that, not all solution that use fixed seed get hacked or failed system test."
Arguably the more correct solutions pass the better.
Note that you probably should not take advice above and use high resolution clock because your program loses debugability (i,e different runs in the same test cases produce different results) unless you use ifdefs which you have to put on separate lines, thus increasing your code side in lines. (and its kind of bending to bs rules). Seeding with the result of applying std::hash<const char*> to some string consisting of spaces mixed with tabs (afaik tab is treated the same '\t', i can be wrong) or just a long string of characters, possibly followed by some semi-correct statement about someone or his mum if you are hardcore and don't fear banhammer. Like probably the guy who read to the end of the seed string is seed hacker so it's kind of ok to call names at this point.
By the way, were the hacks to this problem added to final tests?
I'm not 100% positive but it seems to me that they were added and this is rather unfortunate given your comment.
It also reminds me of the old TopCoder story about the guy who noticed wrong solution during challenge phase and realized that he has a test which hacks both that wrong solution and his own solution; since he knew that his successful challenge is going to be added to system tests, and since the bug&test were somewhat non-trivial, he had to make a decision by guessing if his solution is likely to fail system tests anyway if he doesn't ensure that by challenging other solution :)
Now I'm wondering if there was anybody with such situation today :)
Here is one such story about TopCoder SRM 600 where I actually challenged myself.
If I remember correctly, it's not the only such case, I just had an idea how to search for mine.
And yeah, the question sometimes arises here too when hacking.
Div1A is this type of problem when you THINK that you understand the statement, but you are not sure :))
Come on, understanding it is easy — today I managed to make it 3 or even 4 times :)
It is also this type of a problem when you think "If that's how div1A looks nowadays, then I'm probably getting too old for this stuff".
I think it should not open hack in problem DIV1B/DIV2D
Because in the problem statement.
__ Note that AI is not aware that you are trying to catch the train, so it makes all moves according to its predefined plan.
If the hack is open, is it means that AI is aware we are trying to catch the train? :D
I also didn't understand why this condition is relevant. The train wouldn't teleport, would it? :))
Because this enables you to do the calculus of probability of a random choose get the train. Without this condition, would be reazonable that the jury has a program that always choose a different move.
This is not true. When you are guessing, it can't move at that point. Also, the moves are restricted by some interval. So any solution keeps all options open and keeps guessing when the train is not moving.
I think that condition just means that the grader is not adaptive. They could just have said that though :P
A good problem should have natural story or require interesting insight or algorithm. Problem A is neither. It's so hard to understand, and inventing a solution requires thinking so much whether you indeed satisfy the conditions from the statement — because the story is unnatural and you can't easily remember it. Was Russian version better? Did all testers understand the statement? Also:
In the second line print n integers b1, b2, ..., bn (1 ≤ b1 < b2 < ... < bn ≤ 3·1018). We can show that if there exists any solution, there exists a solution that satisfies such constraints on bi.
I don't think this is true. Without this condition,
4 3would be a correct answer of the second sample test (or am I wrong?). Maybe you meant just bn ≤ 3·1018 here — then the "we can show" statement is true, I believe. Of course, the condition bi < bi + 1 was given earlier in the statement, but anyway that output section didn't help in understanding the statement.Well, the original legend was in the spirit of "there is a problem, and you need to generate tests for it -- please provide the array b, such that the correct solution from (given a) and (your b) is (given x)".
Maybe this would be a better in terms of legend but we decided that it is better to change, since it has proven hard to read for onsite participants.
Regarding bi < bi + 1, yeah, it turned out to be a bit misleading, sorry for that. The requirement about b1 < ... < bn is said in legend and in this place we just meant "if there is a solution, we can make b1 and bn not very high".
Hm, for me the statement of A seems quite natural. As far as I know, nobody from the authors and translators on the olympiad had problems with understanding, although the statement was much more complicated. Then, AFAIK, the participants on the olympiad had troubles understanding the problem so we've made it much easier for CF round. Actually, the main part (about defining x) is written three times: informal, formal with words and formal with formula. What part is hard to understand?
As for the output section, yes, of course we meant the constraint bn ≤ 3·1018.
Regarding "Hm, for me the statement of A seems quite natural.", I think this is as unnatural as possible:
It is known that for an order to be valid the latest possible arrival for the bus that departs at ai is bxi
And I don't fully get the English here, but maybe it's me. I thought it means: An order is valid if something with xi is satisfied.
I believe you first define an order to be valid if b ≥ a + t, then a new re-definition "It is known that for an order to be valid ..." (quoted above), and then again the first definition. In the second of three definitions there is "...there exists such a valid order of arrivals...", which points to the first definition. That's confusing. But maybe I just don't understand the quote above at all, and it wasn't a definition (but then what did it mean?).
Giving the same definition three times doesn't necessarily help. It's ok if you say "in other words, ...". But why did you define something ( "Let's call an order of arrivals valid if" ), talk about something else, and then again "Formally, let's call a permutation ..."? It suggests that it's a new definition.
IMO, the sample explanation should help in understanding a problem (for those that do not understand). I recommend sentences like "Indeed, this permutation is valid because 1000 = b1 ≥ a2 + t = 123". I don't think the current one can help someone that is confused in the first place.
Also, for me order (2, 1, 3) means: first bus number 2, then 1, then 3. I find your version the less natural one.
I'm nitpicking here ofc. There are hundreds of worse statements. My main point is that easy problems should be very short (usually formal) or have a very natural story. I understand making things more complicated in harder problems, because those are harder to invent and to modify.
Can someone tell me why I am getting RTE on Div2 D even though I am handling the "Bad"? http://codeforces.com/contest/1040/submission/42526850
if(r-l <= k*2) ll raa = rand()%(r-l);Consider
r = lwhenk=0.Thanks a lot :)
My Div.1 pD 42522840 takes 6s on pretest during the contest, and now it's TLE @ 7s on test #8, which is included in pretest... Is it possible to request a rejudge? I think there might be some stability issues in the judge machine lol
Mine Div1D solution too. Thought 300ms to TL was very tight, but it fails on the test, which is pretest too. I hope for the rejudge :(
Now after some time it passes with 400ms away from TL ... :( 42529738
Thank you for notification, I'll look in it.
Here's the story of me solving Div1B.
And finally:
Dear Um_nik, I thought that you're a noble man and now I'm disappointed.
My condolences. Cool story though.
Certainly one of the funniest comments I've ever read on Codeforces :D
So, you are saying that todays problem has teaching value because you will now get to know how to generate random numbers?
PS: there's info about generating single numbers in Neal's blog too. You might have as well read it carefully instead of spending time to check who is in your room
Yeah, another possibility would be to look at some accepted code for the problem in AIM Tech Round 4.
Well, everybody's a Monday morning quarterback(*).
(*) Все сильны задним умом :-)
I agree that it is somewhere in gray moral area. I even thought about it for about a minute and then decided that I wasn't happy with the rules but the rules haven't changed, so it is completely fine to play by the existing rules and protect my (rightfully deserved) first place.
My blog was aimed at drawing contest authors and coordinators attention to this thing. Problem author has said that in his opinion it would be better to forbid hacks in this problem (exactly the thing I propose in my blog). Maybe it wasn't really a great idea to adopt problems to the round without authors help.
Keep telling yourself that. To me, those just sound like excuses to not being consistent with what you stand for.
Maybe I'm wrong but would not "srand(time(0))" in the beginning of the program save you from hacks?
Most likely it would but it's also possible to hack such solutions — read this thread of comments https://codeforces.com/blog/entry/54008?#comment-380923.
time() returns number in seconds so you can determine several seeds corresponding to several seconds after you send the hack and play against them. Of course, it's more troublesome for the hacker than just hack plain rand().
How about srand(some weird hash of the input)? That way, when you try to play against the seed, the seed will also play against you.
Great idea, I will remember it for the next problem with randomized solution :)
When you are about to become red, but it turns out, that on C the pretests didn't have n < k, so you fail system tests on that.
BTW why wasn’t there a pretest with small n and large k? It seems rather obvious case.
If it's rather obvious then why didn't you test for it lol
Max tests are obvious, prople still get TLE/RE...
Codeforces isn’t a no feedback platform, so generally you dom’t have to test your own solution if it passes pretests, because pretests should include all the trivial cases.
I'm sorry that my comment looks like "the blue is teaching the orange" but because I also used to be the orange in the past I think I can afford that :)
Hahaha. You have to test your solution even in ACM ICPC otherwise you'll get too many penalty attempts.
Alright, here we go again.
There was already a huge discussion about how strong pretests should be after GreenGrape's round. I will just quote my opinion written here again:
"What you don't understand is that not giving full feedback during a contest is a feature, not a bug. It is what sets Codeforces apart from other "well established contests" such as IOI or ICPC and what makes it so interesting."
Moreover, here's the link to the official rules: https://codeforces.com/blog/entry/456. Quote: "4. And now comes the time when you solved the problem and submitted it. It will be checked only on preliminary testset (also we call such tests "pretests"). It is known that pretests do not check solution completely. Usually there are 2-10 pretests, and the fact that the solution passed pretests says only that it is quite reasonable. Typically pretests not contain the maximal tests, corner cases, etc."
I wonder if the day will finally come when people will stop expecting maximal tests, corner cases etc. in the pretests.
That thing you quoted is 8 years old, which sounds pretty outdated.
People expect those, because 90% of the time they are included, especially in the harder problems.
As far as I know, and as I imagine, pretests aren't a feature, they are the result of the uncapibility of testing on so many tests during the round.
Your understanding is incorrect and I'm sorry about that.
What was your solution like? I can't understand why n < k would mess anything up.
For example, I pre-calculated 2i for 0 ≤ i ≤ n. It should have been 0 ≤ i ≤ max(n, k).
I did the same. Lost 100 rating just because wrote <= n instead of <= maxN...
LOL I'm pissed too. But like tbh I don't think I would have caught this bug even if my solution had failed pretests. This kind of bug is very hard to spot (for me at least).
I spotted it in like 5 minutes after I failed on systest. I was pretty damn sure about my approach, so I knew I'm looking for sth stupid like a modulo error, or something like this.
For anyone wondering about 1040E - Network Safety:
Let's fix x and find out how many subsets A of vertices are "safe" to inject with x. Take some connected set of edges such that every edge (i, j) in it connects vertices having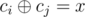 . Let's say you infected vertex v in that subgraph, then its key becomes identical to its subgraph neighbours' keys (if v has ci and the adjacent one has cj, then by subgraph definition v gets
. Let's say you infected vertex v in that subgraph, then its key becomes identical to its subgraph neighbours' keys (if v has ci and the adjacent one has cj, then by subgraph definition v gets  ). Therefore, to remain safe, you absolutely have to infect its neighbours as well. To remain safe in turn again, you'll have to infect neighbours' neighbours, then neighbours' neighbours' neighbours and so on.
). Therefore, to remain safe, you absolutely have to infect its neighbours as well. To remain safe in turn again, you'll have to infect neighbours' neighbours, then neighbours' neighbours' neighbours and so on.
Turns out, for that subgraph there are only two safe options: infect all vertices or none. Let's find all such subgraphs and denote their sizes s1, ..., sp. So if for a fixed x total number of possible infection scenarios is 2N (two choices for each vertex), the number of safe scenarios is Px = 2N - (s1 - 1) - (s2 - 1) - ... - (spx - 1) (two choices for each subgraph and two choices for each of the remaining vertices). Thus, the solution is: initialize the answer with the total number of possible scenarios (it is 2N + k), then find all such edge-subgraphs, group them by x, and for each group subtract Px from the answer.
Implementation: note that each edge is a member of exactly one edge-subgraph. Then, use disjoint set union to determine edge-subgraphs: for that we'll need a fast method to determine if there is an incident edge with the same value, e.g.
value, e.g. 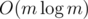 . Now we have the subgraphs as sets of edges, but there is still some effort needed to get numbers of vertices in them: for instance, can be done using another n
. Now we have the subgraphs as sets of edges, but there is still some effort needed to get numbers of vertices in them: for instance, can be done using another n  . These sizes then need to be added up (using e.g.
. These sizes then need to be added up (using e.g.
std::setfor each vertex. That's instd::sets instd::map) to be plugged into Px later. The last step is to compute the answer and subtract Px-es from it.42530262
You can also make your life somewhat easier by noticing that your Px can be written as 2C, where C is number of components in your graph; like you already wrote in your comment, for each component you should make a decision about either picking all vertices from it or none of them.
After applying that observation to formula you don't need to care about sizes anymore.
It's a pity that there wasn't a single anti-test for
unordered_mapandunordered_setfans in problem Div1C. Luckily, I managed to hack such solutions which were compiled with C++17, but there are still no tests for C++11 and C++14.As for me, the standard behavior of
unordered_mapis considered to be dangerous unless you take some measures about making its hash function non-deterministic or very complicated. So it would be reasonable to add such general tests, like anti-random tests for solutions on Div1B which userand().Adding anti unordered structure test is plain retarded, unless you want to battle things like you did by adding it to pretests. In the Olympiad of Mertopolises it wasn't a problem.
I also wouldn't include that, but is it more retarded than failing hashes modulo 264?
Slightly. In theory, I could tolerate Toi-Morse (mb I misspelled) in problems where fast hashes allow an asymptotically incorrect solution to pass. Toi-Morse is always a bad thing. No exceptions. But sometimes you have to compromise. Of course if there is a Toi-Morse string in the closed part of tests it automatically falls into plain retarded category.
Edit: by "fast" i meant fast in pratice (i,e hashes modulo 2^64 are fast in practice and by, for example, 2 primes close to 10^9 are not) as noted below. I kind of thought it was obvious from the context.
Slow hashes (while speaking about polynomial hashes, as we're speaking about Thue–Morse sequences) have precisely the same asymptotics.
Edit: I misunderstood the author's exact point as noted in his edit.
Alright, now I see why my solution to this problem 977F - Consecutive Subsequence got TL36 when I initially decided to use unordered_map.
Can you please point me to the code implementing std::hash<> which you apparently use to create hacks? I couldn't immediately find it.
Also what was the reason that you were only hacking solutions compiled with C++17 and not C++11 or C++14?
Well, you can see the code for GCC standard hash functions, for example, here. As we learn from it, the hash of an integer is the integer itself casted into unsigned int. So, providing you know the number of buckets of unordered_map on a maximal test, you can easily generate a test where all numbers fall into very few buckets (bucket index is just
key % buckets_countfor GCC, it also can be easily found in source code).And I didn't hack solutions in C++11 and C++14, because the only solution in my room that used unordered_map was compiled with C++17 :) C++11 compiler uses another formula for increasing buckets count, and it is necessary to generate another test against unordered_map in C++11.
There were tests against
unordered_mapin 1039C - Network Safety? My solution 42519546 have time limit verdict on GNU C++17, but have accepted 42530870 on GNU C++14. Or who can explain why this happened?As you may see right above your comment, greencis made a hack against unordered_map on C++17 so it was added in final tests.
Was there a rejudge on Div1B? I got TLE on system test 96 but now it's Accepted.
Concerning the hacking of Div1B and other problems whose intended solution is randomized, I believe that hacks should not be allowed, but this information should not be disclosed in the statement, or anywhere else. Just when someone locks their solution intending to hack, the platform prevents him from doing that, silently. In this way, you don't advertise that the intended solution is randomized, you avoid the creation of anti-seed hacks, and you harm nobody, as the people who have locked their problem cannot be hacked.
For me running into something like this for the first time would be a real WTF?! moment.
Having this kind of rule would require you to significantly change your strategy: some obvious examples are about locking cheap problem when you aren't 100% sure about your solution just because you are quite sure that you can get a bunch of hacks there (and you are worried about other person in your room getting them), or about using information about successful hacks on particular problem to figure out how strong pretests are there.
I can also see a lot of space for cheating encouragement there — things like reaching out somebody to get that information, or having second account to be used for situations like this.
Alright, sorry, I usually don't hack a lot, and I had not considered the other advantages that having an open hacking for a problem has.
However, it is supposed in the spirit of sportsmanship that you don't send a solution you are not sure of. (Yeah, I'm being a little naive.) But well, I see your point about getting a bunch of hacks and getting info about the strength of the cases.
Finally, allowing hacking is way a more powerful cheating encouragement. If you don't allow hacking for a certain problem, you are only hinting at a randomized solution. If you allow hacking for a problem, you can get the whole solution for a problem, which you can communicate to somebody else, or implement in a second account.
I think whenever C is 1750 instead of 1500, it turns out to be more difficult than D and very badly scored.
OK I'm so confused right now in problem D.
It's my first time solving a randomized algorithm problem.
So when putting the margin for starting randomization as 40, I'm getting WA. 42532354
When putting the margin as 50, It's getting AC. 42532464
Any clear explanation as to why this is happening?
Yes, if k = 10, it is almost impossible that you arrive to a point where l - r = 40, and it is outright impossible for l - r < 40. Indeed, when you do the binary search with l - r = u, for the next iteration lnext - rnext = (l - r) / 2 + 2 * k. Notice that if l - r ≥ 42 and k = 10, lnext - rnext > 40. So if you start randomization in 40, you won't randomize a lot of times. If you allow 50, the randomization will be way more frequent.
My code for 1040C - Timetable passes majority of the test cases except for 3 test cases 15,29,40, which have "No" as output. Can someone help me in explaining the mistake in my code? Thanks.
Here is my submission: 42532248
So, let me summarize.
Great contest, guys! I can feel rounds on codeforces becoming better and better!
Anti randseed/unordered map testcases were created by hacking participants, I suppose. The main question is "Why should you add such nonsense into systests?". However, authors just want to make it fair for everyone, the community is just retarded =)
On a more serious note, the sad aspect of the round is D. Staff claims to have known Radewoosh's problem and decoded to deal with it like this. It's just unavoidable that some coincidences remain unnoticed till the contest, there are simply too many resources nowadays
Hello! My compiler stopped working just before the contest so I used ideone.com to compile my code but forgot to change the visibility of the code and I just got a message saying I have code similar to another user vbbvaddd79506.
I want to report vbbvaddd79506 as he as cheated in this round.
I can prove that he has copied my code because of the macros. I have been using those macros for many months now, this can be verified with my submissions in the previous rounds. This is not the end of the story. You can also see that he has submitted many solutions for the Div2. B problem and those solutions are very different from each other and he has resubmitted each of them within 2 minutes of each other with totally different macros and logic.
He has been doing this since the last 2-3 rounds. I request you to please look into this and please give me a pass this time and not block my account.
Just thought of a quick & clever way to avoid fixed seed hacks:
Unfortunately, I didn't have time to code Div1B, so I haven't tested this strategy. So what do you think? I doubt someone would take the time to manually type a 10000-length string during the contest.
This was done in the contest, and discuseed here.
LOL,only 7 people solved div2-c, btw, is virtual participation rated?
No, virtual contests are only for practice — they're unrated.
Seemed like solutions for Div 1B get rejudged. Can any coordinator explain about this?
I wonder what the full input of testcase 138 in Div1B is. This testcase specifically kills random_device users, isn't it......?
Sample code with random_device: http://codeforces.com/contest/1039/submission/42539354
When I use mt19937_64, it works well.
Only substituting mt19937_64 for random_device: http://codeforces.com/contest/1039/submission/42539386
Or does random_device have any bad feature I don't know?
ouch
Seems like tests for C are extremely weak. My accepted solution 42516001 has complexity O(N2) on tests like star.
Can anyone explain how to approach and solve Div 2 Problem D ?
XD
You can literally comment anything and get plenty of upvotes, can't you?
no tutorial ?