


You can download my codes to all problems here.
I will write a full editorial in the next few days. Now you can read hints and short solutions.
750B - New Year and North Pole
750E - New Year and Old Subsequence
 . What should be stored in such a tree?
. What should be stored in such a tree?750F - New Year and Finding Roots
Also, the solution description of this problem is split into parts hidden in ,,spoiler'' tags. At any moment you can stop reading and try to finish the solution on your own.
750G - New Year and Binary Tree Paths
750H - New Year and Snowy Grid
750A - New Year and Hurry
Do you see what is produced by the following piece of code?
int total = 0;
for(int i = 1; i <= n; ++i) {
total += 5 * i;
printf("%d\n", total);
}
We iterate over problems (a variable i denotes the index of problem) and in a variable total we store the total time needed to solve them. The code above would print numbers 5, 15, 30, 50, ... — the i-th of these numbers is the number of minutes the hero would spend to solve easiest i problems.
Inside the loop you should also check if there is enough time to make it to the party, i.e. check if total + k <= 240.
simple C++ code:24067296
shorter but harder C++ code: 24067301
python: 24067479
750B - New Year and North Pole
Our goal is to simulate Limak's journey and to check if he doesn't make any forbidden moves. To track his position, it's enough to store one variable denoting his current distance from the North Pole. To solve this problem, you should implement checking three conditions given in the statement.
Updating dist_from_north variable is an easy part. Moving ti kilometers to the North increases the distance from the North Pole by ti, while moving South decreases that distance by ti. Moving to the West or East doesn't affect the distance from Poles, though you should still check if it doesn't happen when Limak is on one of two Poles — you must print "NO" in this case.
Let's proceed to checking the three conditions. First, Limak can't move further to the North if he is already on the North Pole "at any moment of time (before any of the instructions or while performing one of them)". So you should print "NO" if direction == "North" and either dist_from_north == 0 or dist_from_north < t[i]. The latter case happens e.g. if Limak is 150 kilometers from the North Pole and is supposed to move 170 kilometers to the North — after 150 kilometers he would reach the North Pole and couldn't move further to the North. In the intended solution below you will see an alternative implementation: after updating the value of dist_from_north we can check if dist_from_north < 0 — it would mean that Limak tried to move North from the North Pole. Also, you should print "NO" if dist_from_north == 0 (i.e. Limak is on the North Pole) and the direction is West or East.
You should deal with the South Pole case in a similar way. Limak is on the South Pole when dist_from_north == M.
Finally, you must check if Limak finished on the North Pole, i.e. dist_from_north == 0.
There were two common doubts about this problem: 1) "Limak is allowed to move 40 000 kilometers to the South from the North Pole and will be again on the North Pole." 2) "Moving West/East may change the latitude (equivalently: the distance from Poles) and this problem is hard 3d geometry problem." Both doubts make sense because they come from misinterpreting a problem as: Limak looks in the direction represented by the given string (e.g. to the North) and just goes straight in that direction (maybe after some time he will start moving to the South but he doesn't care about it). What organizers meant is that Limak should be directed in the given direction at any moment of time, i.e. he should continuously move in that direction. It's a sad thing that many participants struggled with that. I should have written the statement better and I'm sorry about it.
C++ code: 24067685
python code: 24067669
750C - New Year and Rating
We don't know the initial or final rating but we can use the given rating changes to draw a plot of function representing Limak's rating. For each contest we also know in which division Limak was.
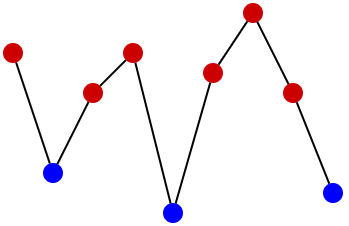
Red and blue points denote contests in div1 and div2. Note that we still don't know exact rating at any moment.
Let's say that a border is a horizontal line at height 1900. Points above the border and exactly on it should be red, while points below should be blue. Fixing the placement of the border will give us the answer (because then we will know height of all points). Let's find the highest blue point and the lowest red point — the border can lie anywhere between them, i.e. anywhere between these two horizontal lines:
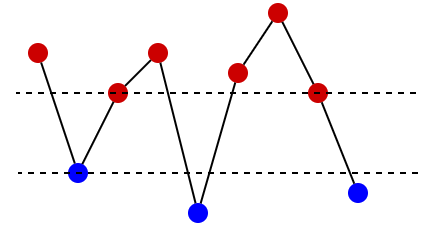
Small detail: the border can lie exactly on the upper line (because rating 1900 belongs to div1) but it can't lie exactly on the lower line (because 1900 doesn't belong to div2).
The last step is to decide where exactly it's best to put the border. The answer will be 1900 + d where d is the difference between the height of the border and the height of the last point (representing the last contest), so we should place the border as low as possible: just over the lower of two horizontal lines we found. It means that the highest blue point should be at height 1899.
There is an alternative explanation. If Limak never had rating exactly 1899, we could increase his rating at the beginning by 1 (thus moving up the whole plot of the function by 1) and everything would still be fine, while the answer increased.
To implement this solution, you should find prefix sums of rating changes (what represents the height of points on drawings above, for a moment assuming that the first point has height 0) and compute two values: the smallest prefix sum ending in a div1 contest and the greatest prefix sum ending in a div2 contest. If the first value is less than or equal to the second value, you should print "Impossible" — it means that the highest blue point isn't lower that the lowest red point. If all contests were in div1, we should print "Infinity" because there is no upper limit for Limak's rating at any time (and there is no upper limit for the placement of the border). Otherwise we say that the highest blue point (a div2 contest with the greatest prefix sum) is a contest when Limak had rating 1899 and we easily compute the final rating.
O(n) code in C++: 24069564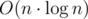 code in C++, with binary search: 24069586
code in C++, with binary search: 24069586
750D - New Year and Fireworks
A trivial O(2n) solution is to simulate the whole process and mark visited cells. Thanks to a low constraint for ti, a backtrack with memoization has much better complexity. Let's understand the reason.
Parts of the firework move by ti in the i-th level of recursion so they can't reach cells further than  from the starting cell. That sum can't exceed n·max_t = 150. We can't visit cells with bigger coordinates so there are only O((n·max_t)2) cells we can visit.
from the starting cell. That sum can't exceed n·max_t = 150. We can't visit cells with bigger coordinates so there are only O((n·max_t)2) cells we can visit.
As usually in backtracks with memoization, for every state we can do computations only once — let's think what that "state" is. We can't say that a state is defined by the current cell only, because maybe before we visited it going in a different direction and now we would reach new cells. It also isn't correct to say that we can skip further simulation if we've already been in this cell going in the same direction, because maybe it was the different level of recursion (so now next step will in in a different direction, what can allow us to visit new cells). It turns out that a state must be defined by four values: two coordinates, a direction and a level of recursion (there are 8 possible directions). One way to implement this approach is to create set<vector<int>> visitedStates where each vector contains four values that represent a state.
The complexity is 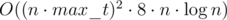 what is enough to get AC. It isn't hard to get rid of the logarithm factor what you can see in the last code below.
what is enough to get AC. It isn't hard to get rid of the logarithm factor what you can see in the last code below.
If implementing the simulation part is hard for you, see the first code below with too slow exponential solution. It shows an easy way to deal with 8 directions and changing the direction by 45 degrees — you can spend a moment to hardcode changes of x and y for each direction and clockwise or counter-clockwise order and then keep an integer variable and change its value by 1 modulo 8. You can add memoization to this slow code yourself and try to get AC.
too slow O(2n) approach (TLE): 24070543
the same code with memoization (AC): 24070548
faster memoization without logarithm (AC): 24070567
750E - New Year and Old Subsequence
It's often helpful to think about an algorithm to solve some easier problem. To check if a string has a subsequence "2017", we can find the find the first '2', then to the right from that place find the first '0', then first '1', then first '7'. If in some of these 4 steps we can't find the needed digit on the right, the string doesn't have "2017" as a subsequence. To additionally check if there is a subsequence "2016", after finding '1' (before finding '7') we should check if there is any '6' on the right. Let's refer to this algorithm as Algo.
It turns out that the problem can be solved with a segment tree (btw. the solution will also allow for queries changing some digits). The difficulty is to choose what we want to store in its nodes. Let's first use the Algo to answer simpler queries: "for the given segment check if it's nice".
There is only one thing that matters for segments represented by nodes. For a segment we want to know for every prefix of "2017" (e.g. for "20"): assuming that the Algo already got this prefix as a subsequence, what is the prefix we have after the Algo processes this segment. Let's see an example.
TODO
750F - New Year and Finding Roots

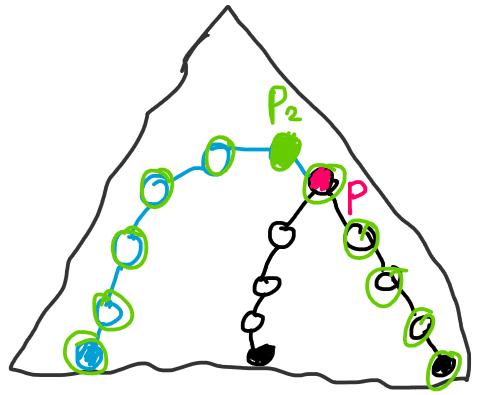
 . The limit from the statement is
. The limit from the statement is 
750G - New Year and Binary Tree Paths
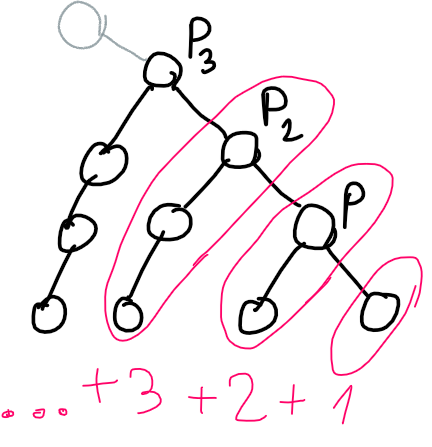
Iterate over L and R — the length of sides of a path. A "side" is a part from LCA (the highest point of a path) to one of the ends of a path.
For fixed LCA and length of sides, let the "minimal" path denote a path with the minimum possible sum of values. In each of the sides, this path goes to the left child all the time:
If the LCA is x, the smallest possible sum of vertices on the left side of the minimal path has the sum of vertices:
We can find a similar formula for the minimum possible sum of the right side SR. For fixed L, R, x, the total sum of any path (also counting LCA itself) is at least:
From this, with binary search or just a division, we can compute the largest x where this formula doesn't exceed the given s. This is the only possible value of LCA. Larger x would result with the sum exceeding s. Smaller x would result in too small sum, even if a path goes to the right child all the time (so, the sum is maximized). Proof: every vertex is strictly smaller than the corresponding vertex in the "minimal" path for the computed largest possible x:
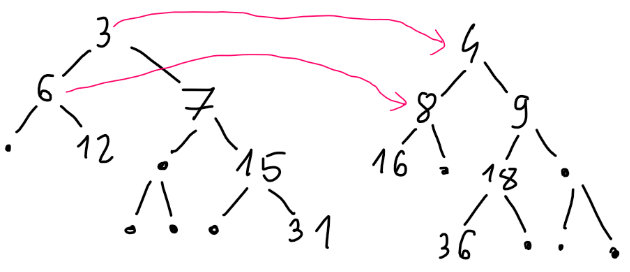
So, from L and R we can get the value of LCA.
Let's assume that the computed value of LCA is 1. For any other value we know that the value of vertex on depth k would be greater by (x - 1)·2k compared to LCA equal to 1, and we know depths of all vertices on a path, so we can subtract the sum of those differences from s, and assume the LCA is 1.
The sum of vertices from 1 to a is 2·a - popcount(a). Proof: if the binary representation of a has 1 on the i-th position from the right, there will be 1 on the (i - 1)-th position in the index of the parent of a and so on. So this bit adds 2i + 2i - 1 + ... + 1 = 2i + 1 - 1 = 2·2i - 1, so everything is doubled, and we get "-1" the number of times equal to the number of 1's in the binary representation of a. Thus, the formula is 2·a - popcount(a).
If endpoints are a and b, the sum of vertices will be 2·a - popcount(a) + 2·b - popcount(b) - 1 (we subtract the LCA that was counted twice). Since popcounts are small, we can iterate over each of them and we know the left value of equation:
Here, s' is equal to the initial s minus whatever we subtracted when changing LCA from the binary-searched x to 1.
The remaining problem is: Given binary lengths L and R of numbers a and b, their popcounts, and the sum a + b, find the number of such pairs (a, b). This can be solved in standard dynamic programming on digits.
To slightly improve the complexity, we can iterate over the sum popcount(a) + popcount(b) instead of the two popcounts separately. The required complexity is 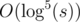 or better.
or better.
750H - New Year and Snowy Grid
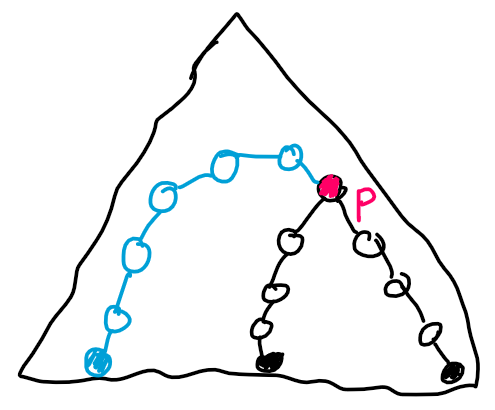
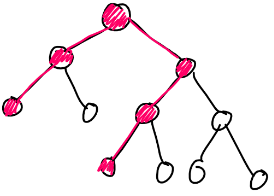
Let's solve an easier problem first. For every query, we just want to say if Limak can get from one corner to the other. He can't do that if and only if blocked cells connect the top-right side with the bottom-left side — this is called a dual problem.
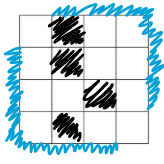
On the drawing above, the top-right side and bottom-left side are marked with blue, and blocked cells are black. There is a path of blocked cells between the two sides what means that Limak can't get from top-left to bottom-right corner. The duality in graphs changes the definition of adjacency from "sharing a side" to "touching by a corner or side" — the black cells on the drawing aren't side-adjacent but they still block Limak from passing through. Similarly, if Limak was allowed to move to any of 8 corner/side-adjacent cells, black cells would have to touch by sides to block Limak from passing through.
The idea of a solution is to find CC's (connected components) of blocked cells before reading queries, and then for every query see what CC's are connected with each other by temporarily blocked cells. To make our life easier, let's treat the blue sides as blocked cells too by expanding the grid by 1 in every direction. Then for every query, we want to check if new blocked cells connect the bottom-left CC and top-right CC.
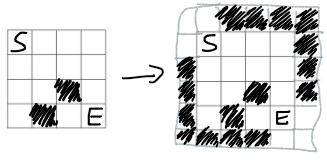
Before reading queries, we can find CC's of blocked cells (remember that a cell has 8 adjacent cells now!). Let's name those initial CC's as regions. When a temporarily blocked cell appears, we iterate through the adjacent cells and if some of them belong to initial regions, we apply find&union to mark some regions as connected to each other (and connected to this new cell that is a temporary region of size 1). This can be done in 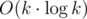 where k is the number of temporarily blocked cells. This solves the easier version of a problem, where we just check if Limak can get from one corner to the other — if the two special regions are connected at the end then the answer is "NO", and it's "YES" otherwise.
where k is the number of temporarily blocked cells. This solves the easier version of a problem, where we just check if Limak can get from one corner to the other — if the two special regions are connected at the end then the answer is "NO", and it's "YES" otherwise.
What about the full problem? Limak wants to move to the opposite corner and back, not using the same cell twice. If you treat a grid as a graph, this means checking if there is a cycle passing through the two corners (a cycle without repeated vertices). It's reasonable to then think about bridges and articulation points. An articulation point here would be such a cell that making it blocked would disconnect the two corners from each other — it's a cell that Limak must go through on both parts of his journey. Our dual problem becomes: check if the two sides are almost connected i.e. it's enough to add one more blocked cell to make the connection (that cell must be an articulation point). The previously described solution needs some modification.
We did F&U on regions adjacent to temporarily blocked cells. If some region was connected with some other region in the current query, let's call it an interesting region — there are O(k) of them. If we preprocess the set of pairs of regions that are initially almost connected (it's enough to add one more blocked cell to make them connected), we can then for a query iterate over pairs: a region connected to the bottom-right side and a region connected to the other side, and check if this pair is in the set of almost-connected regions. There are O(k2) pairs and if any of them is almost-connected, we have an almost-connection between the two sides and we print "NO", because Limak can't avoid revisiting cells.
My code: 50164800.








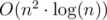 .
.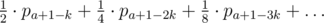 .
.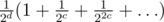 where
where 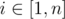 let's keep the distance to the next power of 42. After each "add on the interval" we should find the minimum and check if it's positive. If not then we should change value of the closest power of
let's keep the distance to the next power of 42. After each "add on the interval" we should find the minimum and check if it's positive. If not then we should change value of the closest power of 
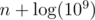 . Changing one coefficient affects up to
. Changing one coefficient affects up to 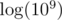 consecutive bits there and we want to get a sequence with only
consecutive bits there and we want to get a sequence with only 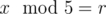 (and at the end we want at least
(and at the end we want at least 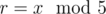 ). At the same time, we should keep people in
). At the same time, we should keep people in 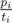 and it doesn't depend on a constant
and it doesn't depend on a constant 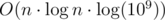 or faster. Can you solve the problem in linear time?
or faster. Can you solve the problem in linear time?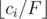 . Then, check if the max flow in this graph is at least
. Then, check if the max flow in this graph is at least 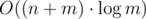 where
where 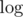 is from using set of forbidden edges.
is from using set of forbidden edges. but you could get AC with very fast solution with extra
but you could get AC with very fast solution with extra 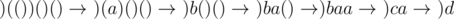
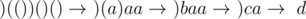


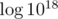 values to consider because we don't care about numbers much larger than
values to consider because we don't care about numbers much larger than  . The answer will be equal to the sum of values of
. The answer will be equal to the sum of values of  . Creating an additional array with prefix sums will allow us to calculate such a sum in
. Creating an additional array with prefix sums will allow us to calculate such a sum in 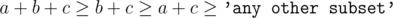 .
.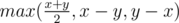 . The explanation isn't complicated. We can't be faster than
. The explanation isn't complicated. We can't be faster than 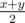 because we fight at most two criminals in each hour. And maybe e.g.
because we fight at most two criminals in each hour. And maybe e.g. 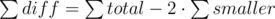 where every sum denotes the sum over
where every sum denotes the sum over 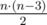 possible divisions.
possible divisions.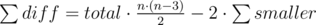
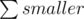 and then we will get
and then we will get 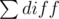 (this is what we're looking for).
(this is what we're looking for).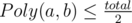 .
.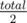 then we should increase
then we should increase 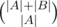 ways to divide numbers into two groups. For fixed division of numbers and for fixed position of the smallest number in
ways to divide numbers into two groups. For fixed division of numbers and for fixed position of the smallest number in 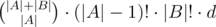 for all
for all  so it's enough to add
so it's enough to add 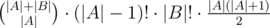 to the result. There is
to the result. There is 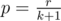 . Don't be misled by words "simple to calculate". It took me literally weeks to solve this problem and I don't say that it is easy to find the formula above.
. Don't be misled by words "simple to calculate". It took me literally weeks to solve this problem and I don't say that it is easy to find the formula above.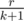 . You can find my code above.
. You can find my code above.